ThreadPoolExecutor 学习笔记
线程池的奥义
在开发程序的过程中,很多时候我们会遇到遇到批量执行任务的场景,当各个具体任务之间互相独立并不依赖其他任务的时候,我们会考虑使用并发的方式,将各个任务分散到不同的线程中进行执行来提高任务的执行效率。
我们会想到为每个任务都分配一个线程,但是这样的做法存在很大的问题:
1、资源消耗:首先当任务数量庞大的时候,大量线程会占据大量的系统资源,特别是内存,当线程数量大于CPU可用数量时,空闲线程会浪费造成内存的浪费,并加大GC的压力,大量的线程甚至会直接导致程序的内存溢出,而且大量线程在竞争CPU的时候会带来额外的性能开销。如果CPU已经足够忙碌,再多的线程不仅不会提高性能,反而会降低性能。
2、线程生命周期的开销:线程的创建和销毁都是有代价的,线程的创建需要时间、延迟处理的请求、需要JVM和操作系统提供一些辅助操作。如果请求特别庞大,并且任务的执行特别轻量级(比如只是计算1+1),那么对比下来创建和销毁线程代价就太昂贵了。
3、稳定性:如资源消耗中所说,如果程序因为大量的线程抛出OutOfMemoryEorror,会导致程序极大的不稳定。
既然为每个任务分配一个线程的做法已经不可行,我们考虑的代替方法中就必须考虑到,1、线程不能不能无限制创建,数量必须有一个合适的上限。2、线程的创建开销昂贵,那我们可以考虑重用这些线程。理所当然,池化技术是一项比较容易想到的替代方案(马后炮),线程的池化管理就叫线程池。
线程池族谱
ThreadPoolExecutor的关系图简单如下。
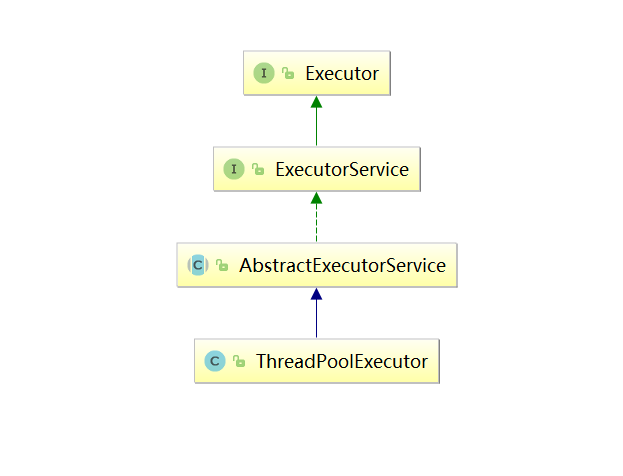
简单介绍一些Executor、ExecutorService、AbstractExectorService。
Executor接口比较简单:
public interface Executor {
void execute(Runnable command);
}
该接口只有一个方法,即任务的执行。
ExecutorService在Executor接口上,添加了管理生命周期的方法、支持了Callable类型的任务、任务的执行方式。

AbstractExecutorService是一个抽象类,实现了ExecutorService的任务执行方法,添加newTaskFor方法作为钩子对外提供任务的取消通道,但是AbstractExecutorService并没有实现生命周期管理相关的方法,而是将生命周期相关的操作丢给了子类。
线程池奋斗的一生
线程池的出生:
线程池有多种构造器,参数最完整的构造器如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize:核心线程数量。当对线程池中空闲线程进行回收的时候。假设线程池中线程的数量小于corePoolSize,则不会对线程进行回收。如果线程因为异常原因退出,如果线程退出后线程池的线程数量小于corePoolSize,则会对线程池添加一个线程。
maximumPoolSize:线程池的最大大小。当线程池中任务已经溢出,如果线程数量已经等于maximunPoolSize,线程池也不会在添加线程。
keepAliveTime:线程的空闲时间。如果线程池的线程数量已经大于corePoolSize,当线程空闲时间超过空闲时间,则该线程会被回收。
unit:线程空闲时间的时间单位。可以选择纳秒、微秒、毫秒、秒、分、小时、天为单位。
workQueue:工作队列。用于存储交付给线程池的任务。可以选择BlockingQueue的实现类来充当线程池的工作队列,newFixThreadExecutor和newSingleThreadExecutor默认采用的是无界的LinkedBlockingQueue来充当工作队列。更为稳妥的方式是选择一种有界的工作队列来存储。例如有界的LinkedBlockingQueue、ArrayBlockingQueue、PriorityBlockingQueue来充当消息队列,防止因为任务无止境的堆积导致内存溢出。newCachedThreadPool使用的是SynchronousQueue来充当队列,SynchronousQueue不是一个真正的消息队列,而已一个任务在线程正当中的移交机制。一般只有在线程池可以无限大,或者线程池可以拒绝任务的情况下使用SynchronousQueue。
threadFactory:线程工厂。每当线程池需要创建一个线程时,可以通过线程的工厂的new Thread方法来创建线程。可以通过自定义一个ThreadFactory来实现对线程的定制。
handler:拒绝机制。当线程池因为工作池已经饱和,准备拒绝任务时候。会调用RejectedExecutionHandler来拒绝该任务。Jdk提供了几种不同的RejectedExecutionHandler实现,每种实现都包含不同的饱和策略:AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy。
- Abort是默认的饱和策略,该策略会抛出未检查的RejectedExecutionException。
- CallerRuns实现一种调节机制,将任务回退到调用者,让调用者执行,从而降低了新任务的流量。webServer通过使用该策略使得在请求负载过高的情况下实现了性能的平缓降低。
- Discard实现了会悄悄抛弃该任务,DiscardOldestPolicy会抛弃队列中抛弃下一个即将被执行的任务。如果是在优先队列里,DiscardOldestPolicy会抛弃优先级最高的任务。
ThreadLocalPool的池的大小设置,《Java并发编程实战》书中给了一个推荐的设置值。
Ncpu为CPU的数量,Ucpu为CPU的利用率,W/C为任务的等待时间 / 任务的计算时间。在这种情况下,一般线程池的最优大小:
N=Ncpu*Ucpu*(1+W/C)
线程池创建也可以使用Executors来创建:
newFixedThreadPool:创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到最大线程数。如果因为异常导致未预期的异常结束。线程池将补充一个线程。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newCacheThreadPool:创建一个可缓存的线程池。该线程池核心线程数为0,最大线程为Integer.max_value。可以理解为该线程池规模没有任何限制。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newScheduledThreadPool:创建一个固定长度的线程池,已延迟或者定时方式来执行任务,类似于Timer。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
newSingleThreadExecutor:创建一个单线程的Executor来执行任务,能确保线程的执行顺序,例如FIFO、LIFO、优先顺序等。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
newWorkStealingPool:根据给定的并行等级,创建一个拥有足够的线程数目的线程池。
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
线程池的人生起落:
ThreadPoolExecutor中有一个ctl变量。ctl是一个32位的二级制数,其中高3位用于表示线程池的状态,低29位表示线程池中的活动线程。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1; private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
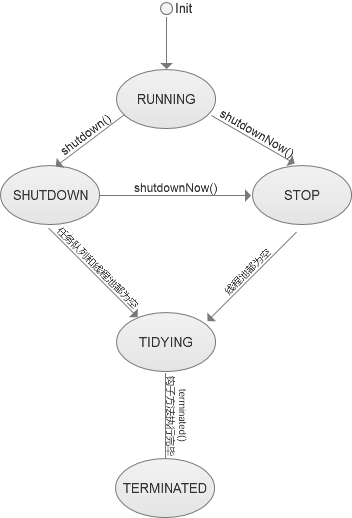
如上代码所示,线程池有五种状态。RUNNING、SHUTDOWN、STOP、TIDYING、TERMINNATED。幸好ThreadPoolExecutor的代码上有对应注释,看着这些注释能对ThreadPoolExecutor的状态作用和状态流转能有一个大致的了解。
RUNNING:在线程池创建的时候,线程池默认处于RUNNING状态。当线程池处于RUNNING状态的时候,任务队列可以接受任务,并且可以执行QUEUE中任务。
SHUTDOWN:不接受新任务,但是会继续执行QUEUE中的任务。
STOP:不接受新任务,也不执行QUEUE中的任务。
TIDYING:所有的任务都中止了,没有活动中的线程。当线程池进行该状态时候,会执行钩子方法terminated() 。
以下是各个状态对应的流转图:
线程池的寿终正寝:
上面有说过,ExecutorService在Executor接口上,添加了管理生命周期的方法。在ThreadPoolExecutor中,主要关闭动作有三个shutdown()、shutdownNow()、awaitTermination()。
shutdown()是一个平缓的关闭方式,线程池被调用了shutdown函数如果还有事做就会把状态设为SHUTDOWN,但是不会真的中止。
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查是否有关闭线程的权限
checkShutdownAccess();
//检查线程池状态、小于SHUTDOWN的用CAS的方式将线程池状态设置为SHUTDOWN
advanceRunState(SHUTDOWN);
//打断没事做的线程
interruptIdleWorkers()
//这个是ScheduledThreadPoolExecutor中用到的不,ThreadPoolExecutor中是个空的
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
//尝试中止,如果还有事做就不会中止
tryTerminate();
}
shutdownNow()跟shutdown()相似,但是shutdownNow()比起shutdown()更加粗暴。不管线程池中的线程有没有事做,直接把线程打断。并且状态会设置为STOP。状态设置为STOP后也表示无视任务队列里面是不是还有任务。shutdownNow()因为会关闭已经开始执行但是尚未结束的任务,所以使用shutdownNow()的时候如果需要知道每个任务被放弃时候的状态,就必须拓展任务,记录清楚任务中未成功执行完成的任务。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//检查线程池状态、小于SHUTDOWN的用CAS的方式将线程池状态设置为SHUTDOWN
advanceRunState(STOP);
//强行打断
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
awaitTermination(long timeout, TimeUnit unit)方法,用于进行等待,假设传入时间为60s,如果60s之后ThreadPoolExecutor状态变为TERMINATED,则返回ture,如果状态不为TERMINATED,则会返回false。通常调用玩shutdown()后会使用awaitTermination方法进行等待,确认线程池已经中止。
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
}
以上几个方法可以对线程池的状态进行操作。线程池还提供了isShutdown(),isTerminating(),isTerminated()对线程池的状态进行查询。
线程池核心工作方法
当我们要将一个任务提交给线程池时,一般调用的线程池的execute(Runnable command)方法。简单分析一下这个方法:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如何活动线程数量小于核心线程数量,则添加线程来处理该任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池在running状态,并且往任务队列里推送任务成功:
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//二次检查线程池已经关闭,任务队列删除任务,并拒绝任务
if (! isRunning(recheck) && remove(command))
reject(command);
//如果工作线程数为0,因为只有当corePoolSize==0的情况下才能走到这里,则此时添加一个非核心的工作者
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//走到这边,表示任务推送失败或者线程池已经关闭,添加工作线程,如果线程池已经关闭会返回false,则拒绝该任务
else if (!addWorker(command, false))
reject(command);
}
我们从这里可以看出来,当线程池中的活动线程大于或等于核心线程的时候,线程池是不会马上创建新的线程来执行任务的。只有线程池在任务队列中推送任务失败(任务队列已经满了)的时候才会创建额外的线程来执行任务。如果线程池已经关闭,或者任务队列和工作者已经满了的时候,线程池会开始拒绝任务。reject(command)会用上面说过的RejectedExecutionHandler来对任务进行拒绝。
这里的Worker是ThreadPoolExecutor的内部类,封装Thread类。它的核心方法也就是run()方法。我们来看一下Worker的run()方法,run()方法就是runWork()方法封装一下。这里的This值的是Worker自己。
public void run() {
runWorker(this);
}
这个是工作者的工作方法。
final void runWorker(ThreadPoolExecutor.Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//循环获取任务,getTask()会阻塞的从任务队列里拿任务,
while (task != null || (task = getTask()) != null) {
w.lock();
//判断线程池和线程的状态,是可以继续执行任务的
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//可拓展接口,任务执行前的动作
beforeExecute(wt, task);
Throwable thrown = null;
try {
//任务执行没啥好说
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//可拓展接口,任务执行前的动作
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//任务退出循环,根据是异常退出还是正常退出进行收尾
//对工作任务进行回收也在这里
processWorkerExit(w, completedAbruptly);
}
}
从队列中获取任务。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查线程池状态和队列是否为空,如果没任务可搞直接返回
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//判断线程池是否需要提出线程
// timed参数用于判断是否需要根据超时时间回收线程,
//如果允许核心线程回收或者线程数已经超过核心线程数,则为ture
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//工作者太多或者已经超时则干掉
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//根据上面的判断,让工作者线程阻塞读取直到被打断或者超时返回
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
线程工作者退出。
private void processWorkerExit(ThreadPoolExecutor.Worker w, boolean completedAbruptly) {
//如果不是因为异常原因导致线程退出,则不要进行Worker数量调整
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
//从工作队列中删除,让JVM可以对Worker进行回收
workers.remove(w);
} finally {
mainLock.unlock();
}
//尝试中止线程池
tryTerminate();
int c = ctl.get();
//线程池如果还在跑,线程异常退出,需要补充工作者,就对工作者进行补充。
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
上面的代码我就不细讲, 主要的流程就写了注释在上面。当年第一次听说线程池会回收空闲线程的时候就会好奇这个操作是怎么搞的,上面代码的workqueue.poll()就是关键,当线程可以回收,并且线程阻塞已经超时,则进行线程回收。
后记:
写这篇博客的时候,心情比较烦躁。听从朋友建议恶搞部分标题名,果然心情好很多。以后可以考虑在内容没歧义的前提下,文章部分也这么写。线程池在java中算是比较基础的内容,入行以来面试也被面了不少,但是一直没看过源码,最近看了一下发现确实学习到了不少东西,部分看懂了,部分因为水平不够没看懂的东西,部分看明白后有种还可以这么写的感慨。果然JAVA程序员要多看看JDK源码。
ThreadPoolExecutor 学习笔记的更多相关文章
- 并发编程学习笔记(14)----ThreadPoolExecutor(线程池)的使用及原理
1. 概述 1.1 什么是线程池 与jdbc连接池类似,在创建线程池或销毁线程时,会消耗大量的系统资源,因此在java中提出了线程池的概念,预先创建好固定数量的线程,当有任务需要线程去执行时,不用再去 ...
- 《Java学习笔记(第8版)》学习指导
<Java学习笔记(第8版)>学习指导 目录 图书简况 学习指导 第一章 Java平台概论 第二章 从JDK到IDE 第三章 基础语法 第四章 认识对象 第五章 对象封装 第六章 继承与多 ...
- Android(java)学习笔记267:Android线程池形态
1. 线程池简介 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力. 假设一个服务器完成一项任务所需时间为:T1 创建线程时间, ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- Springboot学习笔记(六)-配置化注入
前言 前面写过一个Springboot学习笔记(一)-线程池的简化及使用,发现有个缺陷,打个比方,我这个线程池写在一个公用服务中,各项参数都定死了,现在有两个服务要调用它,一个服务的线程数通常很多,而 ...
- Android(java)学习笔记211:Android线程池形态
1. 线程池简介 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力. 假设一个服务器完成一项任务所需时间为:T1 创建线程时间, ...
- 并发编程学习笔记(15)----Executor框架的使用
Executor执行已提交的 Runnable 任务的对象.此接口提供一种将任务提交与每个任务将如何运行的机制(包括线程使用的细节.调度等)分离开来的方法.通常使用 Executor 而不是显式地创建 ...
- 图灵学院JAVA互联网架构师专题学习笔记
图灵学院JAVA互联网架构师专题学习笔记 下载链接:链接: https://pan.baidu.com/s/1xbxDzmnQudnYtMt5Ce1ONQ 密码: fbdj如果失效联系v:itit11 ...
- SpringBoot学习笔记(十七:异步调用)
@ 目录 1.@EnableAsync 2.@Async 2.1.无返回值的异步方法 2.1.有返回值的异步方法 3. Executor 3.1.方法级别重写Executor 3.2.应用级别重写Ex ...
随机推荐
- WebStorm开发工具设置React Native智能提示
最近在做React Native开发的时候,相信大家一般会使用WebStorm,Sublime,Atom等等开发工具.二之前搞前端的对WebStorm会很熟悉,WebStorm最新版是WebStorm ...
- UVa - 116 - Unidirectional TSP
Background Problems that require minimum paths through some domain appear in many different areas of ...
- 【Qt编程】Qt学习之Window and Dialog Widgets
Qt Creator 提供的默认基类只要QMainWindow.QWidget和QDialog三种.其中,QMainWindow是带有菜单栏和工具栏的主窗口类,QDialog是各种对话框的基类,这两个 ...
- droid invalidate和postinvalidate的区别
Android提供了Invalidate方法实现界面刷新,但是Invalidate不能直接在线程中调用,因为他是违背了单线程模型:Android UI操作并不是线程安全的,并且这些操作必须在UI线程中 ...
- Java 条形码生成(一维条形码)
utl:http://mianhuaman.iteye.com/blog/1013945 在这里给大家介绍一个java 生成条形码 jbarcode.jar 生成条形码 支持EAN13, EAN8, ...
- 根据分析查看相关知识点分析iOS 三种录制视频方式
这篇文章讨论了关于如何配置视频捕获管线 (pipeline) 和最大限度地利用硬件性能的一些不同选择. 这里有个使用了不同管线的样例 app,可以在 GitHub 查看. 第一种:UIImagePic ...
- LeetCode之“动态规划”:Maximum Product Subarray
题目链接 题目要求: Find the contiguous subarray within an array (containing at least one number) which has t ...
- LDA
2 Latent Dirichlet Allocation Introduction LDA是给文本建模的一种方法,它属于生成模型.生成模型是指该模型可以随机生成可观测的数据,LDA可以随机生成一篇由 ...
- uc伯克利人工分割图像.seg文件解析
之前看到 http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/segbench/ 提供的人工图像分割的.seg格式 ...
- MQ队列与哪些机器连接
1.使用MQ安装用户登录Linux,例如:su - mqm 2.runmqsc Qm1 #Queue 代表要查询的队列3.DISPLAY CONN(*) WHERE(OBJNAME EQ Queue) ...