Java并发读书笔记:JMM与重排序
Java内存模型(JMM)
Java内存模型(JMM)定义了程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。
在Java中,所有实例域、静态域和数组元素都存在堆内存中,堆内存在线程之间共享,这些变量就是共享变量。
局部变量(Local Variables),方法定义参数(Formal Method Parameters)和异常处理参数(Exception Handler Parameters)不会在线程之间共享,它们不存在内存可见性问题。
JMM抽象结构
图参考自《Java并发编程的艺术》3-1
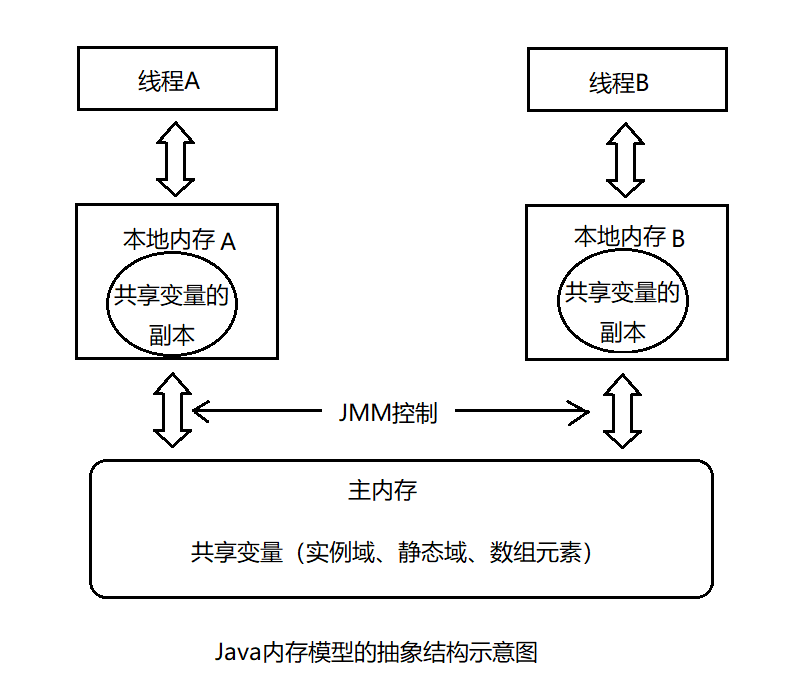
上图是抽象结构,一个包含共享变量的主内存(Main Memory),出于提高效率,每个线程的本地内存中都拥有共享变量的副本。Java内存模型(简称JMM)定义了线程和主内存之间的抽象关系,抽象意味着并不具体存在,还涵盖了其他具体的部分,如缓存、写缓存区、寄存器等。
此时线程A、B之间是如何进行通信的呢?
- A把本地内存中的更新的共享变量刷新到主内存中。
- B再从主内存中读取更新后的共享变量。
明确一点,JMM通过控制主内存与每个线程的本地内存之间的交互,确保内存的可见性。
重排序
编译器和处理器为了优化程序性能会对指令序列进行重新排序,重排序可能会导致多线程出现内存可见性问题。
源码->最终指令序列
下图为《Java并发编程的艺术》3-3
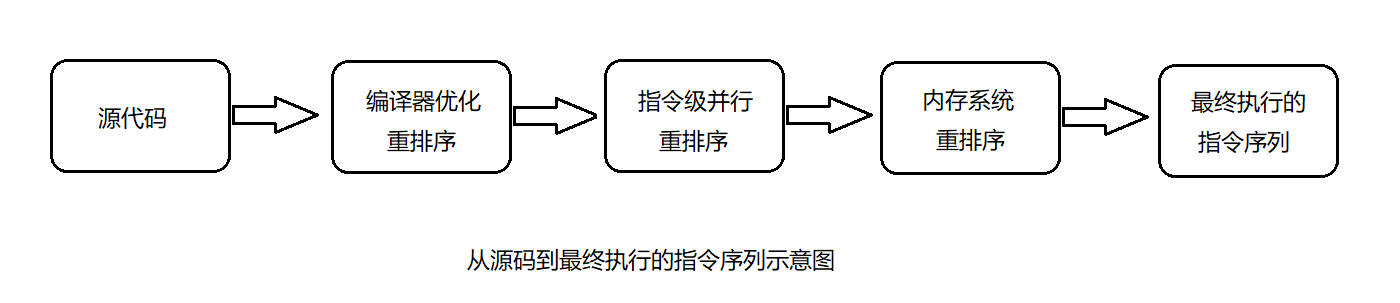
编译器重排序
- 编译器优化的重排序:编译器不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
JMM对于编译器重排序规则会禁止特定类型的编译器重排序。
处理器重排序
- 指令级并行的重排序:现代处理器采用指令级并行技术(Instruction-Level-Parallelism,ILP)将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应及其指令的执行顺序。
- 内存系统的重排序:处理器使用缓存和读/写缓冲区,使得加载和存储的操作看起来在乱序执行。
对于处理器重排序,JMM的处理器重排序会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,以禁止特定类型的处理器重排序。
数据依赖性
如果两个操作访问同一变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
编译器和处理器会遵守数据依赖性,不会改变存在数据依赖关系的两个操作的执行顺序。(针对单个处理器中执行的指令序列和单个线程中执行的操作)
考虑抽象内存模型,现代处理器处理线程之间数据的传递的过程:将数据写入写缓冲区,以批处理的方式刷新写缓冲区,合并写缓冲区对同一内存地址的多次写,减少内存总线的占用。但每个写缓冲区只对它所在的处理器可见,处理器对内存的读/写操作可能就会改变。
as-if-serial
不管怎么重排序,(单线程)程序的执行结果不能被改变,同样,不会对具有数据依赖性的操作进行重排序,相应的,如果不存在数据依赖,就会重排序。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
- C与A访问同一变量pi、C与B访问同一变量r,且存在写操作,具有依赖关系,它们之间不会进行重排序。
- A与B之间不存在依赖关系,编译器和处理器可以重排序,可以变成B->A->C。
很明显,as-if-serial语义很好地保护了上述单线程,让我们以为程序就是按照A->B->C的顺序执行的。
happens-before
从JDK5开始,Java使用新的JSR-133内存模型,使用happens-before的概念阐述操作之间的内存可见性。
有个简单的例子理解所谓的可见性和happens-before“先行发生”的规则。
i = 1; //在线程A中执行
j = i; //在线程B中执行
我们对线程B中这个j的值进行分析:
假如A happens-before B,那么A操作中i=1的结果对B可见,此时j=1,是确切的。但如果他们之间不存在happens-before的关系,那么j的值是不一定为1的。
在JMM中,如果一个操作执行的结果需要对另一个操作可见,两个操作可以在不同的线程中执行,那么这两个操作之间必须要存在happens-before。
happens-before的规则
以下源自《深入理解Java虚拟机》
意味着不遵循以下规则,编译器和处理器将会随意进行重排序。
- 程序次序规则(Program Order Rule):在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。
- 监视器锁规则(Monitor Lock Rule):一个unLock操作在时间上先行发生于后面对同一个锁的lock操作。
- volatile变量规则(Volatile Variable Rule):对一个volatile变量的写操作在时间上先行发生于后面对这个量的读操作。
- 线程启动规则(Thread Start Rule):Thread对象的
start()先行发生于此线程的每一个动作。 - 线程终止规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测。
- 线程中断规则(Thread Interruption Rule):对线程
interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生。 - 对象终结规则(Finalizer Rule):一个对象的初始化完成先行发生于它的
finalize()方法的开始。 - 传递性(Transitivity):A在B之前发生,B在C之前发生,那么A在C之前发生。
happens-before关系的定义
- 如果A happens-before B,A的执行结果对B可见,且A的操作的执行顺序排在B之前,即时间上先发生不代表是happens-before。
- A happens-before B,A不一定在时间上先发生。如果两者重排序之后,结果和happens-before的执行结果一致,就ok。
举个例子:
private int value = 0;
public void setValue(int value){
this.value = value;
}
public int getValue(){
return value;
}
假设此时有两个线程,A线程首先调用setValue(5),然后B线程调用了同一个对象的getValue,考虑B返回的value值:
根据happens-before的多条规则一一排查:
- 存在于多个线程,不满足程序次序的规则。
- 没有方法使用锁,不满足监视器锁规则。
- 变量没有用volatile关键字修饰,不满足volatile规则。
- 后面很明显,都不满足。
综上所述,最然在时间线上A操作在B操作之前发生,但是它们不满足happens-before规则,是无法确定线程B获得的结果是啥,因此,上面的操作不是线程安全的。
如何去修改呢?我们要想办法,让两个操作满足happens-before规则。比如:
- 利用监视器锁规则,用
synchronized关键字给setValue()和getValue()两个方法上一把锁。 - 利用volatile变量规则,用
volatile关键字给value修饰,这样写操作在读之前,就不会修改value值了。
重排序对多线程的影响
考虑重排序对多线程的影响:
如果存在两个线程,A先执行writer()方法,B再执行reader()方法。
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
Public void reader() {
if (flag) { // 3
int i = a * a; // 4
……
}
}
}
在没有学习重排序相关内容前,我会毫不犹豫地觉得,运行到操作4的时候,已经读取了修改之后的a=1,i也相应的为1。但是,由于重排序的存在,结果也许会出人意料。

操作1和2,操作3和4都不存在数据依赖,编译器和处理器可以对他们重排序,将会导致多线程的原先语义出现偏差。
顺序一致性
数据竞争与顺序的一致性
上面示例就存在典型的数据竞争:
- 在一个线程中写一个变量。
- 在另一个线程中读这个变量。
- 写和读没有进行同步。
我们应该保证多线程程序的正确同步,保证程序没有数据竞争。
顺序一致性内存模型
- 一个线程中的所有操作必须按照程序的顺序来执行。
- 所有线程都只能看到一个单一的操作执行顺序。
- 每个操作都必须原子执行且立刻对所有线程可见。
这些机制实际上可以把所有线程的所有内存读写操作串行化。
顺序一致性内存模型和JMM对于正确同步的程序,结果是相同的。但对未同步程序,在程序顺序执行顺序上会有不同。

JMM处理同步程序
对于正确同步的程序(例如给方法加上synchronized关键字修饰),JMM在不改变程序执行结果的前提下,会在在临界区之内对代码进行重排序,未编译器和处理器的优化提供便利。
JMM处理非同步程序
对于未同步或未正确同步的多线程程序,JMM提供最小安全性。
一、什么是最小安全性?
JMM保证线程读取到的值要么是之前某个线程写入的值,要么是默认值(0,false,Null)。
二、如何实现最小安全性?
JMM在堆上分配对象时,首先会对内存空间进行清零,然后才在上面分配对象。因此,在已清零的内存空间分配对象时,域的默认初始化已经完成(0,false,Null)
三、JMM处理非同步程序的特性?
- 不保证单线程内的操作会按程序的顺序执行。
- 不保证所有线程看到一致的操作执行顺序。
- 不保证64位的long型和double型的变量的写操作具有原子性。(与处理器总线的工作机制密切相关)
- 对于32位处理器,如果强行要求它对64位数据的写操作具有原子性,会有很大的开销。
- 如果两个写操作被分配到不同的总线事务中,此时64位写操作就不具有原子性。
总结
JMM遵循的基本原则:
对于单线程程序和正确同步的多线程程序,只要不改变程序的执行结果,编译器和处理器无论怎么优化都OK,优化提高效率,何乐而不为。
as-if-serial与happens-before的异同
异:as-if-serial 保证单线程内程序的结果不被改变,happens-before 保证正确同步的多线程程序的执行结果不被改变。
同:两者都是为了在不改变程序执行结果的前提下,尽可能的提高程序执行的并行度。
参考资料:
《Java并发编程的艺术》方腾飞
《深入理解Java虚拟机》周志明
Java并发读书笔记:JMM与重排序的更多相关文章
- Java并发读书笔记:线程安全与互斥同步
目录 导致线程不安全的原因 什么是线程安全 不可变 绝对线程安全 相对线程安全 线程兼容 线程对立 互斥同步实现线程安全 synchronized内置锁 锁即对象 是否要释放锁 实现原理 啥是重进入? ...
- Java并发(三):重排序
在执行程序时为了提高性能,提高并行度,编译器和处理器常常会对指令做重排序.重排序分三种类型: 编译器优化的重排序.编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序. 指令级并行的重排序 ...
- java并发学习--第九章 指令重排序
一.happns-before happns-before是学习指令重排序前的一个必须了解的知识点,他的作用主要是就是用来判断代码的执行顺序. 1.定义 happens-before是用来指定两个操作 ...
- Java并发读书笔记:Lock与ReentrantLock
Lock位于java.util.concurrent.locks包下,是一种线程同步机制,就像synchronized块一样.但是,Lock比synchronized块更灵活.更复杂. 话不多说,我们 ...
- Java并发编程的艺术(二)——重排序
当我们写一个单线程程序时,总以为计算机会一行行地运行代码,然而事实并非如此. 什么是重排序? 重排序指的是编译器.处理器在不改变程序执行结果的前提下,重新排列指令的执行顺序,以达到最佳的运行效率. 重 ...
- Java并发读书笔记:如何实现线程间正确通信
目录 一.synchronized 与 volatile 二.等待/通知机制 等待 通知 面试常问的几个问题 sleep方法和wait方法的区别 关于放弃对象监视器 三.等待通知典型 生产者消费者模型 ...
- Java并发读书笔记:线程通信之等待通知机制
目录 synchronized 与 volatile 等待/通知机制 等待 通知 面试常问的几个问题 sleep方法和wait方法的区别 关于放弃对象监视器 在并发编程中,保证线程同步,从而实现线程之 ...
- 《深入了解java虚拟机》高效并发读书笔记——Java内存模型,线程,线程安全 与锁优化
<深入了解java虚拟机>高效并发读书笔记--Java内存模型,线程,线程安全 与锁优化 本文主要参考<深入了解java虚拟机>高效并发章节 关于锁升级,偏向锁,轻量级锁参考& ...
- java并发编程笔记(三)——线程安全性
java并发编程笔记(三)--线程安全性 线程安全性: 当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些进程将如何交替执行,并且在主调代码中不需要任何额外的同步或协同,这个类都能表现 ...
随机推荐
- FacadePattern(外观模式)-----Java/.Net
外观模式(Facade Pattern)隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口.这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性
- JAVA8学习——Stream底层的实现(学习过程)
Stream底层的实现 Stream接口实现了 BaseStream 接口,我们先来看看BaseStream的定义 BaseStream BaseStream是所有流的父类接口. 对JavaDoc做一 ...
- STM32动态内存分配需要注意的地方
STM32进行动态内存分配是需要注意动态内存分配大小不要超过.S文件中设置Heap Size大小 如图所示: 0x4000 :可以分配得最大字节是16384bytes 这个地方malloc的大小超过了 ...
- cogs 1176. [郑州101中学] 月考 Map做法
1176. [郑州101中学] 月考 ★★☆ 输入文件:mtest.in 输出文件:mtest.out 简单对比时间限制:1 s 内存限制:128 MB [题目描述] 在上次的月考中B ...
- 图解kubernetes服务打散算法的实现源码
在分布式调度中为了保证服务的高可用和容灾需求,通常都会讲服务在多个区域.机架.节点上平均分布,从而避免单点故障引起的服务不可用,在k8s中自然也实现了该算法即SelectorSpread, 本文就来学 ...
- Java 循环队列
传统数组实现的队列有缺陷,当多次入队出队后,队头指针会后移,当队尾指针达到数组末尾时,会提示队列已满,导致数组前部分空间被浪费.如果当队尾和队头指针到达数组末尾时能从数组[0]继续添加数据,可以提升数 ...
- dp - 求符合题意的序列的个数
The sequence of integers a1,a2,…,ak is called a good array if a1=k−1 and a1>0. For example, the s ...
- 「2.0」一个人开发一个App,小程序从0到1,文件剖析
不知你是不是见到“文件剖析”这4个大字,才点进来看一看的?如果真是的话,那我可以坦诚.真心.负责任地告诉你:你上当了,你上了贼船啦,如果你现在想跳的话,还来得及,反正茫茫大海中,鲨鱼正缺搞程序的人.说 ...
- OAuth2.0的那点荒唐小秘密 -几个简单概念和原理
OAuth2.0这个名词你是否在项目中时常听到呢?是否觉得好像懂,又好像不太懂呢? 最近一直想写篇关于OAuth2.0的东西,记录下我的学习与感悟,然各种理由的拖延,直到今日才静下心来写下这篇博客.当 ...
- context:component-scan标签的诠释
XML中配置context:component-scan时,spring会自动的扫描这个包下被这些注解标识的类@Component,@Service,@Controller,@Repository,同 ...