Huggy Lingo: 利用机器学习改进 Hugging Face Hub 上的语言元数据
太长不看版: Hub 上有不少数据集没有语言元数据,我们用机器学习来检测其语言,并使用 librarian-bots 自动向这些数据集提 PR 以添加其语言元数据。
Hugging Face Hub 已成为社区共享机器学习模型、数据集以及应用的存储库。随着 Hub 上的数据集越来越多,元数据,作为一种能帮助用户找到所需数据集的工具,变得越来越重要。
我们很高兴能够通过本文与大家分享我们的一些早期实验,这些实验旨在利用机器学习来改进 Hugging Face Hub 上托管的数据集的元数据。
Hub 上数据集的语言元数据
目前 Hugging Face Hub 上约有 5 万个公开数据集。用户可以通过 数据集卡 顶部的 YAML 字段设定其语言元信息。
我们目前支持 1716 种语言标签,所有的公开数据集都可以在其语言元信息中指定其一。请注意,有些语言会有多个不同的语言标签,如 en 、eng 、english 、English 都是英语。
举个例子,IMDB 数据集 的 YAML 元数据中的语言标签为 en :
IMDB 数据集的 YAML 元数据部分
迄今为止,Hub 上数据集上最常见的语言是英语,有大约 19% 的数据集将其语言标注为 en (这还没把 en 的其他变体统计在内,因此实际百分比可能会比 19% 要高得多)。这个现象符合我们的预期。
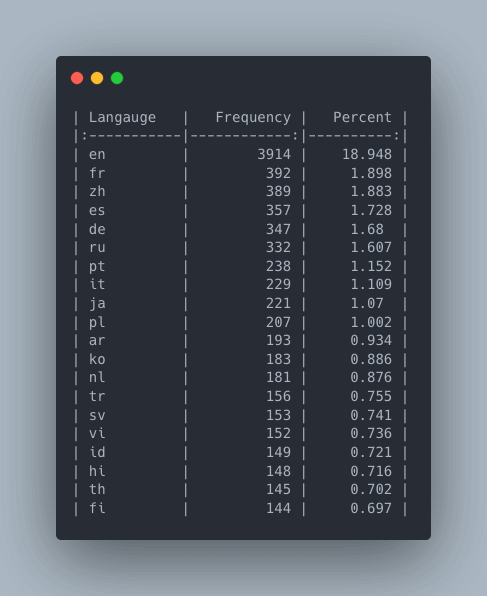
Hugging Face Hub 上的数据集的频率及占比
如果排除掉英语,语言分布又如何呢?我们可以看到,有几种语言相对占主导,随后的其他语言的频率则出现了平稳下降。
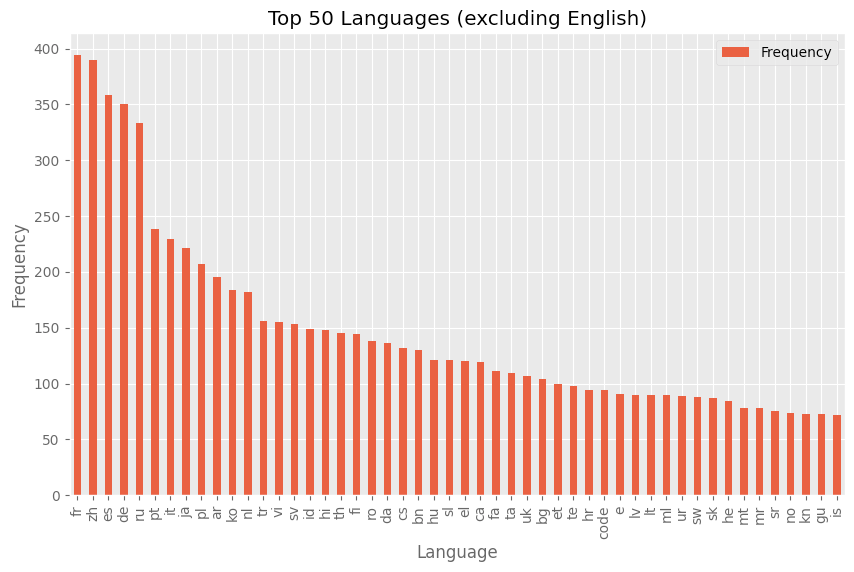
Hub 上数据集的语言标签分布情况 (除英语外)
这里,我们发现一个重大问题,那就是大多数数据集 (约 87%) 没有指明其所使用的语言,只有大约 13% 的数据集在其元数据中指明了语言信息。
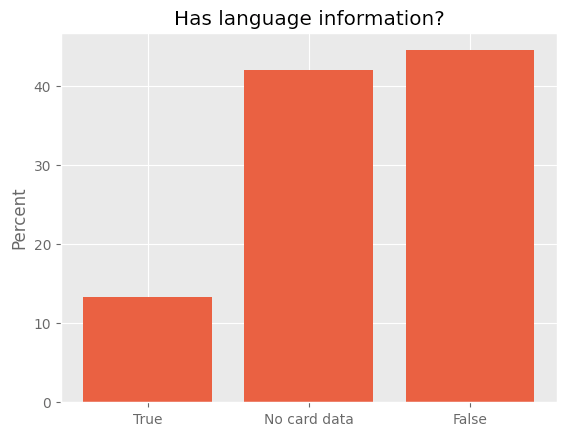
具有语言元数据的数据集占比。True 表示指明了语言元数据,False 表示未列出语言元数据。No card data 意味着没有任何元数据,抑或是`huggingface_hub` Python 库无法加载它。
为什么语言元数据很重要?
语言元数据是查找相关数据集的重要工具。Hugging Face Hub 允许用户按语言过滤数据集。例如,如果想查找荷兰语数据集,我们可以在 Hub 上用 过滤器 过滤出仅包含荷兰语的数据集。
目前,此过滤器返回 184 个数据集。但是,Hub 上其实还有别的一些数据集中包含荷兰语,但其未在元数据中指明语言,因此就很难被过滤器找到。随着 Hub 上数据集越来越多,这种现象会愈发严重。
许多人希望能够找到特定语言的数据集。而当前,为特定语言训练出优秀的开源 LLM 的主要障碍之一就是缺乏相应语言的高质量训练数据。
在为某些任务搜寻相关的机器学习模型时,了解模型的训练数据中包含哪些语言有助于我们找到能够支持我们想要的语言的模型。而这又依赖于相应的训练数据集中是否含有相关语言信息。
最后,了解 Hub 上有哪些语言 (以及没有哪些语言),有助于我们了解 Hub 在语种支持上的偏差,并为社区解决特定语言上的数据差距提供信息支持。
利用机器学习预测数据集的语言
我们已经看到 Hugging Face Hub 上的许多数据集并未包含语言元数据。然而,由于这些数据集已经公开,也许我们可以尝试利用机器学习来识别其语言。
获取数据
我们可以使用 datasets 库下载数据集并获取它的一些样本,代码如下:
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")
对于 Hub 上的某些数据集,我们可能不希望下载整个数据集。我们可以尝试加载数据集的部分样本。然而,根据数据集的创建方式不同,对某些数据集,我们最终下载到机器上的数据可能仍比我们实际需要的多。
幸运的是,Hub 上的许多数据集都可以通过 datasets server 获得。Datasets server 是一个 API,其允许我们无需下载到本地即可访问 Hub 上托管的数据集。Datasets server 已被应用于数据集查看器预览功能,Hub 上托管的许多数据集都支持数据集查看器预览功能。
为了给语言检测实验准备数据,我们首先定义了一个白名单,其中包含了可能包含文本的列名及数据类型,如名字为 text 或 prompt 的列以及数据类型为 string 的特征可能包含文本,但名字为 image 的列大概率是不相关的。这意味着我们可以避免为不相关的数据集预测其语言,例如为图像分类数据集预测语言。我们用 datasets server 获取 20 行文本数据并传给机器学习模型 (具体用多少行数据可以根据实际情况修改)。
这么做的话,我们可以对 Hub 上的大多数数据集,快速获取它们前 20 行数据的文本内容。
预测数据集的语言
获取到文本样本后,我们就需要预测其语言。这里有多种方法,目前,我们使用了由 Meta 为 “一个语言都不能少” 项目而开发的 facebook/fasttext-language-identification fastText 模型。该模型可以检测 217 种语言,这覆盖了 Hub 上托管的大多数数据集的语言。
我们将 20 个样本传给模型,由模型为每个数据集生成 20 个单独的语言预测 (每个样本一个)。
有了这些预测后,我们会进行一些额外的过滤,以决定我们是否接受这些预测作为元数据。主要步骤有:
- 对每个数据集按预测语言进行分组: 某些数据集可能会预测出多种语言。此时,我们会按预测语言对这些样本进行分组。举个例子,如果返回英语和荷兰语两种预测,我们将样本按照预测语言分成两个组。
- 分别计算每种预测语言的样本数。如果其中某种语言的样本比例低于 20%,我们就丢弃该预测。举个例子,如果我们有 18 个样本预测为英语,2 个样本预测为荷兰语,此时我们就会丢弃荷兰语预测。
- 对每种语言的预测分求平均。如果平均分低于 80%,丢弃该预测。

预测过滤流程图
一旦完成过滤,我们就需要进一步决定如何使用这些预测。fastText 语言预测模型的输出为一个 ISO 639-3 代码 (一种语言代码的国际标准) 加一个文字代码。举个例子,输出 kor_Hang 的前半部分 kor 是韩语的 ISO 693-3 语言代码,而后半部分 Hang 是韩字的 ISO 15924 代码。
我们会丢弃文字代码,因为当前 Hub 尚未将此作为元数据的一部分。同时,我们会将模型返回的 ISO 639-3 语言代码转换为 ISO 639-1。这么做主要是因为 Hub UI 的数据集导航功能对 ISO 639-3 代码的支持更好。
还有一种情况需要处理,即某些 ISO 639-3 代码并没有对应的 ISO 639-1 代码。此时,如有必要,我们会手动指定映射,例如将标准阿拉伯语 ( arb ) 映射到阿拉伯语 ( ar )。如果无法进行显式映射,我们索性就放弃配置该数据集的语言元数据。我们会在后续工作中继续改进我们的方法。我们已经意识到,当前的方法确实是有缺点的,它人为减少了语言的多样性,并依赖于对某些语言映射关系的主观判断。
我们会持续改进,但当前我们并不会因为被问题绊住而停在原地。毕竟,如果我们无法与社区其他成员共享这些信息,那么预测数据集的语言又有什么用呢?有缺陷的信息总比没有信息好。
使用 Librarian-Bot 更新元数据
为了确保将这些有价值的语言元数据上传至 Hub,我们使用了 Librarian-Bot! Librarian-Bot 会采纳 Meta 的 facebook/fasttext-language-identification fastText 模型预测的语言信息,并自动生成 PR 以将此信息添加至各数据集的元数据中。
该系统可以快速高效地更新各数据集的语言信息,无需人类手动操作。一旦数据集的所有者批准并合并相应 PR,所有用户就都可以使用该语言元数据,从而显著增强 Hugging Face Hub 的可用性。你可以在 此处 跟踪 Librarian-Bot 的一举一动!
下一步
随着 Hub 上的数据集越来越多,元数据变得越来越重要,而其中语言元数据可以帮助用户甄别出合适自己场景的数据集。
在 Datasets server 和 Librarian-Bots 的帮助下,我们可以大规模地自动更新数据集元数据,这是手动更新无法企及的。我们正在用这种方法不断丰富 Hub,进而使 Hub 成为服务世界各地的数据科学家、语言学家和人工智能爱好者的强大工具。
英文原文: https://hf.co/blog/huggy-lingo
原文作者: Daniel van Strien
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
Huggy Lingo: 利用机器学习改进 Hugging Face Hub 上的语言元数据的更多相关文章
- docker学习笔记4:利用docker hub上的mysql镜像创建mysql容器
docker hub上有官方的mysql镜像,我们可以利用它来创建mysql容器,作为一个服务容器使用. 1.下载mysql镜像 docker pull mysql 2.创建镜像 docker run ...
- 【java】工厂模式Factory,利用反射改进
package 反射; interface Product{ public void produce(); } class socks implements Product{ @Override pu ...
- Python 3 利用机器学习模型 进行手写体数字识别
0.引言 介绍了如何生成数据,提取特征,利用sklearn的几种机器学习模型建模,进行手写体数字1-9识别. 用到的四种模型: 1. LR回归模型,Logistic Regression 2. SGD ...
- Python 3 利用机器学习模型 进行手写体数字检测
0.引言 介绍了如何生成手写体数字的数据,提取特征,借助 sklearn 机器学习模型建模,进行识别手写体数字 1-9 模型的建立和测试. 用到的几种模型: 1. LR,Logistic Regres ...
- 利用机器学习检测HTTP恶意外连流量
本文通过使用机器学习算法来检测HTTP的恶意外连流量,算法通过学习恶意样本间的相似性将各个恶意家族的恶意流量聚类为不同的模板.并可以通过模板发现未知的恶意流量.实验显示算法有较好的检测率和泛化能力. ...
- 利用Docker Hub上的Nginx部署Web应用
Docker Hub上提供了很多镜像,如Nginx,我们不需要自己从ubuntu开始装Nginx再做发布,只需要先下载镜像到本地 docker pull nginx 在/opt下新建文件夹API,将需 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- win7下利用ftp实现华为路由器的上传和下载
win7下利用ftp实现华为路由器的上传和下载 1. Win7下ftp的安装和配置 (1)开始->控制面板->程序->程序和功能->打开或关闭Windows功能 (2)在Wi ...
- [.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上)
[.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上) 本节导读: 随着硬件和网络的高速发展,为多线程(Multithreading) ...
- 利用栈实现算术表达式求值(Java语言描述)
利用栈实现算术表达式求值(Java语言描述) 算术表达式求值是栈的典型应用,自己写栈,实现Java栈算术表达式求值,涉及栈,编译原理方面的知识.声明:部分代码参考自茫茫大海的专栏. 链栈的实现: pa ...
随机推荐
- 「atcoder - ABC215G」Colorful Candies 2
link. 称题目中的 \(c_i\) 为 \(a_i\),令 \(c_i\) 为第 \(i\) 种颜色的出现次数,令 \(C\) 为颜色总数.固定 \(k\),令 \(t_i=1\),如果颜色 \( ...
- C#学习笔记--变量类型的转换
变量类型的转化: 转换原则 同类型的大的可以装小的,小类型的装大的就需要强制转换. 隐式转换: 同种类型的转换: //有符号 long-->int-->short-->sbyte l ...
- Java编程之道:巧妙解决Excel公式迭代计算难题
本文由葡萄城技术团队原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 什么是迭代计算 迭代计算其实是在 Excel 中,一种公式的循环引用,对于了 ...
- Net 高级调试之二:CLR和Windows加载器及应用程序域介绍
一.简介 今天是 Net 高级调试的第二篇文章,第一篇文章记录了自己学习 Net 高级调试的第一步,认识一些调试工具,有了工具的倚仗,我们开始仗剑走天涯了,开始Net 高级调试正式的征程了.我先说一下 ...
- Jenkins-插件安装-多实例
1,Jenkins插件安装: Jenkins最大的功能莫过于插件丰富,基于各种插件可以满足各项需求,Jenkins本身是一个框架,真正发挥作用的各种插件.Jenkins默认自带很多插件,如果没有添加新 ...
- Jenkins相关概念
1,Jenkins相关工具概念: 要熟练掌握Jenkins持续集成的配置.使用和管理,需要了解相关的概念.例如代码开发.编译.打包.构建等名称,常见的代码相关概念包括:JDK.JAVA.MAKE.AN ...
- Nginx-多功能脚本
#!/bin/bash #2020年2月16日 #auto_install_nginx_web.v3 #by fly ################################ #NGX_VER ...
- 文心一言 VS 讯飞星火 VS chatgpt (123)-- 算法导论10.4 4题
四.用go语言,对于一个含 n个结点的任意有根树,写出一个 O(n)时间的过程,输出其所有关键字该树以左孩子右兄弟表示法存储. 文心一言: 在计算机科学中,左孩子右兄弟表示法是一种用于表示树状结构的方 ...
- jpa用findAll((Specification<GoodsSpu>) (root, criteriaQuery, criteriaBuilder) -> {})排序
//需要用到的包import org.springframework.data.domain.Page;import org.springframework.data.domain.PageReque ...
- js朗读实现
js 利用window实现朗读功能 ` 发音