神经网络优化篇:详解为超参数选择合适的范围(Using an appropriate scale to pick hyperparameters)
为超参数选择合适的范围

假设要选取隐藏单元的数量\(n^{[l]}\),假设,选取的取值范围是从50到100中某点,这种情况下,看到这条从50-100的数轴,可以随机在其取点,这是一个搜索特定超参数的很直观的方式。或者,如果要选取神经网络的层数,称之为字母\(L\),也许会选择层数为2到4中的某个值,接着顺着2,3,4随机均匀取样才比较合理,还可以应用网格搜索,会觉得2,3,4,这三个数值是合理的,这是在几个在考虑范围内随机均匀取值的例子,这些取值还蛮合理的,但对某些超参数而言不适用。

看看这个例子,假设在搜索超参数\(a\)(学习速率),假设怀疑其值最小是0.0001或最大是1。如果画一条从0.0001到1的数轴,沿其随机均匀取值,那90%的数值将会落在0.1到1之间,结果就是,在0.1到1之间,应用了90%的资源,而在0.0001到0.1之间,只有10%的搜索资源,这看上去不太对。
反而,用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取0.0001,0.001,0.01,0.1,1,在对数轴上均匀随机取点,这样,在0.0001到0.001之间,就会有更多的搜索资源可用,还有在0.001到0.01之间等等。
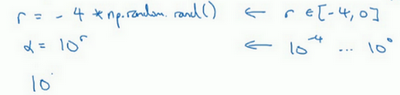
所以在Python中,可以这样做,使r=-4*np.random.rand(),然后\(a\)随机取值,$ a =10^{r}\(,所以,第一行可以得出\)r \in [ 4,0]\(,那么\)a \in[10{-4},10]$,所以最左边的数字是\(10^{-4}\),最右边是\(10^{0}\)。
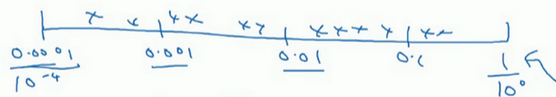
更常见的情况是,如果在\(10^{a}\)和\(10^{b}\)之间取值,在此例中,这是\(10^{a}\)(0.0001),可以通过\(\operatorname{}{0.0001}\)算出\(a\)的值,即-4,在右边的值是\(10^{b}\),可以算出\(b\)的值\(\operatorname{}1\),即0。要做的就是在\([a,b]\)区间随机均匀地给\(r\)取值,这个例子中\(r \in \lbrack - 4,0\rbrack\),然后可以设置\(a\)的值,基于随机取样的超参数\(a =10^{r}\)。
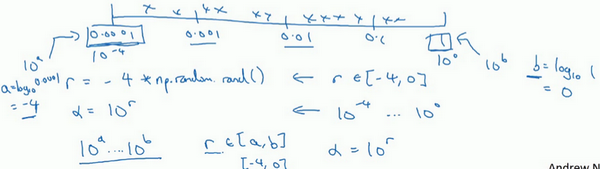
所以总结一下,在对数坐标下取值,取最小值的对数就得到\(a\)的值,取最大值的对数就得到\(b\)值,所以现在在对数轴上的\(10^{a}\)到\(10^{b}\)区间取值,在\(a\),\(b\)间随意均匀的选取\(r\)值,将超参数设置为\(10^{r}\),这就是在对数轴上取值的过程。
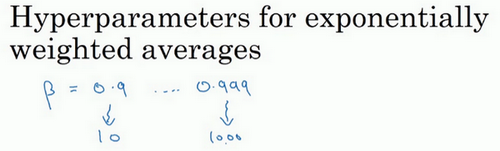
最后,另一个棘手的例子是给\(\beta\) 取值,用于计算指数的加权平均值。假设认为\(\beta\)是0.9到0.999之间的某个值,也许这就是想搜索的范围。记住这一点,当计算指数的加权平均值时,取0.9就像在10个值中计算平均值,有点类似于计算10天的温度平均值,而取0.999就是在1000个值中取平均。
所以和上面的内容类似,如果想在0.9到0.999区间搜索,那就不能用线性轴取值,对吧?不要随机均匀在此区间取值,所以考虑这个问题最好的方法就是,要探究的是\(1-\beta\),此值在0.1到0.001区间内,所以会给\(1-\beta\)取值,大概是从0.1到0.001,应用之前介绍的方法,这是\(10^{-1}\),这是\(10^{-3}\),值得注意的是,在之前的内容里,把最小值写在左边,最大值写在右边,但在这里,颠倒了大小。这里,左边的是最大值,右边的是最小值。所以要做的就是在\([-3,-1]\)里随机均匀的给r取值。设定了\(1- \beta = 10^{r}\),所以\(\beta = 1-10^{r}\),然后这就变成了在特定的选择范围内超参数随机取值。希望用这种方式得到想要的结果,在0.9到0.99区间探究的资源,和在0.99到0.999区间探究的一样多。

所以,如果想研究更多正式的数学证明,关于为什么要这样做,为什么用线性轴取值不是个好办法,这是因为当\(\beta\) 接近1时,所得结果的灵敏度会变化,即使\(\beta\)有微小的变化。所以\(\beta\) 在0.9到0.9005之间取值,无关紧要,的结果几乎不会变化。
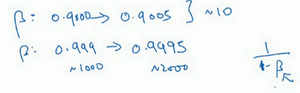
但\(\beta\)值如果在0.999到0.9995之间,这会对的算法产生巨大影响,对吧?在这两种情况下,是根据大概10个值取平均。但这里,它是指数的加权平均值,基于1000个值,现在是2000个值,因为这个公式\(\frac{1}{1- \beta}\),当\(\beta\)接近1时,\(\beta\)就会对细微的变化变得很敏感。所以整个取值过程中,需要更加密集地取值,在\(\beta\) 接近1的区间内,或者说,当\(1-\beta\) 接近于0时,这样,就可以更加有效的分布取样点,更有效率的探究可能的结果。
希望能帮助选择合适的标尺,来给超参数取值。如果没有在超参数选择中作出正确的标尺决定,别担心,即使在均匀的标尺上取值,如果数值总量较多的话,也会得到还不错的结果,尤其是应用从粗到细的搜索方法,在之后的迭代中,还是会聚焦到有用的超参数取值范围上。
神经网络优化篇:详解为超参数选择合适的范围(Using an appropriate scale to pick hyperparameters)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 详解Python函数参数定义及传参(必备参数、关键字参数、默认可省略参数、可变不定长参数、*args、**kwargs)
详解Python函数参数定义及传参(必备参数.关键字参数.默认可省略参数.可变不定长参数.*args.**kwargs) Python函数参数传参的种类 Python中函数参数定义及调用函数时传参 ...
- 命令创建.net core3.0 web应用详解(超详细教程)
原文:命令创建.net core3.0 web应用详解(超详细教程) 你是不是曾经膜拜那些敲几行代码就可以创建项目的大神,学习了命令创建项目你也可以成为大神,其实命令创建项目很简单. 1.cmd命令行 ...
- Dojo初探之2:设置dojoConfig详解,dojoConfig参数详解+Dojo中预置自定义AMD模块的四种方式(基于dojo1.11.2)
Dojo中想要加载自定义的AMD模块,需要先设置好这个模块对应的路径,模块的路径就是这个模块的唯一标识符. 一.dojoConfig参数设置详解 var dojoConfig = { baseUrl: ...
- yolo3各部分代码详解(超详细)
0.摘要 最近一段时间在学习yolo3,看了很多博客,理解了一些理论知识,但是学起来还是有些吃力,之后看了源码,才有了更进一步的理解.在这里,我不在赘述网络方面的代码,网络方面的代码比较容易理解,下面 ...
- JS-排序详解:冒泡排序、选择排序和快速排序
JS-排序详解-冒泡排序 说明 时间复杂度指的是一个算法执行所耗费的时间 空间复杂度指运行完一个程序所需内存的大小 稳定指,如果a=b,a在b的前面,排序后a仍然在b的前面 不稳定指,如果a=b,a在 ...
- Dockerfile命令详解(超全版本)
制作Dockerfile为Docker入门学习的第一步(当然,除了环境搭建). 本文收集.整理了官网关于制作Dockerfile的全部命令(除SHELL没整理,这个就不弄了),可帮助大家快速进入Doc ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
随机推荐
- 数字化转型鸿沟如何消除?ROMA Connect融合集成,联接企业应用现在与未来
摘要:ROMA Connect平台正在以"联接和融合"的方式,重塑传统企业上云的路径--"条条大路"通向云端. 本文分享自华为云社区<[大厂内参]第13期 ...
- DataLeap的全链路智能监控报警实践(二):概念介绍
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 概念介绍 基线监控 根据监控规则和任务运行情况,DataLeap的基线监控能够决策是否报警.何时报警.如何报警以及 ...
- 在毫秒量级上做到“更快”!DataTester 助力飞书提升页面秒开率
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 用户体验是决定互联网产品能否长久生存的基础,每一个基于产品功能.使用.外观的微小体验,都将极大关系到用户留存影响. ...
- PPT 工作计划PPT 应该怎么样改
收集素材 页面处理 丰富细节 PPT 工作计划PPT 应该怎么样做
- 负载均衡 SLB 健康检查异常
负载均衡 SLB 健康检查异常,接口地址不能访问 接口地址的访问首先需要健康检查状态为正常. 如果接口没有"首页",需要提供一个可访问的controller
- AudioLDM 2,加速!
AudioLDM 2 由刘濠赫等人在 AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining 一 ...
- 使用 DPO 微调 Llama 2
简介 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步 ...
- JVM学习-自动内存管理
文章原文:https://gaoyubo.cn/blogs/6997cf1f.html 一.运行时数据区 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域 ...
- drf-jwt配置文件 jwt签发认证源码分析 自定义用户签发认证 simpleui后台管理美化 权限控制 (acl、rbac)
目录 昨日回顾 接口文档 自动生成接口文档 接口文档必备的内容 cookie-session-token发展史 token原理 base64 快速签发 定制返回格式 jwt的认证 drf-jwt配置文 ...
- 服务器上TIME_WAIT过多怎么处理
正常情况下,TIME_WAIT是需要存在的 为了保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK可能丢失,从而导致处在LAST-ACK状态的服务器收不到对FIN-ACK的确认报文,服务 ...