吴裕雄--天生自然HADOOP操作实验学习笔记:tf-idf算法
实验目的
通过实验了解tf-idf算法原理
通过实验了解mapreduce的更多组件
学会自定义分区,读写缓存文件
了解mapreduce程序的设计方法
实验原理
1.TF-IDF简介
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母,区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到,即:idf = log(文件总数/包含该词语的文件的数目)。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF的公式就是tf值乘以idf的值,即:tf-idf = tf * log(文件总数/包含该词语的文件的数目)。
2.TF-IDF实现
计算文章中的每个词的tf-idf值,通常有有一下几个步骤:
第一步,计算tf和文章总数。首先读入所有的文章,通过分词器分词,计算出每篇文章中每个词的频率tf,同时计算文章数。
第二步,计算每个词出现过的文章次数。只需要将第一步计算的每篇文章的每个词的频率都改成1,代表这个词在这一篇文章出现过,然后累加就是每个词出现过的文章的次数。
第三步,计算tf-idf值。
第一步计算每个词在每个文章出现的频率,第二步计算了每个词出现过的文章次数,第一步还计算了文章总数。这三个条件加在一起就可以求出每个文章中每个词的tf-idf。
3.TF-IDF应用
TF-IDF可以用来根据单词做分类,也就可以用在做需要文本分类的地方,例如我们可以结合贝叶斯公式进行文本分类。当然还可以做广告投放。
举个例子,我们要在微博上投放广告,必须针对不同人投放不同的广告。现在要选择一批广告投放汽车的广告,首先需要这个人和车有关系,我们可以分析微博得到他和是否有投放汽车广告的必要。首先通过分词器拆分微博的词,某个人的一条微博出现了三个“的”和一个“汽车”,那么词频分别为3和1,我们可以再求出所有统计的微博出现“的”和“汽车”的微博数作为逆向文件频率,用词频除以逆向文件频率就是这个词的tf-idf值。然后我们发现这条微博“汽车”的tf-idf值比较大,可以用来投放汽车广告。
4.权重
我们需要给汉语中的每一个词给一个权重,这个权重的设定必须满足下面两个条件:
一个词预测主题能力越强,权重就越大,反之,权重就越小。我们在网页中看到“原子能”这个词,或多或少地能了解网页的主题。我们看到“应用”一次,对主题基本上还是一无所知。因此,“原子能“的权重就应该比应用大。
应删除词的权重应该是零。应删除词有“的”、“是”、“和”、“中”、“地”、“得”等等几十个。
我们很容易发现,如果一个关键词只在很少的网页中出现,我们通过它就容易锁定搜索目标,它的权重也就应该大。反之如果一个词在大量网页中出现,我们看到它仍然不很清楚要找什么内容,因此它应该小。概括地讲,假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小,反之亦然。
实验环境
1.操作系统
操作机:Windows_7
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等。
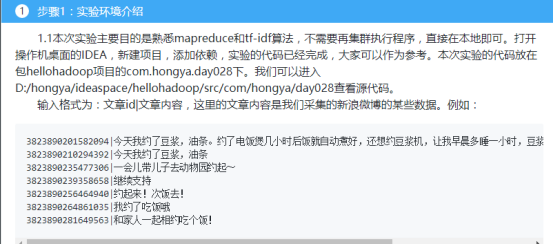
步骤2:代码编写说明
2.1第一个mapreduce,计算词频tf和文章总数。
由于要计算每个词在每一篇文章的词频,我们可以先将文章分词,然后将词和文章id组合为key,1为value写出,在reduce汇总就是所有的词频。另外我们可以每解析一个文章,以"count"字符串为key,1为value写出,在reduce汇总就是文章数。同时我们需要将文章数和词频分开处理,所以需要自定义partition,将词频和文章数的结果放在不同的reduce进行处理。
map的主要代码:
while( (word = ikSegmenter.next()) !=null ){
String w = word.getLexemeText();
//word_id -> frequency
context.write(new Text(w+"_"+id), new IntWritable(1));
}
//最后计算文章总数
context.write(new Text("count"), new IntWritable(1));
自定义partition:
// partition方法的参数为输出的key,value,reduce的个数
public int getPartition(Text key, IntWritable value, int reduceCount) {
if(key.equals(new Text("count")))
return 3;
else
return super.getPartition(key, value, reduceCount-1);
}
reduce汇总:
int sum = 0;
for( IntWritable i :values ){
sum = sum + i.get();
}
context.write(key, new IntWritable(sum));
2.2第二个mapreduce,计算每个词在多少个文章出现过。
直接取第一个mapreduce的结果中的词频部分,他的key为词和文章id的组合,value为在对应文章的词频。由于这时候每个词和文章id组合值出现一次,所以我们直接以词为key,1为value写出,reduce汇总,就可以得到该词在多少文章出现过。
2.3第三个mapreduce,计算词频
利用第一个mapreduce计算的词频,再将第一个mapreduce计算的文章数和第二个mapreduce计算的单词出现过的文章次数作为配置文件读进来放进map中,在map的时候每读入一个词和id,就能找到这个词在多少个文章出现过,再得到count,就能计算出词的tf-idf。
我们可以打开IDEA,进入hellohadoop|com.hongya|day028目录下查看详细代码。
步骤3:运行程序
实验中有三个步骤,需要运行三次,本次实验会在本地运行,所以我们不需要集群环境。
3.1计算词频tf和文章总数(此处工具为IDEA)。
Step1:直接打开FirstJob设置好输入和输出后直接运行。
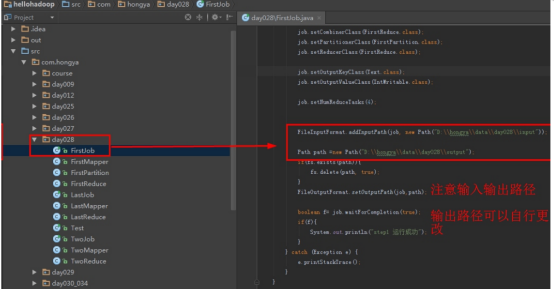


单击运行:
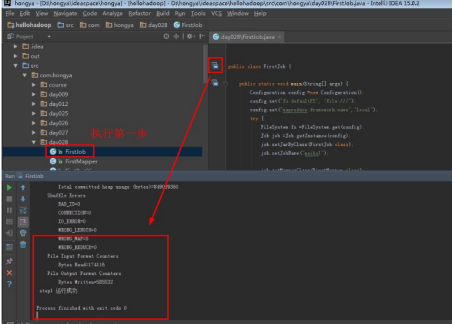
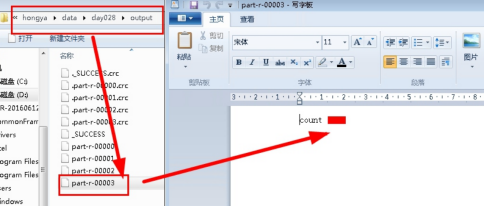
进入目录D:\hongya\data\day028\output,以写字板方式打开part-r-00003查看文章总数。
步骤4:计算词频
4.1计算每个词在多少个文章出现过。
运行Step2:点开TwoJob,设置输入输出运行,注意其输入为Step1的输出。
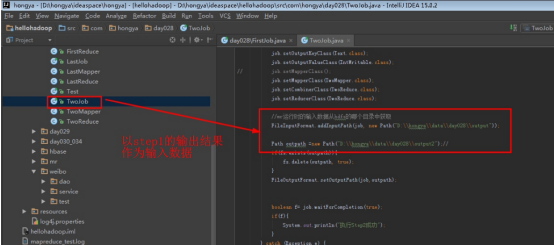
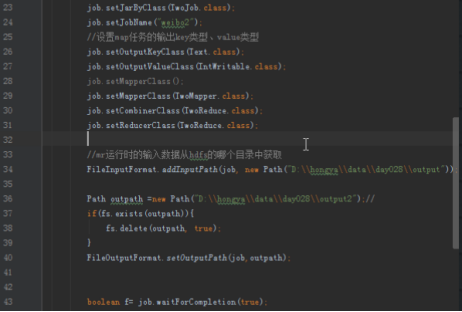
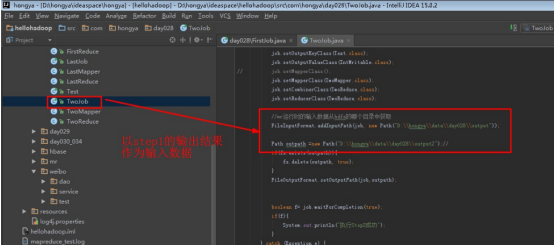
点击运行:
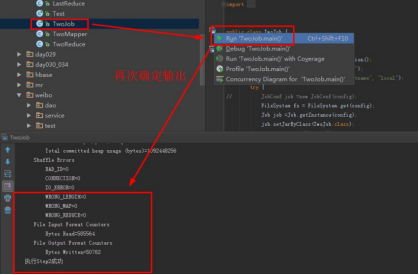
实验结果可以进入操作机目录D:\hongya\data\day028\output2\part-r-00000中查看。
4.2计算词频。
运行Step3:点开LastJob,设置输入输出运行,注意其输入为Step1的输出。
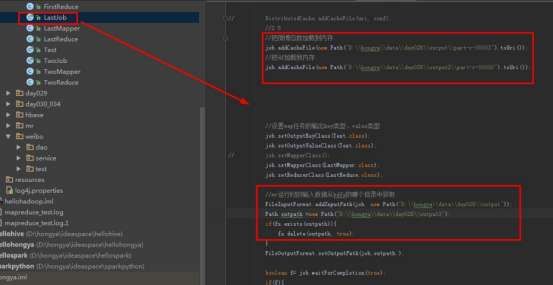
点击运行程序:
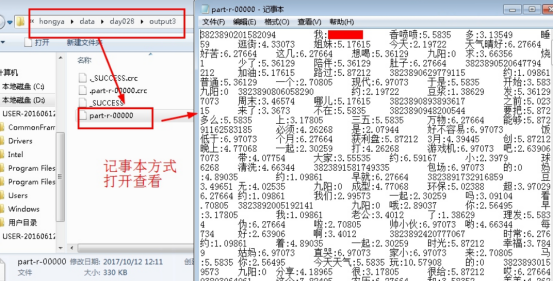
4.3查看实验结果。进入操作机目录D:\hongya\data\day028\output3,以记事本方式查看part-r-00000。见下图:


吴裕雄--天生自然HADOOP操作实验学习笔记:tf-idf算法的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pagerank算法
实验目的 了解PageRank算法 学会用mapreduce解决实际的复杂计算问题 实验原理 1.pagerank算法简介 PageRank,即网页排名,又称网页级别.Google左侧排名或佩奇排名. ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
随机推荐
- cd命令和roscd命令的区别,并解决环境变量问题
cd命令和roscd命令都是切换到指定目录的命令.不同的是,cd是Linux系统的命令,在使用时必须指定目标目录的完整路径:而roscd是ros系统中的命令,它可以直接切换到指定目录(ros系统中的软 ...
- QT笔记:数据库总结
http://blog.csdn.net/reborntercel/article/details/6991147 #include <QtSql> QT += sql QSqlDatab ...
- The Top 500 Worst Passwords (2008)
Top 100 123456 password 12345678 1234 pussy 12345 dragon qwerty 696969 mustang letmein baseball mast ...
- selenium 多表单切换
frame/iframe表单嵌套页面的应用.WebDrivr只能在一个页面上对元素识别与定位,对于在frame/iframe表单内嵌页面上的元素无法直接定位.这时需要使用 switch_to.fram ...
- It is possible and safe to monitor a table DML history on sqlserver
He is my test step: In a test enviroument, I make a table "test"/ demo table:create table ...
- 用EFCore的 FluentAPI 方式生成MySql 带注释的数据库表结构
采用的是net Core 3.1框架下的 的WebAPI项目. 1. 创建ASP.NET Core Web项目 2. 添加NuGet引用包,包如下 Microsoft.EntityFramewor ...
- Burpsuite Pro 2020.1最新破解版
简介 Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程.所有工具都共享一个请求,并能处理对应的HTTP ...
- C++括号匹配检测(用栈)
输入一串括号,包括圆括号和方括号,()[],判断是否匹配,即([]())或[([][])]为匹配的正确的格式,[(])或([())为不匹配的格式. #include<iostream> # ...
- 使用gRPC-Web从浏览器调用.NET gRPC服务
我很高兴宣布通过.NET对gRPC-Web进行实验性支持.gRPC-Web允许从基于浏览器的应用程序(例如JavaScript SPA或Blazor WebAssembly应用程序)调用gRPC. . ...
- (转载)Linux平台下安装 python 模块包
https://blog.csdn.net/aiwangtingyun/article/details/79121145 一.安装Python Windows平台下: 进入Python官网下载页面下载 ...