Nebula Graph 源码解读系列 | Vol.04 基于 RBO 的 Optimizer 实现

上篇我们讲述了一个执行计划是如何生成的,这次我们来看下这个生成的执行计划是被 Optimizer 优化的。
概述
Optimizer,优化器,顾名思义就是一个用来优化执行计划的组件。数据库的优化器通常分为两类,一类是基于规则的优化器 RBO(Rule-basd optimizer),一类是基于代价的优化 CBO(Cost-based optimizer),前者完全基于预设的优化规则进行优化,匹配的条件和优化的结果都比较固定;后者则会根据收集的数据统计信息计算不同执行计划的执行代价,尽量选择代价最小的执行计划。
目前 Nebula Graph 主要实现得是 RBO,所以本文也主要集中讲述 Nebula Graph 中的 RBO 实现。
源码定位
优化器的源码实现都在src/optimizer目录下面,其中的文件结构如下所示:
.
├── CMakeLists.txt
├── OptContext.cpp
├── OptContext.h
├── OptGroup.cpp
├── OptGroup.h
├── Optimizer.cpp
├── Optimizer.h
├── OptimizerUtils.cpp
├── OptimizerUtils.h
├── OptRule.cpp
├── OptRule.h
├── rule
│ ├── CombineFilterRule.cpp
│ ├── CombineFilterRule.h
│ ├── EdgeIndexFullScanRule.cpp
│ ├── EdgeIndexFullScanRule.h
| ....
|
└── test
├── CMakeLists.txt
├── IndexBoundValueTest.cpp
└── IndexScanRuleTest.cpp
其中test目录是测试,rule目录则是预设的规则集,其他的源文件则是优化器的具体实现。
而优化器优化查询的入口则在src/service/QueryInstance.cpp文件中,如下所示:
Status QueryInstance::validateAndOptimize() {
auto *rctx = qctx()->rctx();
VLOG(1) << "Parsing query: " << rctx->query();
auto result = GQLParser(qctx()).parse(rctx->query());
NG_RETURN_IF_ERROR(result);
sentence_ = std::move(result).value();
NG_RETURN_IF_ERROR(Validator::validate(sentence_.get(), qctx()));
NG_RETURN_IF_ERROR(findBestPlan());
return Status::OK();
}
findBestPlan函数会调用优化器,优化并返回一个全新的优化过的执行计划。
优化过程简述
Nebula Graph 目前设计的执行计划从拓扑角度来讲是一个有向无环图,通过每个节点指向它的依赖节点来组织,理论上每个节点可以指定任意节点的结果作为输入,但是使用一个还没执行的节点的结果是没有意义的,所以在生成执行计划的时候会限制只能使用已经执行过的节点作为输入。同时,执行计划也执行循环和条件分支这样的特殊节点。如图1 所示,该执行计划由查询语句GO 2 STEPS FROM 'Tim Duncan' OVER like产生。
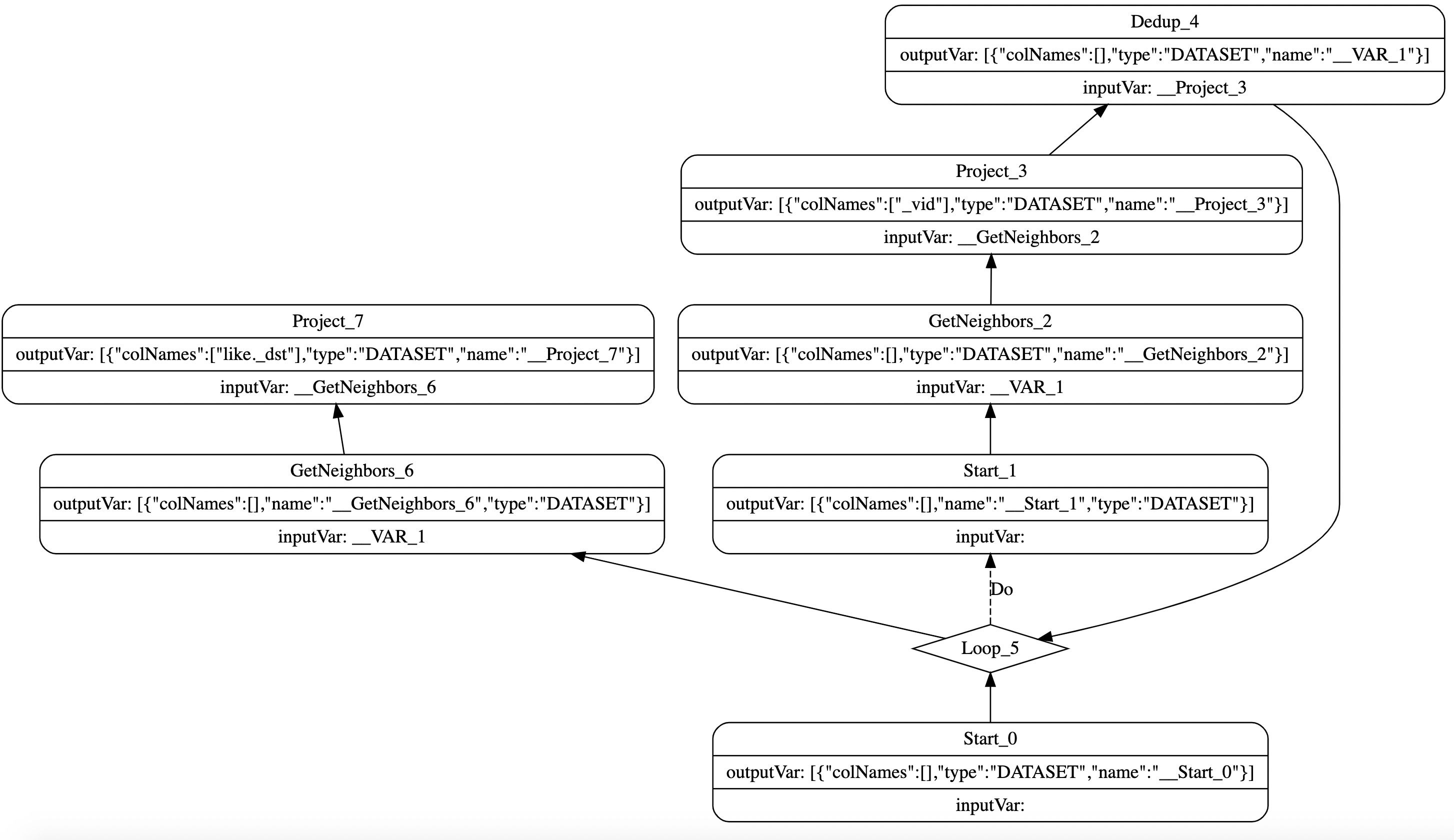
图1
优化器目前的主要功能就是根据预设模式在执行计划中进行匹配,如果匹配成功,再调用相应的转换函数将匹配到的部分执行计划按预设的规则进行转换。比如,将 GetNeighbor → Limit 形式的执行计划转换成 limit 下推的GetNeighbor算子,实现算子下推优化。
具体实现
首先,优化器不会直接在执行计划上操作,而是先将执行执行计划转换成OptGroup、OptGroupNode。OptGroup 代表的是一个单独的优化组(通常指一个或多个同等的算子),OptGroupNode 则是代表一个独立的算子,同时还有指向依赖以及分支的指针,也就是说OptGroupNode 保留了执行计划的拓扑结构。之所以要做这样的结构转换,主要是抽象出执行计划的拓扑结构,屏蔽掉一些不需要执行细节(比如循环和条件分支),以及在新的结构中方便保存一些规则匹配的上下文。
转换过程基本上是一个简单的先序遍历,并在遍历的过程中把算子转换成对应的OptGroup以及OptGroupNode。为了方便描述,这里把OptGroup以及OptGroupNode组成的结构称为优化计划,和执行计划做区分。
转换完成后就会开始匹配规则以及做相应的优化计划转换。这里会遍历所有预定义的规则,而每个规则都会在在优化计划上做一个 Bottom-Up 的遍历匹配,具体来说就是从最叶子层OptGroup开始,一直到根节点的OptGroup,在每个OptGroup节点上对节点内的OptGroupNode做 Top-Down 的遍历来进行规则模式的匹配。
如图2 所示,这里要匹配的模式是Limit->Project→GetNeighbors,按照 Bottom-Up 的顺序,首先在Start节点按照 Top-Down 的顺序匹配,Start不等于Limit匹配失败,然后从GetNeighbors开始同样 Top-Down 匹配失败,直到Limit开始才匹配成功。匹配成功后,会根据规则定义的transform函数,将匹配到的部分优化计划进行转换,比如图2 会将Limit和GetNeighbors合并。
![]()
图2
最后,优化器会把已经完成优化的优化计划重新转换成执行计划,这里和第一步相反,不过也是一个递归遍历转换的过程。
如何添加新规则
在前面的文章中,我们了解整个优化器组件的实现部分,不过对于添加优化规则来说并不需要了解太多优化器的实现细节,只需要了解如何定义新规则即可。这里,我们以Limit下推为例讲解一个典型的优化规则的实现。Limit下推规则的源码详见src/optimizer/rule/LimitPushDownRule.cpp文件:
std::unique_ptr<OptRule> LimitPushDownRule::kInstance =
std::unique_ptr<LimitPushDownRule>(new LimitPushDownRule());
LimitPushDownRule::LimitPushDownRule() {
RuleSet::QueryRules().addRule(this);
}
const Pattern &LimitPushDownRule::pattern() const {
static Pattern pattern =
Pattern::create(graph::PlanNode::Kind::kLimit,
{Pattern::create(graph::PlanNode::Kind::kProject,
{Pattern::create(graph::PlanNode::Kind::kGetNeighbors)})});
return pattern;
}
StatusOr<OptRule::TransformResult> LimitPushDownRule::transform(
OptContext *octx,
const MatchedResult &matched) const {
auto limitGroupNode = matched.node;
auto projGroupNode = matched.dependencies.front().node;
auto gnGroupNode = matched.dependencies.front().dependencies.front().node;
const auto limit = static_cast<const Limit *>(limitGroupNode->node());
const auto proj = static_cast<const Project *>(projGroupNode->node());
const auto gn = static_cast<const GetNeighbors *>(gnGroupNode->node());
int64_t limitRows = limit->offset() + limit->count();
if (gn->limit() >= 0 && limitRows >= gn->limit()) {
return TransformResult::noTransform();
}
auto newLimit = static_cast<Limit *>(limit->clone());
auto newLimitGroupNode = OptGroupNode::create(octx, newLimit, limitGroupNode->group());
auto newProj = static_cast<Project *>(proj->clone());
auto newProjGroup = OptGroup::create(octx);
auto newProjGroupNode = newProjGroup->makeGroupNode(newProj);
auto newGn = static_cast<GetNeighbors *>(gn->clone());
newGn->setLimit(limitRows);
auto newGnGroup = OptGroup::create(octx);
auto newGnGroupNode = newGnGroup->makeGroupNode(newGn);
newLimitGroupNode->dependsOn(newProjGroup);
newProjGroupNode->dependsOn(newGnGroup);
for (auto dep : gnGroupNode->dependencies()) {
newGnGroupNode->dependsOn(dep);
}
TransformResult result;
result.eraseAll = true;
result.newGroupNodes.emplace_back(newLimitGroupNode);
return result;
}
std::string LimitPushDownRule::toString() const {
return "LimitPushDownRule";
}
定义一个规则首先先继承OptRule类。然后,实现pattern接口,这里要求返回需要匹配的模式,模式是算子和算子的依赖组成,比如Limit->Project->GetNeighbors。然后需要实现transform接口,transform接口会传入一个匹配的优化计划,我们根据预定义的模式来解析匹配到的优化计划,并对优化计划做相应的优化转换,比如把Limit算子合并到GetNeighbors算子,最后返回优化过的优化计划计划即可。
只需要正确实现这两个接口,我们的新的优化规则就可以正常工作了。
以上,为 Nebula Graph Optimizer 的介绍。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
【活动】Nebula Hackathon 2021 进行中,一起来探索未知,领取 ¥ 150,000 奖金 →→ https://nebula-graph.com.cn/hackathon/
Nebula Graph 源码解读系列 | Vol.04 基于 RBO 的 Optimizer 实现的更多相关文章
- 新手阅读 Nebula Graph 源码的姿势
摘要:在本文中,我们将通过数据流快速学习 Nebula Graph,以用户在客户端输入一条 nGQL 语句 SHOW SPACES 为例,使用 GDB 追踪语句输入时 Nebula Graph 是怎么 ...
- Alamofire源码解读系列(二)之错误处理(AFError)
本篇主要讲解Alamofire中错误的处理机制 前言 在开发中,往往最容易被忽略的内容就是对错误的处理.有经验的开发者,能够对自己写的每行代码负责,而且非常清楚自己写的代码在什么时候会出现异常,这样就 ...
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
本篇讲解参数编码的内容 前言 我们在开发中发的每一个请求都是通过URLRequest来进行封装的,可以通过一个URL生成URLRequest.那么如果我有一个参数字典,这个参数字典又是如何从客户端传递 ...
- Alamofire源码解读系列(三)之通知处理(Notification)
本篇讲解swift中通知的用法 前言 通知作为传递事件和数据的载体,在使用中是不受限制的.由于忘记移除某个通知的监听,会造成很多潜在的问题,这些问题在测试中是很难被发现的.但这不是我们这篇文章探讨的主 ...
- Alamofire源码解读系列(五)之结果封装(Result)
本篇讲解Result的封装 前言 有时候,我们会根据现实中的事物来对程序中的某个业务关系进行抽象,这句话很难理解.在Alamofire中,使用Response来描述请求后的结果.我们都知道Alamof ...
- Alamofire源码解读系列(六)之Task代理(TaskDelegate)
本篇介绍Task代理(TaskDelegate.swift) 前言 我相信可能有80%的同学使用AFNetworking或者Alamofire处理网络事件,并且这两个框架都提供了丰富的功能,我也相信很 ...
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager) 本篇主要讲解iOS开发中的网络监控 前言 在开发中,有时候我们需要获取这些信息: 手机是否联网 ...
- Alamofire源码解读系列(八)之安全策略(ServerTrustPolicy)
本篇主要讲解Alamofire中安全验证代码 前言 作为开发人员,理解HTTPS的原理和应用算是一项基本技能.HTTPS目前来说是非常安全的,但仍然有大量的公司还在使用HTTP.其实HTTPS也并不是 ...
- Alamofire源码解读系列(九)之响应封装(Response)
本篇主要带来Alamofire中Response的解读 前言 在每篇文章的前言部分,我都会把我认为的本篇最重要的内容提前讲一下.我更想同大家分享这些顶级框架在设计和编码层次究竟有哪些过人的地方?当然, ...
- Alamofire源码解读系列(十)之序列化(ResponseSerialization)
本篇主要讲解Alamofire中如何把服务器返回的数据序列化 前言 和前边的文章不同, 在这一篇中,我想从程序的设计层次上解读ResponseSerialization这个文件.更直观的去探讨该功能是 ...
随机推荐
- 学习MySQL,创建表,数据类型
连接本地mysql语句 mysql -hlocalhost -uroot -proot MySQL通用语法 DDL数据库操作 DDL:数据定义语言,用来定义数据库对象(数据库,表,字段) 查询所有数据 ...
- elementUI自定义单选框内容
<template> <div> <div class="heng-div"> <el-radio v-model="radio ...
- 【记录一个问题】VictoriaMetrics的vmstorage因为慢查询导致大量写入失败
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 见上图. 一直以为vmstorage中的查询协程会让位于写 ...
- Gorm 入门介绍与基本使用
Gorm 入门介绍与基本使用 目录 Gorm 入门介绍与基本使用 一.ORM简介 1.1 什么是ORM 1.2 使用ORM的好处 1.2.1 避免直接操作SQL语句 1.2.2 提高代码的可维护性 1 ...
- 不同版本的Unity要求的NDK版本和两者对应关系表(Unity NDK Version Match)
IL2CPP需要NDK Unity使用IL2CPP模式出安卓包时,需要用到NDK,如果没有安装则无法导出Android Studio工程或直接生成APK,本篇记录一下我下载NDK不同版本的填坑过程. ...
- MySQL【五】与python交互
1.安装pymysql 安装pymysql pip install pymysql 2.游标(cursor)的使用 cursor,就是一个标识,用来标识数据可以理解成数组中的下标 . 一.声明一个游 ...
- Python Selenium 库使用技巧
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE,Mozilla Firefox,Safari,Google ...
- 全流程机器视觉工程开发(三)任务前瞻 - 从opencv的安装编译说起,到图像增强和分割
前言 最近开始做这个裂缝识别的任务了,大大小小的问题我已经摸得差不多了,然后关于识别任务和分割任务我现在也弄的差不多了. 现在开始做正式的业务,也就是我们说的裂缝识别的任务.作为前言,先来说说场景: ...
- 在K8S中,节点故障驱逐pod过程时间怎么定义?
在Kubernetes中,节点故障驱逐Pod的过程涉及多个参数和组件的相互作用.以下是该过程的简要概述: 默认设置:在默认配置下,节点故障时,工作负载的调度周期约为6分钟. 关键参数: node-mo ...
- 从零搭建Vue3 + Typescript + Pinia + Vite + Tailwind CSS + Element Plus开发脚手架
项目代码以上传至码云,项目地址:https://gitee.com/breezefaith/vue-ts-scaffold 目录 前言 脚手架技术栈简介 vue3 TypeScript Pinia T ...