Tomcat 对 HTTP 协议的实现(下)
在《Tomcat 对 HTTP 协议的实现(上)》一文中,对请求的解析进行了分析,接下来对 Tomcat 生成响应的设计和实现继续分析。本文首发于(微信公众号:顿悟源码)
一般 Servlet 生成响应的代码是这样的:
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
resp.setContentType("text/html");
resp.setCharacterEncoding("utf-8");
PrintWriter writer = resp.getWriter();
writer.println("<html><head><title>Demo</title></head>");
writer.println("<body><div>Hello World!</div></body>");
writer.println("</html>");
writer.flush();
writer.close();
}
像生成响应头和响应体并写入缓冲区,最后写入通道,这些都由 Tomcat 来做,来看下它是怎么设计的(可右键直接打开图片查看大图):
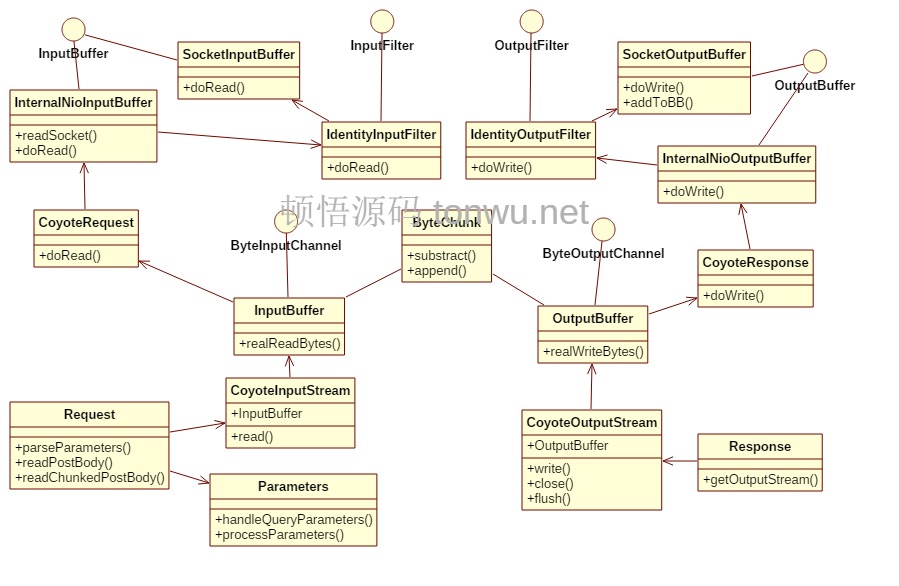
上图大部分类都是相对的,可与请求处理分析中的描述对比理解。重点还是理解 ByteChunk,它内部有一个 byte[] 数组引用,用于输入时,引用的 InternalNioInputBuffer 内的数组,表示一个字节序列的视图;用于输出时,会 new 一个可扩容的数组对象,存储响应体数据。
以上面的代码为例,分析一下,相关类的方法调用,上面的代码生成的是一种动态内容,会使用 chunked 传输编码:
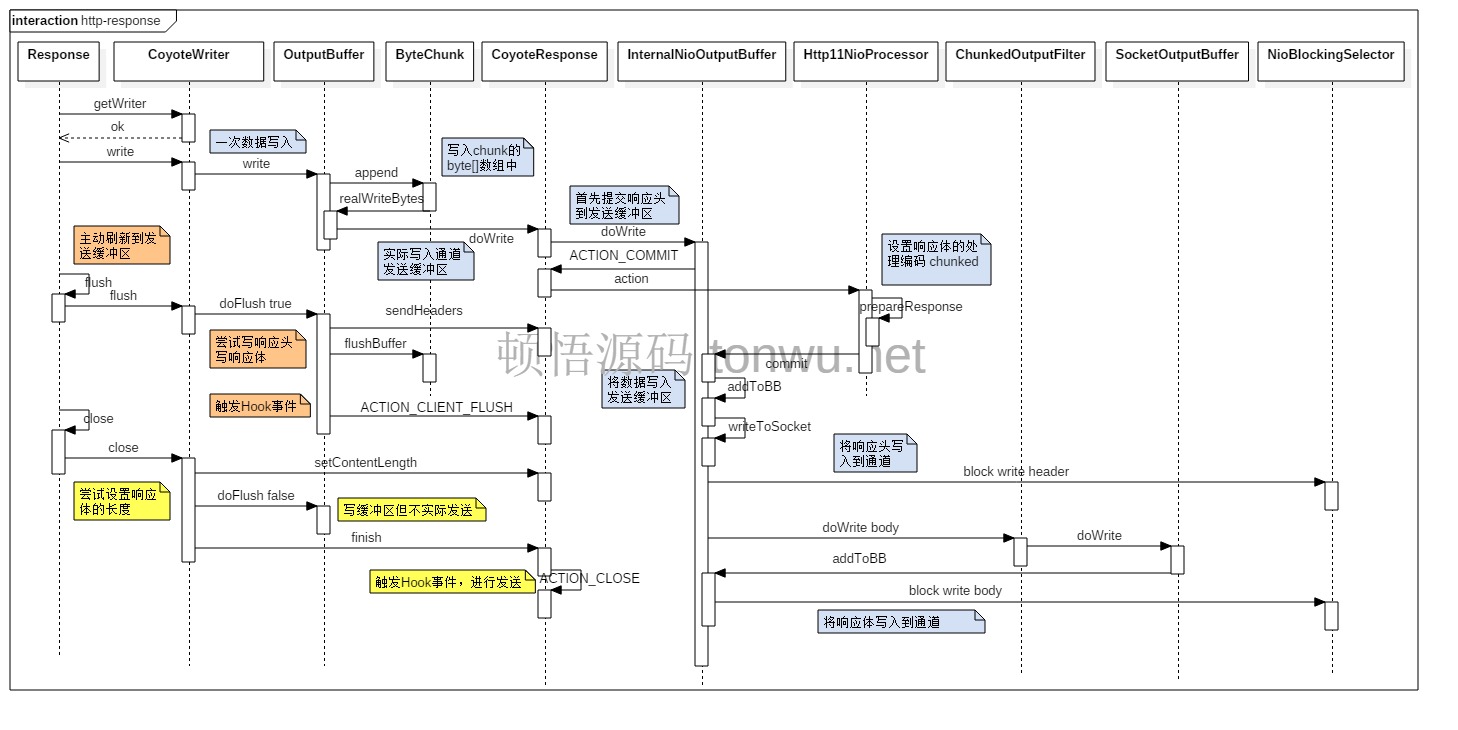
1. 存储响应体数据
调用图中,ByteChunk 调用 append 方法后,为了直观理解,就直接写入了发送缓冲区,真实情况不是这样,只有内部缓冲区满了,或者主动调用 flush、close 才会实际写入和发送,来看下 append 方法的代码:
public void append( byte src[], int off, int len )
throws IOException {
makeSpace( len ); // 扩容,高版本已去掉
// 写入长度超过最大容量,直接往底层数组写
// 如果底层数组也超了,会直接往通道写
if ( optimizedWrite && len == limit && end == start
&& out != null ) {
out.realWriteBytes( src, off, len );
return;
}
// 如果 len 小于剩余空间,直接写入
if( len <= limit - end ) {
System.arraycopy( src, off, buff, end, len );
end+=len;
return;
}
// 否则就循环把长 len 的数据写入下层的缓冲区
int avail=limit-end;
System.arraycopy(src, off, buff, end, avail);
end += avail;
// 把现有数据写入下层缓冲区
flushBuffer();
// 循环写入 len 长的数据
int remain = len - avail;
while (remain > (limit - end)) {
out.realWriteBytes( src, (off + len) - remain, limit - end );
remain = remain - (limit - end);
}
System.arraycopy(src, (off + len) - remain, buff, end, remain);
end += remain;
}
逻辑就是,首先写入自己的缓冲区,满了或不足使用 realWriteBytes 再写入下层的缓冲区中,下层的缓冲区实际就是 NioChannel 中的 WriteBuffer,写入之前首先会把响应头写入 InternalNioInputBuffer 内部的 HeaderBuffer,再提交到 WriteBuffer 中,接着就会调用响应的编码处理器写入响应体,编码处理通常有两种:identity 和 chunked。
2. identity 写入
当明确知道要响应资源的大小,比如一个css文件,并且调用了 resp.setContentLength(1) 方法时,就会使用 identity 写入指定长度的内容,核心代码就是 IdentityOutputFilter 的 doWrite 方法,这里不在贴出,唯一值得注意的是,它内部的 buffer 引用是 InternalNioInputBuffer 内部的 SocketOutputBuffer。
3. chunked 写入
当不确定长度时,会使用 chunked 传输编码,跟解析相反,就是要生成请求分析一文中介绍的 chunked 协议传输格式,写入逻辑如下:
public int doWrite(ByteChunk chunk, Response res)
throws IOException {
int result = chunk.getLength();
if (result <= 0) {
return 0;
}
// 生成 chunk-header
// 从7开始,是因为chunkLength后面两位已经是\r\n了
int pos = 7;
// 比如 489 -> 1e9 -> ['1','e','9'] -> [0x31,0x65,0x39]
// 生成 chunk-size 编码,将 int 转为16进制字符串的形式
int current = result;
while (current > 0) {
int digit = current % 16;
current = current / 16;
chunkLength[pos--] = HexUtils.HEX[digit];
}
chunkHeader.setBytes(chunkLength, pos + 1, 9 - pos);
// 写入 chunk-szie 包含 \r\n
buffer.doWrite(chunkHeader, res);
// 写入实际数据 chunk-data
buffer.doWrite(chunk, res);
chunkHeader.setBytes(chunkLength, 8, 2);
// 写入 \r\n
buffer.doWrite(chunkHeader, res);
return result;
}
所有数据块写入完成后,最后再写入一个大小为0的 chunk,格式为 0\r\n\r\n。至此整个写入完毕。
4. 阻塞写入通道
上层所有数据的实际写入,最后都是由 InternalNioInputBuffer 的 writeToSocket 方法完成,代码如下:
private synchronized int writeToSocket(ByteBuffer bytebuffer,
boolean block, boolean flip) throws IOException {
// 切换为读模式
if ( flip ) bytebuffer.flip();
int written = 0;// 写入的字节数
NioEndpoint.KeyAttachment att = (NioEndpoint.KeyAttachment)
socket.getAttachment(false);
if ( att == null ) throw new IOException("Key must be cancelled");
long writeTimeout = att.getTimeout();
Selector selector = null;
try { // 获取模拟阻塞使用的 Selector
// 通常是单例的 NioBlockingSelector
selector = getSelectorPool().get();
} catch ( IOException ignore ) { }
try {
// 阻塞写入
written = getSelectorPool().write(bytebuffer, socket, selector,
writeTimeout, block,lastWrite);
do {
if (socket.flush(true,selector,writeTimeout,lastWrite)) break;
}while ( true );
}finally {
if ( selector != null ) getSelectorPool().put(selector);
}
if ( block ) bytebuffer.clear(); //only clear
this.total = 0;
return written;
}
模拟阻塞的具体实现,已在 Tomcat 对 NIO 模型实现一文中介绍,这里不再赘述。
5. 缓冲区设计
缓冲区直接关系到内存使用的大小,还影响着垃圾收集。在整个HTTP处理过程中,总共有以下几种缓冲区:
- NioChannel 中的读写 ByteBuffer
- NioInputBuffer 和 NioOutputBuffer 内部使用的消息头字节数组
- ByteChunk 用于写入响应体时内部使用的字节数组
- 解析请求参数时,如果长度过小会使用内部缓存的一个 byte[] 数组,否则新建
以上缓冲区均可重复利用。
6. 小结
为了更好的理解HTTP的解析,尽可能的使用简洁的代码仿写了这部分功能。
源码地址:https://github.com/tonwu/rxtomcat 位于 rxtomcat-http 模块
Tomcat 对 HTTP 协议的实现(下)的更多相关文章
- tomcat配置https协议
tomcat配置https协议 1.找到本地jdk底下的bin目录,bin目录底下存在文件keytool.exe(在bin目录下空白处,按住shift右击,打开命令窗口,如下图) 2.在cmd的命令窗 ...
- 配置Tomcat使用https协议(配置SSL协议)
配置Tomcat使用https协议(配置SSL协议) 2014-01-20 16:38 58915人阅读 评论(3) 收藏 举报 转载地址:http://ln-ydc.iteye.com/blog/1 ...
- SMTP协议--在cmd下利用bat命令行发送邮件
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议 选择‘开始’-‘运行’,输入cmd,进入命令提示符窗口. Windows7默认没有开始Telnet服务,请在运 ...
- Tomcat配置https协议访问
Tomcat9配置https协议访问: https://blog.csdn.net/weixin_42273374/article/details/81010203 配置Tomcat使用https协议 ...
- tomcat中如何禁止列目录下的文件
tomcat中如何禁止列目录下的文件在{tomcat_home}/conf/web.xml中,把listings参数设置成false即可,如下: <servlet> <servlet ...
- tomcat在conf/Catalina/localhost目录下配置项目路径
转自:http://wangyl93-dl-cn.iteye.com/blog/1508517 在tomcat的conf/Catalina/localhost目录下配置项目路径,tomcat启动是会直 ...
- Tomcat 没有自动解压webapp下的war项目文件问题
默认选择的tomcat安装在了C盘下的C:\Program Files下 所以webapp文件也在C盘下 选择启动tomcat时 我选择了 bin下的 Tomcat.exe 显示成功启动 打开项目网站 ...
- 利用SSH协议在Windows下使用PuTTY连接Ubuntu
利用SSH协议在Windows下使用PuTTY连接Ubuntu Ubuntu部分 首先我们要为Ubuntu配置一下环境,让它支持ssh服务,我们要做的其实也很简单,就一下两步: 安装OpenSSH软件 ...
- SSL/TLS协议详解(下)——TLS握手协议
本文转载自SSL/TLS协议详解(下)--TLS握手协议 导语 在博客系列的第2部分中,对证书颁发机构进行了深入的讨论.在这篇文章中,将会探索整个SSL/TLS握手过程,在此之前,先简述下最后这块内容 ...
随机推荐
- Travel 并查集
题意:给一个图,若干询问,每次询问只经过边权<=w的边,x能到达的点数 并查集啊,对询问和边排序,直接合并,维护size,查询 #include<cstdio> #include&l ...
- 英国毕业原版-《伯明翰大学毕业证书》UoB一模一样原件
☞伯明翰大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归&a ...
- i春秋——Misc之百度杯
今天心里很是不开森,想想往日何必那么努力呢?不如你的比比皆是,可是人家就是因为有关系,你又能怎样呢? 你所有应该有的都被打翻了,别灰心,至少你曾经努力过! 愿我未来的学弟学妹们都能一直开开心心的过好每 ...
- 用原生JS从零到一实现Redux架构
前言 最近利用业余时间阅读了胡子大哈写的<React小书>,从基本的原理讲解了React,Redux等等受益颇丰.眼过千遍不如手写一遍,跟着作者的思路以及参考代码可以实现基本的Demo,下 ...
- python设计模式-观察者
定义: 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖的对象都会得到通知并被自动更新. 观察者模式是对象的行为模式,又叫发布-订阅(pubish/subscribe)模式,模型 ...
- Promise, Generator, async/await的渐进理解
作为前端开发者的伙伴们,肯定对Promise,Generator,async/await非常熟悉不过了.Promise绝对是烂记于心,而async/await却让使大伙们感觉到爽(原来异步可以这么简单 ...
- Asp.Net Core 轻松学-基于微服务的后台任务调度管理器
前言 在 Asp.Net Core 中,我们常常使用 System.Threading.Timer 这个定时器去做一些需要长期在后台运行的任务,但是这个定时器在某些场合却不太灵光,而且常常无法 ...
- Docker最全教程之使用Docker搭建Java开发环境(十七)
前言 Java是一门面向对象的优秀编程语言,市场占有率极高,但是在容器化实践过程中,发现官方支持并不友好,同时与其他编程语言的基础镜像相比(具体见各语言镜像比较),确实是非常臃肿. 本篇仅作探索,希望 ...
- 好看又能打的CRM系统大比拼:Salesforce, SugarCRM, Odoo等
介绍 今天的CRM市场提供了大量的解决方案和软件替代品.有些适合大型企业(通常需要内部托管),而其他企业则更多地应用于SME的需求(通常使用云托管解决方案). 在CRM解决方案方面,提供商必须调整其产 ...
- Python之路【第五篇】:Python基础之文件处理
阅读目录 一.文件操作 1.介绍 计算机系统分为:计算机硬件,操作系统,应用程序三部分. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操 ...