Hadoop集群模式安装笔记
前言
Hadoop集群=HDFS集群+YARN集群
特点:两个集群逻辑上分离,通常物理上在一起;并且都是标准的主从架构集群
Hadoop安装
方式一源码编译安装
方式二官方编译安装包 ()
环境
Centos +虚拟机
集群规划
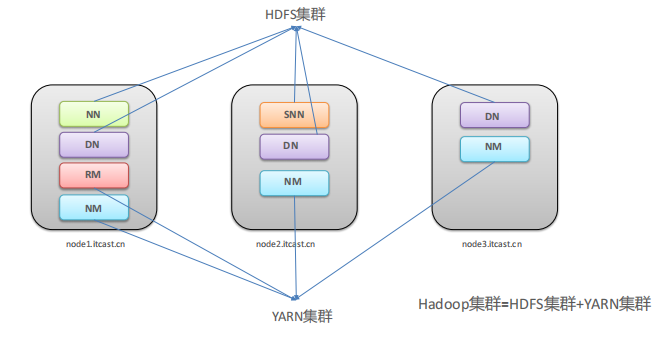
| 服务器 | 运行角色 |
|---|---|
| node1.itcast.cn | namenode datanode resourcemanager nodemanager |
| node2.itcast.cn | secondarynamenode datanode nodemanager |
| node3.itcast.cn | datanode nodemanager |
服务器环境准备
1、主机名-allservers
/* 建立服务器的主机名*/
vim /etc/hostname
添加主机名
/*验证:*/
hostname或cat /etc/hostname、
2、Hosts映射-allservers
/*建立服务器主机名和IP地址映射*/
vim /etc/hosts
添加IP地址 主机名1 主机名2..
/*验证:*/
cat /etc/hosts
3、集群时间同步-allservers
/*安装ntpdate命令*/
yum -y install ntpdate (若有可跳过)
/*同步时间*/
ntpdate ntp4.aliyun.com
4、关闭防火墙-allservers
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁用firewalld服务
5、SSH免密登录-node1
Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程可用通过SSH登录实现。
#只需要配置node1至node1、node2、node3即可
#node1生成公钥私钥--一直确认
ssh-keygen
#node1配置免密登录到node1 node2 node3
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
#验证,进行登录
ssh node1
ssh node2
ssh node3
4、创建存放路径
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/sofrware/ #安装包存放路径
5、安装JDK-allservers
JDK安装包上传至/export/server/
#解压
tar -zxvf jdk-8u241-linux-x64.tar.gz
#解压文件:jdk1.8.0_241
#解压后的文件分发同步到node2、node3,路径保持一致
scp -r /export/server/jdk1.8.0_241 root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241 root@node3:/export/server/
-------------------------------------------------------------
#配置环境变量
vim /etc/profile
#追加
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#同步分发到node2,node3
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
#重新加载环境变量文件
source /etc/profile
#验证
java -version
6、安装Hadoop-allservers
#上传Hadoop安装包到node1 /export/server
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
#解压
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
------------------------------------------------------
#修改配置文件:/hadoop-3.3.0/etc/hadoop
hadoop-env.sh
core-site.xml #核心模块配置
hdfs-site.xml #hdfs文件系统模块配置
mapred-site.xml #MapReduce模块配置
yarn-site.xml #yarn模块配置
workers
#分发同步hadoop安装包
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
------------------------------------------------------
#配置环境变量
vim /etc/profile
#追加
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#重载配置文件
source /etc/profile
#分发同步
...
#验证
hadoop
7、Hadoop集群启动
1、 首次启动HDFS之前需要format操作;format本质上是初始化工作,进行HDFS清理和准备工作
2. format只能进行一次 后续不再需要;
3. 如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别。通过删除所有机器hadoop.tmp.dir目录重新format解决
命令:hdfs namenode -format #node1,namenode进程在node1 下
验证:

Hadoop集群的启停
1、手个逐个进程启停
每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。
HDFS集群:
#hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenode
YARN集群
#hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
#hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager
2、shell脚本一键启停
一台机器上操作,集群内所有机器都会做配置
在node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和workers文件
#HDFS集群
start-dfs.sh
stop-dfs.sh
#YARN集群
start-yarn.sh
stop-yarn.sh
#Hadoop集群
start-all.sh
stop-all.sh
#验证集群启动正常
jps #显示java相关进程,查看进程是否启动
/export/server/hadoop-3.3.0/logs/*.log #查看hadoop启动日志
------------------------------------------
闪退则是配置文件出错
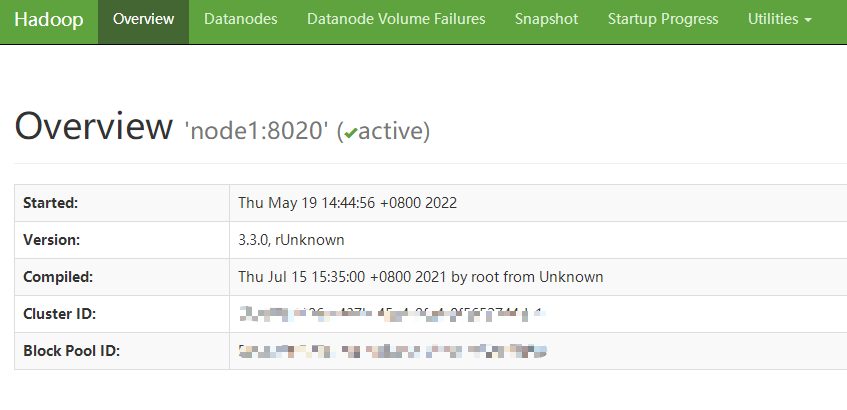
Hadoop WebUI
HDFS集群:http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
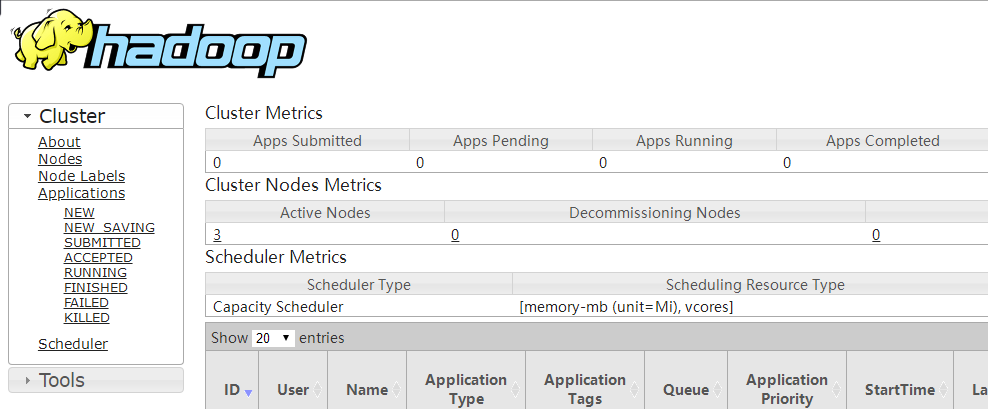
YARN集群:http://resourcemanager_host:8088
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
备注:
单机安装是本机作为集群
伪分布式安装是指在一台机器上模拟一个小的集群,但是集群只有一个节点。
完全分布式安装可用通过安装多个Linux虚拟机来实现。
Hadoop集群模式安装笔记的更多相关文章
- Presto单机/集群模式安装笔记
Presto单机/集群模式安装笔记 一.安装环境 二.安装步骤 三.集群模式安装: 3.1 集群模式修改配置部分 3.1.1 coordinator 节点配置. Node172配置 3.1.2 nod ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- Hadoop集群模式安装出现的若干问题
一.域名解析问题 域名解析暂时失败问题 vim /etc/sysconfig/network 查看主机名 vim etc/hosts 配置IP地址与主机名 192.168.60.132 centos ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
随机推荐
- unity添加Mysql的dll以及发布的问题
最近在做一个unity项目中,要读取数据库,还是MySql的数据库.遇到了很多问题,写出来供大家参考一下. 关于unity引用第三方的Mysql.data.dll的问题: 这个地方有一个难点,正常的C ...
- 解决NAT模式下SSH连接虚拟机
解决NAT模式下SSH连接虚拟机 简介: 用到的有软件:VirtualBox6.1,RetHat7.4 , SmartTTY 来由: 刚开始使用桥接模式(Bridged)网络连接,但是虚拟机没有网络. ...
- 如何使用libavcodec将.h264码流文件解码为.yuv图像序列?
一.打开和关闭输入文件和输出文件 //io_data.cpp static FILE* input_file= nullptr; static FILE* output_file= nullptr; ...
- 【Shell】ps 命令
ps 命令 Linux ps (英文全拼:process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器. 1. ps 常用的命令 ps -aux #显示所有进程信息 ...
- 基于GPT搭建私有知识库聊天机器人(三)向量数据训练
在前面的文章中,我们介绍了实现原理和基本环境安装.本文将重点介绍数据训练的流程,以及如何加载.切割.训练数据,并使用向量数据库Milvus进行数据存储. 1. 数据训练依赖于向量数据库 在本文中,我们 ...
- AMH安装Nextcloud出现Access denied
AMH部署了LAMP或者LNMP,然后常规安装Nextcloud,安装完成后跳转到首页就出现Access denied.Nextcloud的文件夹权限已经修改,可读写.http://127.0.0.1 ...
- 如何在 Ubuntu 20.04 上安装 KVM
如何在 Ubuntu 20.04 上安装 KVM 遇到两个问题: 没有创建 /etc/qemu/bridge.conf 文件 ERROR internal error: /usr/lib/qemu/q ...
- EF 管理数据库架构
本章会主要了解EF提供的独立迁移项目,用独立迁移项目自动创建dgml设计关系图和sql脚本. 迁移项目通常也叫(CodeFirst代码优先),在EF中迁移项目是在,在代码中设计数据库,每次对数据库的设 ...
- Typescript:基础语法学习(尚硅谷 李立超)
官方文档:https://www.tslang.cn/docs/handbook/typescript-in-5-minutes.html 搭建开发环境 npm i -g typescript安装完成 ...
- Pandas: 将dataframe转换为dict
背景 将Dataframe的每一列数据转换成字典并保存.也就是字段名变为key, 数值变为value. 方案 以下是效果图 参考链接 https://blog.csdn.net/hanyunkaka/ ...