[转帖]GPT4All 一个开源 ChatGPT
https://zhuanlan.zhihu.com/p/618947904 通用预训练语言模型.
ChatGPT 正在迅速发展与传播,新的大型语言模型 (LLM) 正在以越来越快的速度开发。就在过去几个月,有了颠覆性的 ChatGPT 和现在的 GPT-4。明确定义,GPT 代表(Generative Pre-trained Transformer),是底层语言模型,而 ChatGPT是为会话设计的具体实现。比尔·盖茨 (Bill Gates) 回顾 OpenAI 的工作时说,“人工智能时代已经开始”。如果感到难以跟上快速变化的步伐,那么并不孤单。就在刚才,超过 1000 名研究人员签署了一份请愿书,要求在未来六个月内暂停训练比 GPT-4 更强大的 AI 系统。
尽管技术成就显着,但它们仍然是闭门造车。尽管它的名字,OpenAI 长期以来一直受到一些人的批评,因为它没有发布他们的模型,甚至被一些人称为 ClosedAI。研究人员和爱好者都在努力寻找开源替代品。
如果错过了最近的发展,应该看看 Meta 的 LLaMA ( GitHub ),它应该优于 GPT-3。它是在 GNU 许可下获得许可的,虽然它不是严格开源的,但可以在注册后获得权重。这种开放显然是为了 LLaMA 的利益,社区很快就继续开发它。它很快以 llama.cpp 的形式移植到 C/C++,斯坦福大学的研究人员将其扩展到一个指令跟随模型,例如 ChatGPT,并将其命名为 Alpaca。还有 GPT4All,这篇博文是关于它的。
首先,来反思一下社区在短时间内开发开放版本的速度有多快。为了了解这些技术的变革性,下面是各个 GitHub 仓库的 GitHub 星数。作为参考,流行的 PyTorch 框架在六年内收集了大约 65,000 颗星。下面的图表是大约一个月。
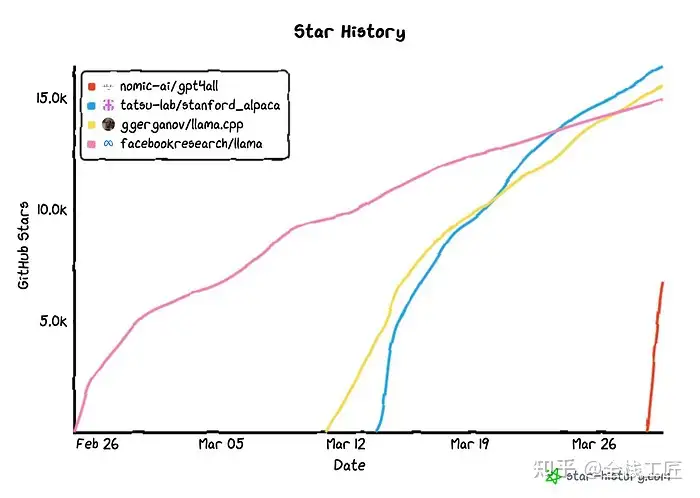
GPT4All
但现在,来更深入地介绍 GPT4All。这是 Nomic AI 的助手式聊天机器人,刚刚公开发布。
如何基于现有的语言模型(如 LLaMA)创建类似 ChatGPT 的助手式聊天机器人?答案可能会大吃一惊:与聊天机器人互动并尝试了解它的行为。就 gpt4all 而言,这意味着从公开可用的数据源收集各种问题和提示样本,然后将它们交给 ChatGPT(更具体地说是 GPT-3.5-Turbo)以生成 806,199 个高质量的提示生成对。接下来,整理数据并删除低多样性响应,并确保数据涵盖广泛的主题。训练数据后,发现他们的模型比同类产品表现更好。
对我来说,其中一个主要吸引力在于作者发布了模型的量化 4 位版本。这是什么意思?实际上,在模型中以降低的精度而不是全精度执行某些操作,因此可以拥有更紧凑的模型。虽然像 ChatGPT 这样的模型在 Nvidia 的 A100 等专用硬件上运行,这是一款配备高达 80 GB RAM 的硬件怪兽,价格为 15,000 美元,但对于 GPT4All,意味着可以在消费级硬件上执行该模型。
设置
运行 GPT4All 的说明很简单,只要安装了正在运行的 Python,按照 GitHub 存储库上的设置说明进行操作即可。
- 下载量化检查点(请参阅自己尝试),大概是
4.2 Gb的大小,完全下载需要一定的时间 - 克隆环境
- 将检查点复制到 chat
- 设置环境并安装请求
- 运行
在 M1 MacBook Pro 上对此进行了测试,这意味着只需导航到 chat- 文件夹并执行 ./gpt4all-lora-quantized-OSX-m1。
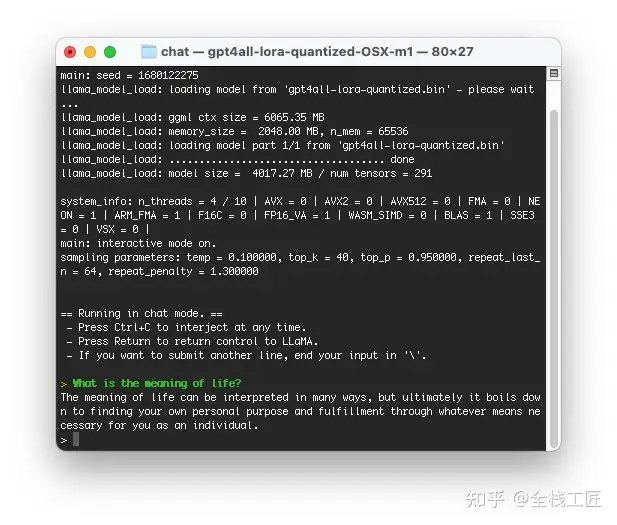
设置一切应该需要几分钟,下载是最慢的部分,结果是实时返回的。
结果
现在,准备运行的 GPT4All 量化模型在基准测试时表现如何?虽然有详尽的基准测试集,但以下是可以预期的一些快速见解:

虽然有一些明显的错误(NLP -> NLU),但实际上对输出感到非常惊讶。
可以尝试一些更有创意的东西,比如诗歌:

发现这确实非常有用,同样,考虑到这是在 MacBook Pro 笔记本电脑上运行的。虽然它可能不在 GPT-3.5 甚至 GPT-4 级别,但它肯定有一些魔力。
注意事项
使用 GPT4All 时,请牢记作者的使用注意事项:
GPT4All 模型重量和数据仅用于研究目的并获得许可,禁止任何商业用途。GPT4All 基于 LLaMA,具有非商业许可。辅助数据是从 OpenAI 的 GPT-3.5-Turbo 收集的,其使用条款禁止开发与 OpenAI 进行商业竞争的模型。
此外,请注意 ChatGPT 具有多项安全功能。
总结
开源项目和社区努力在实施技术和加速创意方面非常强大。GPT4All 就是一个显着的体现。从根本上说,这为闭源模型的业务方面提供了一个有趣的视角。如果提供 AI 作为服务,那么需要多长时间才能让爱好者对 AI 进行足够长的探索以能够模仿它?对于 GPT4All 的案例,论文中有一个有趣的注释:花了四天的时间,GPU 成本 800 美元,OpenAI API 调用 500 美元,这具有足够的吸引力。
关于文件 gpt4all-lora-quantized.bin 的下载问题,可以通过下面的链接下载:
[转帖]GPT4All 一个开源 ChatGPT的更多相关文章
- MindMup 是一个开源的、在线的、简单的思维导图工具
MindMup是一个开源.在线的思维导图工具:它有以下特点: 开源 在线 导图可存放在网站(公有,要是在不同的终端浏览的话需要记住导图的网址)或google driver(私有),无用户名密码 很方便 ...
- 分享一个开源的流程图绘制软件--Diagram Designer
最近在写专利文件,在制作说明书附图时想到自己还只会用wps进行简单的绘制,于是想学习下,填补下这方面的短板.这两天查到了DiagramDesigner这个小工具,派上了大用场.用它写完了一个发明专利, ...
- 【Hades】ades是一个开源库,基于JPA和Spring构建,通过减少开发工作量显著的改进了数据访问层的实现
几乎每个应用系统都需要通过访问数据来完成工作.要想使用领域设计方法,你就需要为实体类定义和构建资源库来实现领域对象的持久化.目前开发人员经常使用JPA来实现持久化库.JPA让持久化变得非常容易,但是仍 ...
- Tornado的一个开源社区
https://link.zhihu.com/?target=http%3A//www.tornadoweb.org/en/stable/ 基于Tornado的一个开源社区 GitHub - shiy ...
- Amoeba是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项目
http://www.cnblogs.com/xiaocen/p/3736095.html amoeba实现mysql读写分离 application shang 2年前 (2013-03-28) ...
- OpenSceneGraph是一个开源的三维引擎
http://www.osgchina.org/OpenSceneGraph是一个开源的三维引擎,被广泛的应用在可视化仿真.游戏.虚拟现实.科学计算.三维重建.地理信息.太空探索.石油矿产等领域.OS ...
- 怎样在Github参与一个开源项目
转载:http://www.csdn.net/article/2014-04-14/2819293-Contributing-to-Open-Source-on-GitHub 最近一年开源项目特别的热 ...
- WEKA,一个开源java的数据挖掘工具
开始研究WEKA,一个开源java的数据挖掘工具. HS沉寂这么多天,谁知道偏偏在我申请离职的时候给我安排了个任务,哎,无语. 于是,今天看了一天的Weka. 主要是看了HS提供的三个文章(E文,在g ...
- Nutch 是一个开源Java 实现的搜索引擎
Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting,他同时也是Lucene.Hado ...
- SSDB是一个开源的高性能数据库服务器
SSDB是一个开源的高性能数据库服务器, 使用Google LevelDB作为存储引擎, 支持T级别的数据, 同时支持类似Redis中的zset和hash等数据结构, 在同时需求高性能和大数据的条件下 ...
随机推荐
- Luogu P4592 [TJOI2018]异或 做题记录
随机跳的. 树上维护序列,显然树剖.维护异或,显然 01trie. 01trie 维护区间异或,显然可持久化一下. 看到时限很大,显然可以双 log. 于是跑一边树剖,再根据 id 暴力建一个 可持久 ...
- [活动(深圳)] .NET Love AI 之 .NET Conf China 2023 Party 深圳
中国.NET 社区2023年12月16日 在北京成功举办了.NET Conf China 2023,虽然北京飘起雪,依然挡不住想要参加活动的全国各地的.NET开发兄弟姐妹的热情.大家可以通过大会精彩照 ...
- 自定义Graph Component:1.1-JiebaTokenizer具体实现
JiebaTokenizer类继承自Tokenizer类,而Tokenizer类又继承自GraphComponent类,GraphComponent类继承自ABC类(抽象基类).本文使用<使 ...
- LeetCode LRU缓存机制
146. LRU缓存机制 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- 多模态AI开发套件HiLens Kit:超强算力彰显云上实力
摘要:Huawei HiLens Kit是一款端云协同多模态AI开发套件,支持图像.视频.语音等多种数据分析与推理计算,可广泛用于智能监控.智能家庭.机器人.无人机.智慧工业.智慧门店等分析场景. 在 ...
- 鲲鹏BoostKit虚拟化使能套件,让数据加密更安全
摘要:借助华为鲲鹏BoostKit虚拟化使能套件(简称鲲鹏BoostKit虚拟化),可加速迈向云计算之旅.本次KAE加速引擎让数据加密更安全直播将介绍鲲鹏BoostKit加速库全景,基于BoostKi ...
- 火山引擎工具技术分享:用 AI 完成数据挖掘,零门槛完成 SQL 撰写
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 文 / DataWind 团队封声 在使用 BI 工具的时候,经常遇到的问题是:"不会 SQL 怎么生产加工 ...
- Solon 1.6.34 发布,更现代感的应用开发框架
相对于 Spring Boot 和 Spring Cloud 的项目 启动快 5 - 10 倍 qps 高 2- 3 倍 运行时内存节省 1/3 ~ 1/2 打包可以缩小到 1/2 ~ 1/10(比如 ...
- .Net Core EF 日志打印 SQL 语句
Startup.cs public class Startup { public static readonly ILoggerFactory efLogger = LoggerFactory.Cre ...
- 你正在调试XXX的发布版本,如果在启用 仅我的代码 的同时,使用通过编译器优化的发布版本
仅我的代码"警告 你正在调试 XXX.dll 的发布版本.如果在启用"仅我的代码"的同时使用通过编译器优化的发布版本,调试体验会降级(例如,将不会命中断点) 停止调试禁用 ...