JS DOM操作(创建、遍历、获取、操作、删除节点)
创建节点
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>create方法</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
// 创建注释节点
var comment = document.createComment("A comment");
// 创建文档片段
var fragment = document.createDocumentFragment(); var ul = document.getElementById("myList");
var li = null;
for (var i = 0; i < 3; i++){
// 创建元素节点
li = document.createElement("li");
// 添加创建好的文本节点
li.appendChild(document.createTextNode("Item " + (i+1)));
fragment.appendChild(li);
}
ul.appendChild(fragment);
// 插入注释节点
document.body.insertBefore(comment, document.body.firstChild);
});
</script>
</head>
<body>
<ul id="myList"></ul>
</body>
</html>
html5shiv
(function() {
if (!
/*@cc_on!@*/
0) return;
var e = "abbr, article, aside, audio, canvas, datalist, details, dialog, eventsource, figure, footer, header, hgroup, mark, menu, meter, nav, output, progress, section, time, video".split(', ');
var i = e.length;
while (i--){
document.createElement(e[i]);
}
})();
创建节点createElement:
它的的参数可以是大小也可以是小写,但是多数情况下我们使用小写
document.createElement()创建的HTML5标签是可以兼容IE8以下的浏览器的
高效创建节点innerHTML-outerHTML
// innerHTML的限制:
// 字符串最左边不能出现空白,否则会被移除
// 多数浏览器不会对script脚本进行执行
// 不能单独创建meta/style/link等
myReady(function(){
var content = document.getElementById("content");
var str = "<p>This is a <strong>paragraph</strong> with a list following it.</p>"
+ "<ul>"
+ "<li>Item 1</li>"
+ "<li>Item 2</li>"
+ "<li>Item 3</li>"
+ "</ul>";
content.innerHTML = str;
alert(content.innerHTML);
});
多数浏览器不会对script脚本进行执行
解决:添加defer属性
放在有作用域的元素之后
var content = document.getElementById("content");
var str = "<input type=\"hidden\"><script defer>alert('hi');<\/script>";
content.innerHTML = str;
});
创建style时解决IE兼容
var content = document.getElementById("content");
var str = "_<style type=\"text/css\">body {background-color: red; }</style>";
content.innerHTML = str;
// 移除最开头添加的_
content.removeChild(content.firstChild);
});
innerText
// innerText兼容火狐写法:textContent
var content = document.getElementById("content");
function getInnerText(element){
return typeof (element.textContent == "string") ? element.textContent : element.innerText;
}
function setInnerText(element, text){
if (typeof element.textContent == "string"){
element.textContent = text;
} else {
element.innerText = text;
}
}
setInnerText(content, "Hello world!");
console.log(getInnerText(content));
节点遍历(查找节点)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>dom Tree walker</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
// documentElement返回文档根节点
var oHtml = document.documentElement;
var p = document.getElementById("paragraph");
var txt = p.childNodes[0]; // 获取head节点三种方法
var oHead = oHtml.firstChild;
var oHead = oHtml.childNodes[0];
var oHead = oHtml.childNodes.item(0); // 获取body节点的两种方法
var oBody = oHtml.childNodes.item(1);
var oBody = oHtml.childNodes[1]; console.log(oHead.parentNode == oHtml);
console.log(oBody.parentNode == oHtml); // 上一个兄弟元素
console.log(oBody.previousSibling == oHead);
// 下一个兄弟元素
console.log(oHead.nextSibling == oBody); console.log(oBody);
console.log(oHead);
console.log(oHtml.tagName);//HTML // 通过p节点找到document节点
console.log(p.ownerDocument == document);
// 是否有子节点
console.log(p.hasChildNodes());
console.log(txt.hasChildNodes());
});
</script>
</head><body>
<p id="paragraph">文本叶子节点</p>
</body>
</html>
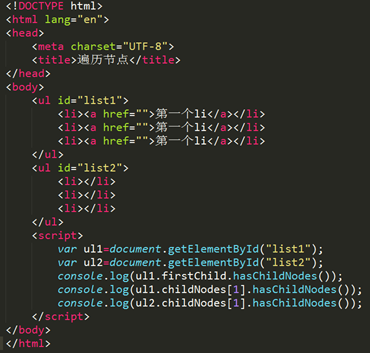
输出分别是:false/true/false
1、 首先区分firstChild和childNodes的区别
firstChild表示第一个子节点, 这个子节点包括元素节点,文本节点或者注释节点
childNodes 返回节点的子节点集合,包括元素节点、文本节点还有属性节点。
2、分析这题的代码
第一个ul的第一个子节点是一个空的文本节点,也就是ul和li的换行,他是没有子节点的,所以为false
第一个ul的第二个子节点是第一个li,有子节点,所以为true
第二个ul的第一个li,没有子节点,所以为false
打印HTML结构树:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>DOM Travel</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
var s = "";
// space存储节点间分隔的字符串
// node保存遍历的当前节点
function travel(space, node) {
if (node.tagName) { // 如果当前节点是标签,不是空的,就拼接字符串
s += space + node.tagName + "<br/>";
}
var len = node.childNodes.length; //保存当前节点的子节点的个数
for (var i = 0; i < len; i++) { //遍历节点的子节点
// 递归调用travel()
travel(space + "|-", node.childNodes[i]);
}
}
travel("", document);
document.write(s);
});
</script>
</head>
<body>
<form>
<input type="button" id="button1" name="button1" value="Click Me!" />
</form>
</body>
</html>

解决空白节点问题方法一:
1 元素节点
2 属性节点
3 文本节点
var box = document.getElementById("box");
for(var i = 0, len = box.childNodes.length; i < len; i++) {
if (box.childNodes[i].nodeType == 1) {
// 只输出元素节点(过滤文本节点)
console.log(box.childNodes[i]);
}
}
解决空白节点问题方法二:
firstElementChild第一个元素节点
lastElementChild
nextElementSibling下一个兄弟元素节点
previoustElementSibling
childElementCount 所有直接子元素节点的个数
var box = document.getElementById("box");
for(var i = 0, len = box.childElementCount; i < len; i++) {
console.log(box.children[i]);
}
类数组对象nodeList
类数组对象无法使用数组方法
将类数组对象转为数组
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>NodeList对象的特点</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
var box = document.getElementById("box");
var nodes = box.childNodes; // 类数组对象无法使用数组方法
console.log(nodes);
console.log(nodes[1]);
nodes.push("<li>节点四</li>"); // 将类数组对象转为数组兼容IE的写法
function makeArray(nodeList){
var arr = null;
try {
// 将类数组对象转为数组
return Array.prototype.slice.call(nodeList);
}catch (e){
arr = new Array();
for(var i = 0, len = nodeList.length; i < len; i++){
arr.push(nodeList[i]);
}
}
return arr;
} var newNodeList = makeArray(nodes);
newNodeList.push("<li>节点四</li>");
console.log(newNodeList);
});
</script>
</head>
<body>
<ul id="box">
<li>节点一</li>
<li>节点二</li>
<li>节点三</li>
</ul>
</body>
</html>
类数组对象HTMLCollection
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>类数组对象HTMLCollection</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
var scripts = document.scripts;
var links = document.links;
// 表格元素
var cells = document.getElementById("tr").cells;
// var imgs = document.images;
var forms = document.forms;
var options = document.getElementById("select").options;
var ps = document.getElementsByTagName("p"); console.log(scripts);
console.log(links);
console.log(cells);
// console.log(imgs);
console.log(forms);
console.log(options);
console.log(ps); //HTMLCollection对象的namedItem()方法
//返回集合中具有指定name属性或id属性的元素
console.log(cells.namedItem('td'));
});
</script>
</head>
<body>
<ul id="box">
<li>节点一</li>
<li>节点二</li>
<li>节点三</li>
</ul> <table border="1">
<tr id="tr">
<td id="td">第一行</td>
<td name="td">第二行</td>
<td name="td">第三行</td>
</tr>
</table> <!-- <img src="duer.jpg" alt="img1" />
<img src="ipone6s+.png" alt="img2" /> --> <form action="">
<input type="text" value="用户名">
</form>
<form action="">
<input type="text" value="密码">
</form> <a href="#">忘记密码</a>
<a href="#">更多内容</a> <select id="select">
<option value="0">北京</option>
<option value="1">天津</option>
<option value="2">河北</option>
</select> <p>DOM探索之基础详解篇</p>
<p>DOM探索之节点操作篇</p>
</body>
</html>
类数组对象NamedNodeMap
返回attr属性相关信息
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>类数组对象NamedNodeMap</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
var box = document.getElementById("box");
var attrs = box.attributes;
console.log(attrs);
console.log(attrs.length);
console.log(attrs[0]);
console.log(attrs.item(1));
});
</script>
</head>
<body>
<ul id="box" data-url="index.html" node-action="submit">
<li>节点一</li>
<li>节点二</li>
<li>节点三</li>
</ul>
</body>
</html>
类数组对象具有动态性
var divs = document.getElementsByTagName("div");
// 先把最初的长度记录在变量里,防止后期动态改变
var length = divs.length;
var i = 0;
while(i < length){
document.body.appendChild(document.createElement("div"));
i++;
}
获取节点
getElementsByName()方法必须在document后使用
// 获取所有的元素
var all = document.getElementsByTagName('*');
getElementsByClassName()兼容性问题解决:
封装函数:
// 函数用于选取符合标签名的元素
var getElementsByClassName = function(opts) {
var searchClass = opts.searchClass; // 存储要查找的类名
var node = opts.node || document; // 存储要出查找的范围
var tag = opts.tag || '*'; // 存储一定范围内要查找的标签
var result = [];
// 判断浏览器支不支持getElementsByClassName方法
if (document.getElementsByClassName) { // 如果浏览器支持
var nodes = node.getElementsByClassName(searchClass);
if (tag !== "*") {
for (var i = 0; node = nodes[i++];) {
if (node.tagName === tag.toUpperCase()) {
result.push(node);
}
}
} else {
result = nodes;
}
return result;
} else { // 使用IE8以下的浏览器能够支持该属性
var els = node.getElementsByTagName(tag);
var elsLen = els.length;
var i, j;
var pattern = new RegExp("(^|\\s)" + searchClass + "(\\s|$)");
for (i = 0, j = 0; i < elsLen; i++) {
if (pattern.test(els[i].className)) { // 检测正则表达式
result[j] = els[i];
j++;
}
}
return result;
}
}
页面调用:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>getElementsByClassName() 兼容浏览器方案</title>
<script src="domReady.js"></script>
<script src="getElementsByClassName.js"></script>
<script>
myReady(function(){
var myUl2 = document.getElementById("myUl2");
var r = getElementsByClassName({
searchClass: "light dark",
node: myUl2
});
console.log(r[0].innerHTML);
});
</script>
</head>
<body>
<ul id="myUl">
<li class="light">1</li>
<li class="light dark">2</li>
<li class="light">3</li>
</ul>
<ul id="myUl2">
<li class="light">1</li>
<li class="light dark">second</li>
<li class="light">3</li>
</ul>
</body>
</html>
querySelector()和querySelectorAll()方法
querySelectorAll()和querySelector()方法返回的是一个静态的NodeList,所谓静态NodeList就是对底层document的更改不会影响到返回的这个NodeList对象.此时返回的NodeList只是querySelectorAll()方法被调用时的文档状态的快照
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>querySelector()</title>
<script src="domReady.js"></script>
<script>
myReady(function(){
var myDiv = document.getElementById('myDiv');
// querySelector(id)
var ul = myDiv.querySelector('#myUl');
var ul = document.querySelector('#myUl');
// querySelector(css选择器)
var li = myDiv.querySelector('li:last-child');
// querySelector(tag)
var els = document.querySelector('input, li');
var span = document.querySelector('span');
// querySelector(class)
// class名中有特殊符号需要转义
var input = document.querySelector('.foo\\:bar');
console.log(ul);
console.log(li);
console.log(els);
console.log(span);
console.log(input);
});
</script>
</head>
<body>
<input type="text" class="foo:bar" value="请输入内容" />
<div id="myDiv">
You are my sunshine.
<ul id="myUl">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
</div>
</body>
</html>
JS DOM操作-操作节点
document.createTextNode() 创建文本节点
document.createElement() 创建元素节点
document.firstElementChild 第一个子元素节点
appendChild() 在最后追加子节点
.children.item(n) 第n个子元素
insertBefore(pos,null) 在最后追加子节点
li. insertBefore(pos,ul.firstElementChild) 在最前面插入子节点
li. insertBefore(pos,ul.lastElementChild) 在最后追加子节点
replaceChild(新节点,要替换掉的节点)
cloneNode() 克隆节点
cloneNode(true) 克隆节点(包括子节点)
document.body.appendChild(newNode) 克隆之后将新节点添加到文档中
normalize() 合并某个元素的文本节点
.nodeValue() 获取节点的值(文本值)
splitText(n) 从n位置进行拆分(拆分元素的文本节点)
JS DOM操作-删除节点
removeNode() IE方法,删除指定元素
removeNode(true) IE方法,删除指定元素及子元素
JS DOM操作(创建、遍历、获取、操作、删除节点)的更多相关文章
- jQuery里面的DOM操作(查找,创建,添加,删除节点)
一:创建元素节点(添加) 创建元素节点并且把节点作为元素的子节点添加到DOM树上 append(): 在元素下添加元素 用法:$("id").append("定义的节点& ...
- Java File文件操作 创建文件\目录,删除文件\目录
Java手册 java.io 类 File java.lang.Object java.io.File 所有已实现的接口: Serializable, Comparable<File> p ...
- 转-JS子窗口创建父窗口操作父窗口
Javascript弹出子窗口 可以通过多种方式实现,下面介绍几种方法 (1) 通过window对象的open()方法,open()方法将会产生一个新的window窗口对象 其用法为: window ...
- 原生js动态创建、获取、删除属性的几种方式
1.创建属性 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <ti ...
- cookie——创建、获取、删除
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- js设置、修改、获取、删除 cookie
上面这串省略号对于各种吐槽的声音:因为在百度上看到的关于设置cookie的前几篇文章都是错误的: 里面给出的设置cookie的代码是这样的: function setCookie(name,value ...
- JavaScript学习总结【5】、JS DOM
1.DOM 简介 当页面加载时,浏览器会创建页面的文档对象模型(Document Object Model).文档对象模型定义访问和处理 HTML 文档的标准方法.DOM 将 HTML 文档呈现为带有 ...
- JS DOM(2017.12.28)
一.获得元素节点的方法 document.getElementById() 根据Id获取元素节点 document.getElementsByName() 根据name获取元素节点 遍 ...
- js的DOM节点操作:创建 ,插入,删除,复制,查找节点
DOM含义:DOM是文档对象模型(Document Object Model,是基于浏览器编程的一套API接口,是W3C出台的推荐标准.其赋予了JS操作节点的能力.当网页被加载时,浏览器就会创建页面的 ...
随机推荐
- char *p=new char[n] delete[] p出错
上面不delete不出错然后下面单个输入出现乱码
- error C2338: No Q_OBJECT in the class with the signal (NodeCreator.cpp)
在Qt中,当派生类需要用到信号与槽机制时,有两个要求. 1.该类派生自QObject类. 2.类中有Q_OBJECT宏. 本次报错的原因就是因为没有在类中添加Q_OBJECT宏. 而我的出错原因更傻逼 ...
- Redis5.xc两种持久化方式以及主从复制配置
关注公众号:CoderBuff,回复"redis"获取<Redis5.x入门教程>完整版PDF. <Redis5.x入门教程>目录 第一章 · 准备工作 第 ...
- 关于macos升级到catalina之后cisco无法使用的问题
最近升级macos到最新的catalina系统,发现cisco的anyconnect用不了了,google了下,发现不是个例,mac提示联系软件开发者更新软件以兼容catalina,这就呵呵了. 于是 ...
- Qps从300到1500的优化过程
最近压测一项目,遇到的性能问题比较典型,过程记录下来,给大家做定位调优参考: 表象: 单接口负载测试,qps最高到300,响应时间200ms,应用cpu达到90%以上,8c机器,如下图,写到这里可能有 ...
- JAVA架构之单点登录 任务调度 权限管理 性能优化大型项目实战
单点登录SSO(Single Sign On)说得简单点就是在一个多系统共存的环境下,用户在一处登录后,就不用在其他系统中登录,也就是用户的一次登录能得到其他所有系统的信任.单点登录在大型网站里使用得 ...
- 08.JS单词整理
以下为按照文章顺序简单整理的JS单词, 注意:是JS单词注释,部分与英文不符 01.JS语法规范.变量与常量 console——控制台 log——日志 var——变量 variable变量,变化 co ...
- scrapy 当当网 爬虫
前言 好久没有写实战博客了,因为前几个月在公司实习,博客更新就耽搁了下来,现在又受疫情影响无法返校,但是技能还是不能丢的,今天就写一篇使用scrapy爬取当当网的实战练习吧. 创建scrapy项目 目 ...
- c语言心形告白代码实现
c语言心形告白代码实现 1.彩色告白 include<stdio.h> include<math.h> include<windows.h> include< ...
- Mysql 字符串转数字类型
使用场景: 在数据库中进行数字比较,但是数字的存储格式是varchar的时候可以使用以下方法进行转换,然后进行比较 方法一:SELECT CAST('123' AS SIGNED); 方法二:SELE ...