Java内存管理及对Java对象管理
Java内存管理及对Java对象管理
1Java内存管理
1.1Java中的堆和栈
通常来说,人们会将Java内存氛围栈内存(Stack)和堆内存(Heap)。
栈内存用来保存基本类型的变量和对象的引用变量。Java虚拟机栈是线程私有的。Java栈是Java方法执行的内存模型每个方法在执行的同时都会创建一个栈帧的用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法从调用直至执行完成的过程就对应着一个栈帧在虚拟机中入栈和出栈的过程。
堆内存用来存放由new创建的对象实例和数组。Java堆是被所有线程共享的一块内存区域,也是垃圾收集器管理的主要区域。
1.1.1堆和栈的联系
当在堆中产生了一个数组或者对象时,可以在栈中定义一个特殊的变量,让栈中的这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或者对象,引用变量就相当于是为数组或者对象起的一个名称。引用变量是普通的变量,定义时在栈中分配,引用变量在程序运行到其作用域之外后被释放。而数组和对象本身在堆中分配,即使程序运行到使用new产生数组或者对象的语句所在的代码块之外,数组和对象本身占据的内存不会被释放,数组和对象在没有引用变量指向它的时候,才变为垃圾,不能在被使用,但仍然占据内存空间不放,在随后的一个不确定的时间被垃圾回收器收走(释放掉)。例如:
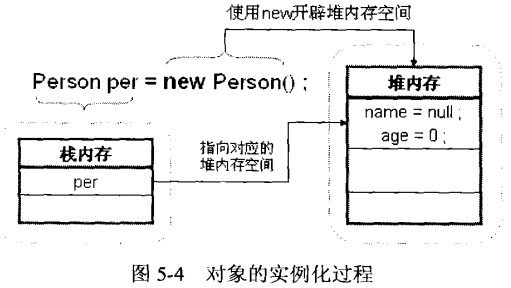
由上图我们发现,对象名称per被保存在了栈内存中,具体实例保存在堆内存中。也就是说,在栈内存中保存的是堆内存空间的访问地址,或者说栈中的变量指向堆内存中的变量(Java中的指针)。
1.1.2堆和栈的比较
从堆和栈的功能和作用来通俗的比较,堆主要用来存放对象的,栈主要是用来执行程序的.而这种不同又主要是由于堆和栈的特点决定的:
在编程中,例如C/C++中,所有的方法调用都是通过栈来进行的,所有的局部变量,形式参数都是从栈中分配内存空间的。实际上也不是什么分配,只是从栈顶向上用就行,就好像工厂中的传送带一样,Stack Pointer会自动指引你到放东西的位置,你所要做的只是把东西放下来就行.退出函数的时候,修改栈指针就可以把栈中的内容销毁.这样的模式速度最快, 当然要用来运行程序了.需要注意的是,在分配的时候,比如为一个即将要调用的程序模块分配数据区时,应事先知道这个数据区的大小,也就说是虽然分配是在程序运行时进行的,但是分配的大小多少是确定的,不变的,而这个"大小多少"是在编译时确定的,不是在运行时.
堆是应用程序在运行的时候请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率非常低.但是堆的优点在于,编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间,因此,用堆保存数据时会得到更大的灵活性。事实上,面向对象的多态性,堆内存分配是必不可少的,因为多态变量所需的存储空间只有在运行时创建了对象之后才能确定.在C++中,要求创建一个对象时,只需用 new命令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存.当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间。
1.2运行时的数据区域
Java虚拟机在执行Java程序过程中会把它所管理的内存划分位若干个不同的数据区域。这些区域都有各自的用途,以及创建和销毁时间。如下图所示:
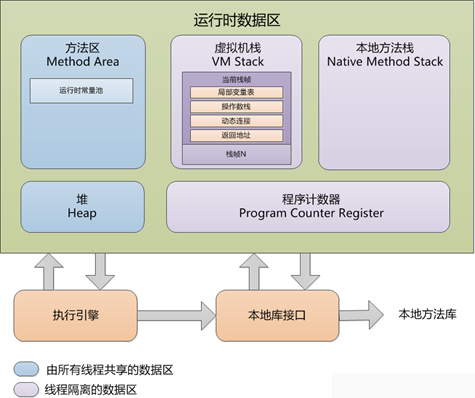
- 程序计数器:是一块较小的内存空间,用作当前线程所执行的字节码的信号指示器。每个线程都有独立的程序计数器。
- Java虚拟机栈:即1.1中的栈内存。
- 本地方法栈:Java虚拟机可能会使用到传统的栈来支持native方法(如JNI)的执行,这个栈就是本地方法栈(Native Method Stack)。
- Java堆:即1.1中的堆内存,线程共享。
- 方法区(Method Area):方法区是可供各条线程共享的运行时内存区域。存储了每一个类的结构信息,例如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的字节码内容、还包括一些在类、实例、接口初始化时用到的特殊方法。
- 运行时常量池(Runtime Constant Pool):方法区的一部分,是每一个类或接口的常量池(Constant_Pool)的运行时表现形式,它包括了若干种常量:编译器可知的数值字面量到必须运行期解析后才能获得的方法或字段的引用。
2对象管理机制
接下来探讨以hotspot虚拟机在Java堆中对象分配、布局和访问的全过程。
2.1对象创建
- 类加载:虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过的。如果没有,那必须先执行相应的类加载过程。
- 内存分配:对象所需内存的大小在类加载完成后便可完全确定(如何确定在下一节对象内存布局时再详细讲解),为对象分配空间的任务具体便等同于一块确定大小的内存从Java堆中划分出来。两种分配方法:“指针碰撞”法和“空闲列表”法。选择哪种分配方式由Java堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。因此在使用Serial、ParNew等带Compact过程的收集器时,系统采用的分配算法是指针碰撞,而使用CMS这种基于Mark-Sweep算法的收集器时,就通常采用空闲列表。
- 将内存空间初始化为零值。
- 对象信息的必要设置:如设置对象头信息。
- init对象:按程序员的医院初始化对象。
2.2对象的内存布局
对象在内存中存储有三个区域:对象头,实例数据,对其填充* 对象头:第一部分为对象自身的运行数据,如哈希码,GC分代年龄等;第二部分为类型指针,即对象指向它的类愿数据的指针,从而虚拟机可以确定这个对象是哪个类的实例。* 实例数据:对象真正存储的有效信息。* 对齐填充:占位符,如,补全为8字节的倍数。
2.3对象的访问定位
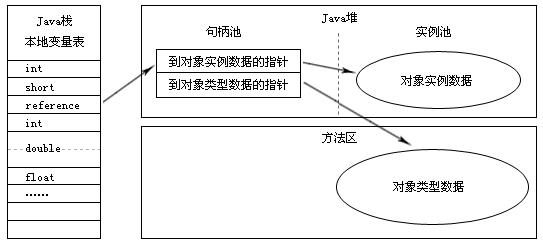
如1.1.2小节中所述,Java程序通过栈上的reference数据来操作堆上的具体对象。目前主流的访问方式由“使用句柄”和“直接指针”。
- 如果使用句柄访问的话,Java堆中将会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据的具体各自的地址信息。如下图:
- 如果使用直接指针访问的话,Java堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址,如下图:
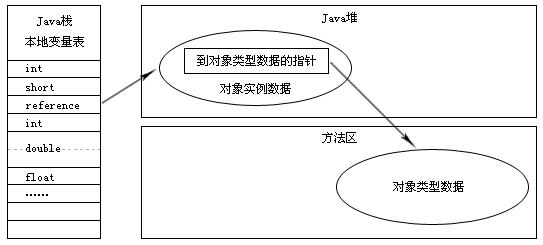
使用句柄来访问的最大好处就是reference中存储的是稳定句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要被修改。
使用直接指针来访问最大的好处就是速度更快,它节省了一次指针定位的时间开销,由于对象访问的在Java中非常频繁,因此这类开销积小成多也是一项非常可观的执行成本。
Java内存管理及对Java对象管理的更多相关文章
- java内存区域分析及java对象的创建
java虚拟机在执行java程序的过程中会将它管理的内存区域加分为若干个的不同的数据区域. 主要包括以下几个运行时数据区域,这里就只介绍经常会用到的 1:java虚拟机栈:我们常说的堆栈,栈就是指的j ...
- 02 | Java内存模型:看Java如何解决可见性和有序性问题
什么是 Java 内存模型? 导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决可见性. 有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了. 合理 ...
- Java内存管理特点
Java内存管理特点 Java一个最大的优点就是取消了指针,由垃圾收集器来自动管理内存的回收.程序员不需要通过调用函数来释放内存. 1.Java的内存管理就是对象的分配和释放问题. 在 ...
- Java内存区域与对象创建过程
一.java内存区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有的区域则 ...
- 深入理解Java虚拟机读书笔记1----Java内存区域与HotSpot虚拟机对象
一 Java内存区域与HotSpot虚拟机对象 1 Java技术体系.JDK.JRE? Java技术体系包括: · Java程序设计语言: · 各种硬件平台上的 ...
- Java内存模型与垃圾回收
1.Java内存模型 Java虚拟机在执行程序时把它管理的内存分为若干数据区域,这些数据区域分布情况如下图所示: 程序计数器:一块较小内存区域,指向当前所执行的字节码.如果线程正在执行一个Java方法 ...
- java内存模型及分块
转自:http://www.cnblogs.com/BangQ/p/4045954.html 1.JMM简介 2.堆和栈 3.本机内存 4.防止内存泄漏 1.JMM简介 i.内存模型概述 Ja ...
- Java内存区域和GC机制篇
Java内存区域和GC机制一.目录 1.Java垃圾回收概括 2.Java内存区域 3.Java对象的访问方式 4.Java内存访问机制 5.Java GC 机制 6.Java垃圾收集器 二.Java ...
- Java内存泄漏分析与解决方案
Java内存泄漏是每个Java程序员都会遇到的问题,程序在本地运行一切正常,可是布署到远端就会出现内存无限制的增长,最后系统瘫痪,那么如何最快最好的检测程序的稳定性,防止系统崩盘,作者用自已的亲身经历 ...
- JAVA内存模型与线程
概述 由于计算机的运算速度和它的存储和通讯子系统的速度差距巨大,大部分时间都花在IO,网络和数据库上.为了压榨CPU的运算能力,需要并发.另外,优秀的并发程序对于提高服务器的TPS有重要的意义. 硬件 ...
随机推荐
- 中国IT职业培训市场经历的几波浪潮,未来的浪潮又是那一波?
第一波 电脑普及性培训时代 2000年至2003年左右,中国正处于PC计算机普及阶段,而IT职业教育也刚开始兴起,这一波浪潮主要以计算机办公自动化.平面设计.计算机硬件维修.为主:几家大的IT培训机构 ...
- Ubuntu系统怎么切换多用户命令界面
ctrl+alt+F2~F6 切换窗口 返回桌面 Ctrl+Alt+F7
- 【JS】数据类型
其他类型转化为boolean类型规则: number:非0为true,0和NaN为false: String:非空为true,空为false: Object:任何对象都为true 任何变量赋值为nul ...
- Kendo UI使用笔记
1.Grid中的列字段绑定模板字段方法参数传值字符串加双引号: 上图就是个典型的例子,openSendWin方法里Id,EmergencyTitle,EmergencyDetail 三个参数,后两个参 ...
- Golang 网络爬虫框架gocolly/colly 四
Golang 网络爬虫框架gocolly/colly 四 爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟.回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫, ...
- python (5分钟实现一个游戏的屏蔽敏感字系统,)
import datetime time=datetime.datetime.now() dirty= ['fuck','狗日的','犊子','麻批','仙人板板','R你妈','操你','草你',' ...
- 冒烟测试与BVT测试
冒烟测试,它和回归测试的性质一样--只是一个测试活动,并不是一个测试阶段.冒烟测试贯穿于测试的任何一个阶段,单元测试.集成测试.系统测试里都有冒烟测试. 冒烟测试和其他所有的测试活动的目的不一样,它不 ...
- tar: This does not look like a tar archive tar: Skipping to next header tar: Exiting with failure status due to previous errors
解压一个.tar.zip文件时报错 tar -zxvf bcl2fastq2-v2---linux-x86-.zip tar: This does not look like a tar archiv ...
- C语言--解引用
昨天,在<C和指针>上面看到"解引用"这个名词,就好奇的去查了查. (下面是一个大一渣渣的理解,请各位朋友海涵,如果有漏洞或者补充希望前辈不吝指正.) 例: #incl ...
- 程序包管理rpm、yum与简单编译安装程序
Linux程序包管理 Linux中软件的安装主要有两种形式:一种是直接下载源代码包自行编译后安装,另一种直接获取rpm软件包进行安装. 程序的组成部分: 二进制程序:程序的主体文件,比如我们运行一个l ...