Linux 3.2中回写机制的变革
本文出自 “存储之道” 博客,请务必保留此出处http://alanwu.blog.51cto.com/3652632/1109952
初始化默认的后备存储器default_backing_dev_info
- static int __init default_bdi_init(void)
- {
- int err;
- /*创建同步每个后备存储器的超级块的线程*/
- sync_supers_tsk = kthread_run(bdi_sync_supers, NULL, "sync_supers");
- BUG_ON(IS_ERR(sync_supers_tsk));
- /*初始化一个定时器,该定时器控制同步超级块的周期,每隔dirty_writeback_interval去唤醒一次sync_supers_tsk,从而同步超级块。
- dirty_writeback_interval可以通过修改/proc/sys/vm/下的dirty_writeback_centisecs来修改,默认值是500,单位是10ms
- 定时器函数sync_supers_timer_fn用于唤醒同步超级块的线程sync_supers_tsk,并且更新定时器的到期时间,具体实现如下*/
- setup_timer(&sync_supers_timer, sync_supers_timer_fn, 0);
- /*用于更新定时器的到期时间,详见下面代码。*/
- bdi_arm_supers_timer();
- /*初始化default_backing_dev_info的成员变量,初始化相关的链表,相关的变量赋初值等操作,请读者自行阅读。*/
- err = bdi_init(&default_backing_dev_info);
- if (!err)
- /*调用bdi_register注册默认的后备存储器default_backing_dev_info到bdi_list链表,并创建默认的backing_dev_info管理线程,
- 用于管理其他的后备存储器的数据同步线程的创建和销毁,所有的后备存储器在初始化时都会调用bdi_register注册到bdi_list链表中。
- bdi_register详见下文分析。*/
- bdi_register(&default_backing_dev_info, NULL, "default");
- /*初始化空的后备存储器,可以忽略。*/
- err = bdi_init(&noop_backing_dev_info);
- return err;
- }
sync_supers_timer_fn函数唤醒超级块数据同步线程,然后重设定时器。
- static void sync_supers_timer_fn(unsigned long unused)
- {
- wake_up_process(sync_supers_tsk);
- bdi_arm_supers_timer();
- }
bdi_arm_supers_timer函数重设定时器
- void bdi_arm_supers_timer(void)
- {
- unsigned long next;
- if (!dirty_writeback_interval)
- return;
- next = msecs_to_jiffies(dirty_writeback_interval * 10) + jiffies;
- mod_timer(&sync_supers_timer, round_jiffies_up(next));
- }
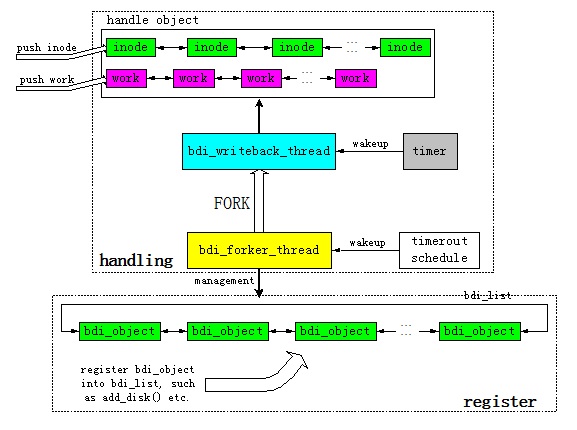
三、bdi_register()函数分析
bdi_register函数用于注册后备存储器到全局链表bdi_list上,并且判断如果是默认的后备存储器default_backing_dev_info则创建bdi-default线程,用于管理创建或销毁所有后备存储器相关的同步回写线程。
- int bdi_register(struct backing_dev_info *bdi, struct device *parent,
- const char *fmt, ...)
- {
- va_list args;
- struct device *dev;
- if (bdi->dev) /*
The driver needs to use separate queues per device */ - return 0;
- va_start(args, fmt);
- dev = device_create_vargs(bdi_class, parent, MKDEV(0, 0), bdi, fmt, args);
- va_end(args);
- if (IS_ERR(dev))
- return PTR_ERR(dev);
- bdi->dev = dev;
- /*
- * Just start the forker thread for our default backing_dev_info,
- * and add other bdi's to the list. They will get a thread created
- * on-demand when they need it.
- */
- if (bdi_cap_flush_forker(bdi)) {
- struct bdi_writeback *wb = &bdi->wb;
- wb->task = kthread_run(bdi_forker_thread, wb, "bdi-%s",
- dev_name(dev));
- if (IS_ERR(wb->task))
- return PTR_ERR(wb->task);
- }
- bdi_debug_register(bdi, dev_name(dev));
- set_bit(BDI_registered, &bdi->state);
- spin_lock_bh(&bdi_lock);
- list_add_tail_rcu(&bdi->bdi_list, &bdi_list);
- spin_unlock_bh(&bdi_lock);
- trace_writeback_bdi_register(bdi);
- return 0;
- }
Linux 3.2中回写机制的变革的更多相关文章
- Linux页快速缓存与回写机制分析
參考 <Linux内核设计与实现> ******************************************* 页快速缓存是linux内核实现的一种主要磁盘缓存,它主要用来降低 ...
- linux块设备的IO调度算法和回写机制
************************************************************************************** 參考: <Linux ...
- linux下数据同步、回写机制分析
一.前言在linux2.6.32之前,linux下数据同步是基于pdflush线程机制来实现的,在linux2.6.32以上的版本,内核彻底删掉了pdflush机制,改为了基于per-bdi线程来实现 ...
- 【转】linux设备驱动程序中的阻塞机制
原文网址:http://www.cnblogs.com/geneil/archive/2011/12/04/2275272.html 阻塞与非阻塞是设备访问的两种方式.在写阻塞与非阻塞的驱动程序时,经 ...
- rabbitMQ的简单实例——amqp协议带数据回写机制
rabbitMQ是一种高性能的消息队列,支持或者说它实现了AMQP协议(advanced message queue protocol高级消息队列协议). 下面简单讲一讲一个小例子.我们首先要部署好r ...
- linux x86内核中的分页机制
Linux采用了通用的四级分页机制,所谓通用就是指Linux使用这种分页机制管理所有架构的分页模型,即便某些架构并不支持四级分页.对于常见的x86架构,如果系统是32位,二级分页模型就可满足系统需求: ...
- Linux内核设计与实现 总结笔记(第十六章)页高速缓存和页回写
页高速缓存是Linux内核实现磁盘缓存.磁盘告诉缓存重要源自:第一,访问磁盘的速度要远远低于访问内存. 第二,数据一旦被访问,就很有可能在短期内再次被访问到.这种短时期内集中访问同一片数据的原理称作临 ...
- 多线程中的信号机制--signwait()函数【转】
本文转载自:http://blog.csdn.net/yusiguyuan/article/details/14237277 在Linux的多线程中使用信号机制,与在进程中使用信号机制有着根本的区别, ...
- 《Linux内核设计与实现》读书笔记(十六)- 页高速缓存和页回写
好久没有更新了... 主要内容: 缓存简介 页高速缓存 页回写 1. 缓存简介 在编程中,缓存是很常见也很有效的一种提高程序性能的机制. linux内核也不例外,为了提高I/O性能,也引入了缓存机制, ...
随机推荐
- Dollar Dayz poj3181
http://poj.org/problem?id=3181 这个题目一开始就能看出来是个dp问题,但是我并没有一开始就看出来是一个完全背包为题,只是想着根据以前的方法,这个问题应该是可以找到规律的, ...
- linux内核链表---挑战常规思维
一.普通链表 1.一般教材上的链表定义如下: struct node{ int content: node *next: }: 它将指针域放在链表节点中,上一个节点指针域中的值指向下一个节点的首地址, ...
- 更加 "深入" 理解多态
1.1 public abstract class Birds{ //什么样的方法是抽象方法 public abstract void Fly(); } public class YZ:Birds{ ...
- 在VM中给Linux安装Tool
1.导入tool 2.解压tool 3.打开终端,进入tool的目录,输入 ./XXXXXXX.pl 4.进入安装界面,不断回车即可
- C# const和readonly修饰符的区别
const 的概念就是一个包含不能修改的值的变量.常数表达式是在编译时可被完全计算的表达式.因此不能从一个变量中提取的值来初始化常量.如果 const int a = b+1;b是一个变量,显然不能再 ...
- java学习笔记 --- 抽象类
一.抽象类 (1)定义: 把多个共性的东西提取到一个类中,这是继承的做法. 但是呢,这多个共性的东西,在有些时候,方法声明一样,但是方法体. 也就是说,方法声明一样,但是每个具体的对象在具体实现的时候 ...
- Struts2之Action与配置文件
一.Struts2配置文件 1.struts.properties 在学习Action之前先学下Struts2的配置文件,与Struts2相关的配置文件有好几个,常用的有Struts.xml,web. ...
- shell学习指南-阅读笔记
shell学习指南真不是刚开始学习shell应该看得书,虽然其中讲了简单的linux命令,shell语法等,但是每章也有些深入和生僻地方,我想如果我刚学shell看到这样的地方一定会头疼的要死.或许也 ...
- node.js下mongoose简单操作实例
Mongoose API : http://mongoosejs.com/docs/api.html // mongoose 链接var mongoose = require('mongoose'); ...
- ActiveMQ Part 1 : 基本安装配置(windows 版本)
1. 安装启动服务 A) 首先下载并安装最新的 JDK(本文使用:jdk-8u66-windows-x64.exe) B) 从官网下载最新的安装包(本文下载版本为:http://activemq.ap ...