如何选择kmeans中的k值——肘部法则–Elbow Method和轮廓系数–Silhouette Coefficient
肘部法则–Elbow Method
我们知道k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt df_features = pd.read_csv(r'11111111.csv',encoding='gbk') # 读入数据
#print(df_features)
'利用SSE选择k'
SSE = [] # 存放每次结果的误差平方和
for k in range(1,9):
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(df_features[['','','','','','','','','','','','','','','','','','','','','','','','','','','','','','','','','']])
SSE.append(estimator.inertia_) # estimator.inertia_获取聚类准则的总和
X = range(1,9)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(X,SSE,'o-')
plt.show()
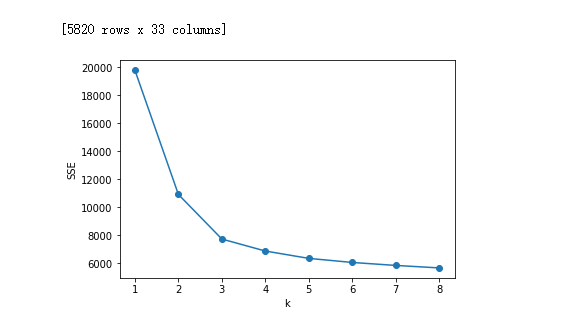
如上图所示,在k=xxxxxx时,畸变程度(y值)得到大幅改善,可以考虑选取k=xxxxx作为聚类数量 显然,肘部对于的k值为xxxxxx(曲率最高),故对于这个数据集的聚类而言,最佳聚类数应该选xxxxxxxx。
轮廓系数–Silhouette Coefficient
对于一个聚类任务,我们希望得到的簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下: s=b−amax(a,b)s=b−amax(a,b) 其中a代表同簇样本到彼此间距离的均值,b代表样本到除自身所在簇外的最近簇的样本的均值,s取值在[-1, 1]之间。 如果s接近1,代表样本所在簇合理,若s接近-1代表s更应该分到其他簇中。
判断: 轮廓系数范围在[-1,1]之间。该值越大,越合理。 si接近1,则说明样本i聚类合理; si接近-1,则说明样本i更应该分类到另外的簇; 若si 近似为0,则说明样本i在两个簇的边界上。 所有样本的s i 的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。 使用轮廓系数(silhouette coefficient)来确定,选择使系数较大所对应的k值
sklearn.metrics.silhouette_score sklearn中有对应的求轮廓系数的API
import numpy as np
from sklearn.cluster import KMeans
from pylab import *
import codecs
import matplotlib.pyplot as plt
from sklearn.metrics import calinski_harabaz_score
import pandas as pd
from numpy.random import random
from sklearn import preprocessing
from sklearn import metrics
import operator data = []
labels = []
number1=10
with codecs.open("red_nopca_nolabel.txt", "r") as f:
for line in f.readlines():
line1=line.strip()
line2 = line1.split(',')
x2 = []
for i in range(0,number1):
x1=line2[i]
x2.append(float(x1))
data.append(x2)
x2 = []
#label = line2[number1-1]
#labels.append(float(label))
datas = np.array(data)
'''
kmeans_model = KMeans(n_clusters=3, random_state=1).fit(datas)
labels = kmeans_model.labels_
a = metrics.silhouette_score(datas, labels, metric='euclidean')
print(a)
'''
silhouette_all=[] for k in range(2,25):
kmeans_model = KMeans(n_clusters=k, random_state=1).fit(datas)
labels = kmeans_model.labels_
a = metrics.silhouette_score(datas, labels, metric='euclidean')
silhouette_all.append(a)
#print(a)
print('这个是k={}次时的轮廓系数:'.format(k),a) dic={} #存放所有的互信息的键值对
mi_num=2
for i in silhouette_all:
dic['k={}时轮廓系数'.format(mi_num)]='{}'.format(i)
mi_num=mi_num+1
#print(dic)
rankdata=sorted(dic.items(),key=operator.itemgetter(1),reverse=True)
print(rankdata)
实验结果部分插图

如何选择kmeans中的k值——肘部法则–Elbow Method和轮廓系数–Silhouette Coefficient的更多相关文章
- K-means中的K值选择
关于如何选择Kmeans等聚类算法中的聚类中心个数,主要有以下方法(译自维基): 1. 最简单的方法:K≍sqrt(N/2) 2. 拐点法:把聚类结果的F-test值(类间Variance和全局Var ...
- 如何选择K-Means中K的值
K-Means需要设定一个簇心个数的参数,现实中,最常用于确定K数的方法, 其实还是人手工设定.例如,当我们决定将衣服做成几个码的时候,其实就是在以 人的衣服的长和宽为为特征进行聚类.所以,弄清楚我们 ...
- 理解KNN算法中的k值-knn算法中的k到底指的是什么 ?
2019-11-09 20:11:26为方便自己收藏学习,转载博文from:https://blog.csdn.net/llhwx/article/details/102652798 knn算法是指对 ...
- 使用肘部法确定k-means均值的k值
import numpy as np from sklearn.cluster import KMeans from scipy.spatial.distance import cdist impor ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- 选择问题(选择数组中第K小的数)
由排序问题可以引申出选择问题,选择问题就是选择并返回数组中第k小的数,如果把数组全部排好序,在返回第k小的数,也能正确返回,但是这无疑做了很多无用功,由上篇博客中提到的快速排序,稍稍修改下就可以以较小 ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- kmeans 聚类 k 值优化
kmeans 中k值一直是个令人头疼的问题,这里提出几种优化策略. 手肘法 核心思想 1. 肉眼评价聚类好坏是看每类样本是否紧凑,称之为聚合程度: 2. 类别数越大,样本划分越精细,聚合程度越高,当类 ...
随机推荐
- springboot+jpa分页(Pageable+Page)
Pageable+Page实现分页无需配置,也不需要加入jar包(maven依赖) Controller控制层 package com.gxuwz.late.controller; import co ...
- js算法(1)
数组排序 arr.sort(function compare(a,b){return b.value-a.value}); json 排序 $.getJSON('URl',function(data) ...
- destoon信息或者公司归属多个类别的解决方式
有时候,一条信息属对应于多个类别,在destoon原生系统里是没有这个解决方案 在公司行业类别选择的地方实现了这个功能,但是选择体验不太好,不符合我当前的需求,目前我写了如下解决方案 系统代码如下: ...
- Python - Tuple 怎么用,为什么有 tuple 这种设计?
背景 看到有同学很执着的用 tuple,想起自己刚学 python 时,也是很喜欢 tuple,为啥?因为以前从来没见过这种样子的数据 (1,2), 感觉很特别,用起来也挺好用 i,j=(1,2), ...
- Linux 操作虚拟机、数据库
1.打开虚拟机,输入命令:ifconfig 查看iP和端口号,端口号一般为:22 2.打开Xshell(先安装好),连接虚拟机(根据iP和端口号) 若连接成功,Xshell则会显示虚拟机的ip和端口号 ...
- 【算法随记七】巧用SIMD指令实现急速的字节流按位反转算法。
字节按位反转算法,在有些算法加密或者一些特殊的场合有着较为重要的应用,其速度也是一个非常关键的应用,比如一个byte变量a = 3,其二进制表示为00000011,进行按位反转后的结果即为110000 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十三:Eureka源码解读完结撒花篇~!
前言 想说的话 [一起学源码-微服务-Netflix Eureka]专栏到这里就已经全部结束了. 实话实说,从最开始Eureka Server和Eureka Client初始化的流程还是一脸闷逼,到现 ...
- Python用PIL将PNG图像合成gif时如果背景为透明时图像出现重影的解决办法
最近在用PIL合成PNG图像为GIF时,因为需要透明背景,所以就用putpixel的方法替换背景为透明,但是在合成GIF时,图像出现了重影,在网上查找了GIF的相关资料:GIF相关资料 其中有对GIF ...
- 现代主流框架路由原理 hash、history的底层原理
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- SQL练习题(一)
目录 题目一:交换性别(简单) 实现思路 提交代码 题目二:连续出现的数字(中等) 实现思路 方式一 方式二 提交代码 方式一 方式二 题目三:换座位(中等) 实现思路 方式一 方式二 提交代码 方式 ...