LinkedHashMap基本原理和用法&使用实现简单缓存(转)
一. 基本用法
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
1:插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
2:访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
LinkedHashMap 继承了HashMap,实现了Map接口
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap一共提供了五个构造方法:
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。所有构造方法都是通过调用父类的构造方法来创建对象的。
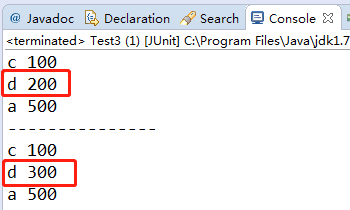
举个例子:键是按照:“c”, “d”,"a"的顺序插入的,修改d不会修改顺序
@Test
public void test2(){
Map<String, Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c",100);
seqMap.put("d",200);
seqMap.put("a",500);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("---------------");
seqMap.put("d",300);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
console输出:
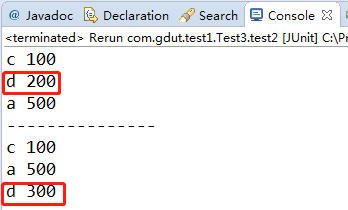
按访问顺序:
@Test
public void test2(){
Map<String, Integer> seqMap = new LinkedHashMap<>(16,0.75f,true);
seqMap.put("c",100);
seqMap.put("d",200);
seqMap.put("a",500);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("---------------");
seqMap.put("d",300);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
console输出:
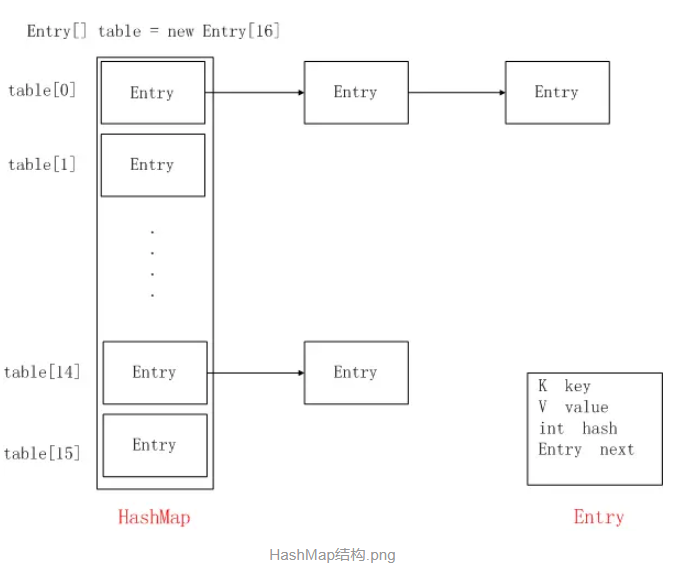
二:HashMap与LinkedHashMap的结构对比
LinkedHashMap其实就是可以看成HashMap的基础上,多了一个双向链表来维持顺序。
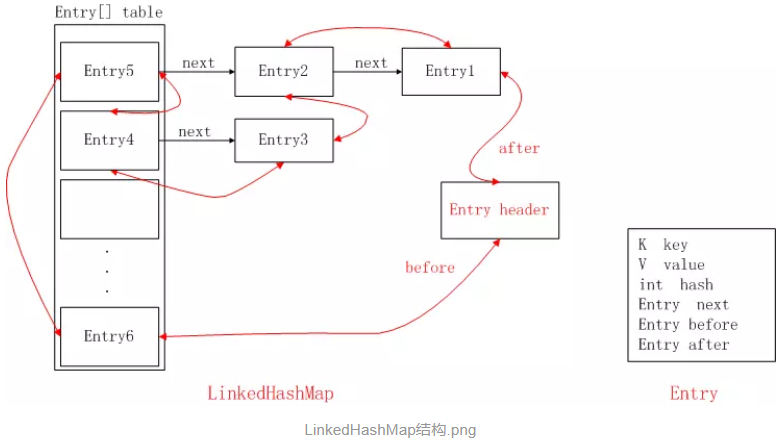
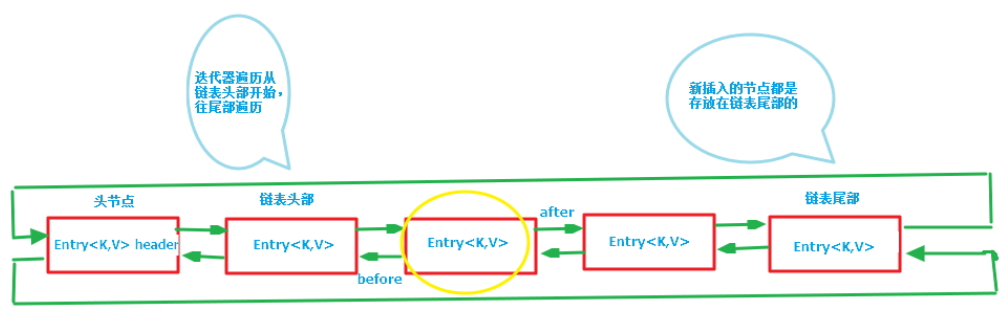
注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
三:借用 LinkedHashMap实现最近被使用(LRU)缓存
最近最少使用缓存的回收
为了实现缓存回收,我们需要很容易做到:
- 查询出最近最晚使用的项
- 给最近使用的项做一个标记
链表可以实现这两个操作。检测最近最少使用的项只需要返回链表的尾部。标记一项为最近使用的项只需要从当前位置移除,然后将该项放置到头部。比较困难的事情是怎么快速的在链表中找到该项。
对于使用链表这种方法,put 和 get 都需要遍历链表查找数据是否存在,所以时间复杂度为 O(n)。空间复杂度为 O(1)。
空间换时间
在实际的应用中,当我们要去读取一个数据的时候,会先判断该数据是否存在于缓存器中,如果存在,则返回,如果不存在,则去别的地方查找该数据(例如磁盘),找到后再把该数据存放于缓存器中,再返回。
所以在实际的应用中,put 操作一般伴随着 get 操作,也就是说,get 操作的次数是比较多的,而且命中率也是相对比较高的,进而 put 操作的次数是比较少的,我们我们是可以考虑采用空间换时间的方式来加快我们的 get 的操作的。
例如我们可以用一个额外哈希表(例如HashMap)来存放 key-value,这样的话,我们的 get 操作就可以在 O(1) 的时间内寻找到目标节点,并且把 value 返回了。
然而,大家想一下,用了哈希表之后,get 操作真的能够在 O(1) 时间内完成吗?
用了哈希表之后,虽然我们能够在 O(1) 时间内找到目标元素,可以,我们还需要删除该元素,并且把该元素插入到链表头部啊,删除一个元素,我们是需要定位到这个元素的前驱的,然而定位到这个元素的前驱,是需要 O(n) 时间复杂度的。
最后的结果是,用了哈希表时候,最坏时间复杂度还是 O(1),而空间复杂度也变为了 O(n)。
双向链表+哈希表
我们都已经能够在 O(1) 时间复杂度找到要删除的节点了,之所以还得花 O(n) 时间复杂度才能删除,主要是时间是花在了节点前驱的查找上,为了解决这个问题,其实,我们可以把单链表换成双链表,这样的话,我们就可以很好着解决这个问题了,而且,换成双链表之后,你会发现,它要比单链表的操作简单多了。
所以我们最后的方案是:双链表 + 哈希表,采用这两种数据结构的组合,我们的 get 操作就可以在 O(1) 时间复杂度内完成了。由于 put 操作我们要删除的节点一般是尾部节点,所以我们可以用一个变量 tai 时刻记录尾部节点的位置,这样的话,我们的 put 操作也可以在 O(1) 时间内完成了。
Java已经为我们提供了这种形式的数据结构 LinkedHashMap!它甚至提供可覆盖回收策略的方法(见removeEldestEntry文档)。唯一需要我们注意的事情是,改链表的顺序是插入的顺序,而不是访问的顺序。但是,有一个构造函数提供了一个选项,可以使用访问的顺序
import java.util.LinkedHashMap;
import java.util.Map; public LRUCache<K, V> extends LinkedHashMap<K, V> {
private int cacheSize; public LRUCache(int cacheSize) {
super(16, 0.75, true);
this.cacheSize = cacheSize;
}
//LinkedHashMap有一个removeEldestEntry(Map.Entry eldest)方法,通过覆盖这个方法,加入一定的条件,满足条件返回true。当put进新的值方法返回true时,便移除该map中最老的键和值。
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() >= cacheSize;
}
}
注:在LinkedHashMap添加元素后,会调用removeEldestEntry防范,传递的参数时最久没有被访问的键值对,如果方法返回true,这个最久的键值对就会被删除。LinkedHashMap中的实现总返回false,该子类重写后即可实现对容量的控制
自己通过HashMap+双向链表实现LRU缓存算法
import java.util.HashMap;
public class LRUCache<K, V> {
private int currentCacheSize; // 当前缓存的容量
private int CacheCapcity; // 缓存容量最大值
private HashMap<K,CacheNode> caches; //HashMap
private CacheNode first; //链表头
private CacheNode last; //链表尾
public LRUCache(int size) {
this.currentCacheSize = 0;
this.CacheCapcity = size;
caches = new HashMap<K, CacheNode>(size);
}
public void put(K k,V v){
CacheNode node = caches.get(k);
if(node == null) { //缓存中没有该key
if(caches.size() >= CacheCapcity) { //缓存容量已经达到最大值了,不能装了
caches.remove(last.key); //删除HashMap中的Node
removeLast(); //删除双向链表中的尾结点Node
}
node = new CacheNode();
node.key = k;
}
node.value = v;
moveToFirst(node);
caches.put(k, node);
}
public Object get(K k){
CacheNode node = caches.get(k);
if(node == null) {
return null;
}
moveToFirst(node);
return node.value;
}
public Object remove(K k) {
CacheNode node = caches.get(k);
if(node != null) {
if(node.pre != null){
node.pre.next=node.next;
}
if(node.next != null){
node.next.pre=node.pre;
}
if(node == first){
first = node.next;
}
if(node == last){
last = node.pre;
}
}
return null;
}
public void clear(){
first = null;
last = null;
caches.clear();
}
private void removeLast(){
if(last != null) {
last = last.pre;
if(last == null) {
first = null;
}else {
last.next = null;
}
}
}
/**
* @param node 插入的结点</br>
* put数据,将新数据放到链表头部,这样链表头部就是最新的数据,尾部就是最少访问的数据
*/
private void moveToFirst(CacheNode node) {
if(first == node){
return;
}
if(node.next != null){
node.next.pre = node.pre;
}
if(node.pre != null){
node.pre.next = node.next;
}
if(node == last){
last= last.pre;
}
if(first == null || last == null){
first = last = node;
return;
}
node.next=first;
first.pre = node;
first = node;
first.pre=null;
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
CacheNode node = first;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
}
return sb.toString();
}
public static void main(String[] args) {
LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3);
lru.put(1, "a"); // 1:a
System.out.println(lru.toString());
lru.put(2, "b"); // 2:b 1:a
System.out.println(lru.toString());
lru.put(3, "c"); // 3:c 2:b 1:a
System.out.println(lru.toString());
lru.put(4, "d"); // 4:d 3:c 2:b
System.out.println(lru.toString());
lru.put(1, "aa"); // 1:aa 4:d 3:c
System.out.println(lru.toString());
lru.put(2, "bb"); // 2:bb 1:aa 4:d
System.out.println(lru.toString());
lru.put(5, "e"); // 5:e 2:bb 1:aa
System.out.println(lru.toString());
lru.get(1); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(11); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(1); //5:e 2:bb
System.out.println(lru.toString());
lru.put(1, "aaa"); //1:aaa 5:e 2:bb
System.out.println(lru.toString());
}
}
LinkedHashMap基本原理和用法&使用实现简单缓存(转)的更多相关文章
- 【转】asp.net mvc3 简单缓存实现sql依赖
asp.net mvc3 简单缓存实现sql依赖 议题 随 着网站的发展,大量用户访问流行内容和动态内容,这两个方面的因素会增加平均的载入时间,给Web服务器和数据库服务器造成大量的请求压力.而大 ...
- Learning ReactNative (一) : JavaScript模块基本原理与用法
在使用ReactNative进行开发的时候,我们的工程是模块化进行组织的.在npmjs.com几十万个库中,大部分都是遵循着CommonJS规则的.在ES6中引入了class的概念,从此JavaScr ...
- localStorage/cookie 用法分析与简单封装
本地存储是HTML5中提出来的概念,分localStorage和sessionStorage.通过本地存储,web应用程序能够在用户浏览器中对数据进行本地的存储.与 cookie 不同,存储限制要大得 ...
- 关于ExpandableListView用法的一个简单小例子
喜欢显示好友QQ那样的列表,可以展开,可以收起,在android中,以往用的比较多的是listview,虽然可以实现列表的展示,但在某些情况下,我们还是希望用到可以分组并实现收缩的列表,那就要用到an ...
- php简单缓存类
<?phpclass Cache { private $cache_path;//path for the cache private $cache_expire;//seconds ...
- ElasticSearch的基本原理与用法
一.简介 ElasticSearch和Solr都是基于Lucene的搜索引擎,不过ElasticSearch天生支持分布式,而Solr是4.0版本后的SolrCloud才是分布式版本,Solr的分布式 ...
- 写了一个Java的简单缓存模型
缓存操作接口 /** * 缓存操作接口 * * @author xiudong * * @param <T> */ public interface Cache<T> { /* ...
- C++标准 bind函数用法与C#简单实现
在看C++标准程序库书中,看到bind1st,bind2nd及bind的用法,当时就有一种熟悉感,仔细想了下,是F#里提到的柯里化.下面是维基百科的解释:在计算机科学中,柯里化(英语:Currying ...
- Django之django-redis对数据进行简单缓存
最近公司老大抱怨,产品某部分内容访问速度奇慢无比,由于是之前接手的别人的代码,不太清楚业务的具体逻辑,不过,经过查看,内容为无需实时更新的内容,so 直接上缓存. 什么是缓存? 对于后端来说,要做的 ...
随机推荐
- JSP 状态管理 -- Session 和 Cookie
Http 协议的无状态性 无状态是指,当浏览器发送请求给服务器的时候,服务器响应客户端请求.但是同一个浏览器再次发送请求给服务器的时候,服务器并不知道它就是刚才那个浏览器 session sessio ...
- C#枚举的简单使用
枚举这个名词大家都听过,很多小伙伴也使用过, 那么枚举在开发中能做什么,使用它后能给程序代码带来什么改变,为什么用枚举. 各位看官且坐下,听我一一道来. 为什么使用枚举? 1.枚举能够使代码更加清晰, ...
- docker run 之后执行多条命令
执行 ls docker run microsoft/dotnet ls && cd /root 执行 多条使用sh -c命令 在run后面加了一个sh -c命令,后面直接加多条语句即 ...
- 基础设施DevOps演进之路
Related Links:Zuul https://github.com/Netflix/zuulCAT https://github.com/dianping/cat Apollo h ...
- 解决Win10系统下 C# DateTime 出现星期几的问题
昨天晚上写代码的时候偶然发现 DateTime 里出现了星期几,当时一阵凌乱,去网上百度没有详细解决办法,很多人说可以用用 ToString 解决. 也有部分人说可以修改系统时间的显示,我打算试一下看 ...
- 浅谈Quartz.Net 从无到有创建实例
一.Quartz.Net介绍 Quartz.NET是一个开源的作业调度框架,非常适合在平时的工作中,定时轮询数据库同步,定时邮件通知,定时处理数据等. Quartz.NET允许开发人员根据时间间隔(或 ...
- CSS3制作上下跳动动画箭头效果
动画效果如下: 代码如下: 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8&q ...
- jsp内置对象-page对象
page对象代表jsp本身,只有在jsp页面才有效.page对象本质上是被转换后的Servlet,因此它可以调用任何被Servlet类所定义的方法. 项目ch05案例:创建HttpJSPPage类的对 ...
- java 线程方法 ---- sleep()
class MyThread implements Runnable{ @Override public void run() { for (int i = 0; i < 5; i++){ Sy ...
- (办公)springboot配置表单验证@Valid
项目用到了springboot,本来很高兴,但是项目里什么东西都没有,验证,全局异常这些都需要自己区配置.最近springboot用的还是蛮多的,我还是做事情,把经验发表一下. SpringBoot提 ...