SQL Server-聚焦ROW_NUMBER VS TOP N性能
前言
抱歉各位,从八月份开始一直在着手写EntityFramework 6.x和EntityFramework Core 2.0的书籍写作,所以最近一直遗漏了对博客的管理,后面会着手于写SQL Server、EntityFramework Core和.NET Core方面的博客。我们知道如果需要查询前N行数据,除了可以利用TOP N进行查询外,同样也可以利用ROW_NUMBER来达到同样的效果,那么二者使用哪个性能会更好呢?下面我们来比较下。
ROW_NUMBER VS TOP N
我们利用AdventureWorks2012示例库中的Production.Product表来进行演示,如下:
DBCC DROPCLEANBUFFERS()
DBCC FREEPROCCACHE()
GO --ROW_NUMBER QUERY
SELECT ProductID
FROM (
SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN
FROM Production.Product
) AS T
WHERE T.RN <= 100
GO -- TOP N QUERY
SELECT
TOP 100 ProductID
FROM Production.Product
ORDER BY ProductID
GO
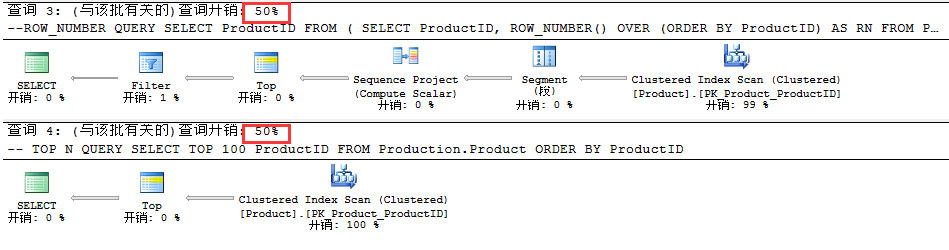
如上图所知,对于这两个查询计划的成本是一样的,都为50%。 如果我们要检查在两个聚集索引扫描操作符中读取的估计行数,那么我们会注意到两者都显示相同的值,即100。可以说聚集索引扫描的估计和实际行数是相同的都是100,如下。
是不是就以此说明二者性能是一样的呢?稍等片刻,接下来我们将查询基数再设置大一点看看,比如1000而不再是100,如下:
DBCC DROPCLEANBUFFERS()
DBCC FREEPROCCACHE()
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
--ROW_NUMBER QUERY
SELECT ProductID
FROM (
SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN
FROM Production.Product
) AS T
WHERE T.RN <= 1000
GO -- TOP N QUERY
SELECT
TOP 1000 ProductID
FROM Production.Product
ORDER BY ProductID
GO

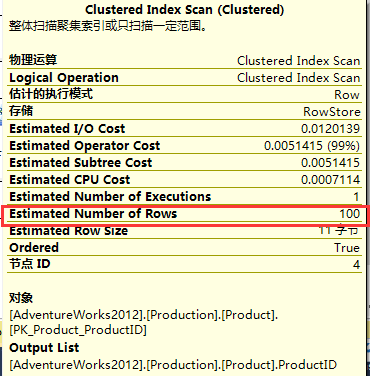
从如上截图可以看出,使用ROW_NUMBER进行查询的速度要明显快于TOP N,即29%和71%。 但是,我们还需要在等一下,因为我们在这里看到的成本只是估计成本。 如果操作的估算不准确,那么查询计划估算成本也将不准确。 接下来我们检查两个计划中的聚集索引扫描的属性:

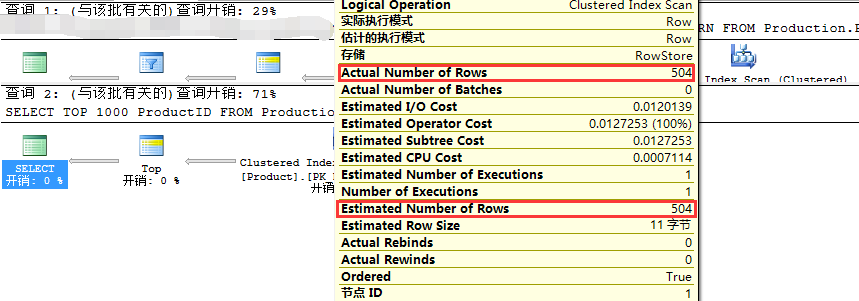
我们可以看到,使用ROW_NUMBER查询的估计行数为100,而实际数量为504,查询计划的估计成本是基于估计的行数所计算得来,即100。我们还是不能够相信估计的计划成本。 我们再来看看统计数据:

经过上面的统计,我们可以根据统计数据而做出最终决定,而不是比较执行计划的估计成本。TOP N的查询性能优于ROW_NUMBER。
总结
从上比较TOP N和ROW_NUMBER的查询得知,查询计划所得到的成本并不是判断性能的最终依据,只是基础性的判断,我们最终还得集合IO和TIME等来综合判断性能差异。
SQL Server-聚焦ROW_NUMBER VS TOP N性能的更多相关文章
- SQL Server 分组后取Top N
SQL Server 分组后取Top N(转) 近日,工作中突遇一需求:将一数据表分组,而后取出每组内按一定规则排列的前N条数据.乍想来,这本是寻常查询,无甚难处.可提笔写来,终究是困住了笔者好一会儿 ...
- SQL Server数据库ROW_NUMBER()函数使用详解
SQL Server数据库ROW_NUMBER()函数使用详解 摘自:http://database.51cto.com/art/201108/283399.htm SQL Server数据库ROW_ ...
- SQL Server调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server 中ROW_NUMBER() OVER基本用法
1.不能排序法 * FROM table1 WHERE id NOT IN ( SELECT TOP 开始的位置 id FROM table1 ) 2.SQL 2000 临时表法 DECLARE @S ...
- SQL Server 调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server 2008内存及I/O性能监控
来源: it168 发布时间: 2011-04-12 11:04 阅读: 10820 次 推荐: 1 原文链接 [收藏] 以下均是针对Window 32位系统环境下,64位的不在下面 ...
- SQL Server分页的存储过程写法以及性能比较
------创建数据库data_Test ----- create database data_Test GO use data_Test GO create table tb_TestTable - ...
- SQL Server中使用Check约束提升性能
在SQL Server中,SQL语句的执行是依赖查询优化器生成的执行计划,而执行计划的好坏直接关乎执行性能. 在查询优化器生成执行计划过程中,需要参考元数据来尽可能生成高效的执行计划, ...
- SQL Server中一个隐性的IO性能杀手-Forwarded record
简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一 ...
随机推荐
- 八、Hadoop学习笔记————调优之Hive调优
表1表2的join和表3表4的join同时运行 此法需要关注是否有数据倾斜(大量数据集中在某一区间段)
- JS弹窗带遮蔽的功能
很不错的JS原生自定义弹窗,很实用! function myAlert(str,click,useCancel){ var overflow=""; var $hidder=nul ...
- ShoneSharp语言(S#)的设计和使用介绍系列(2)— 掀开盖头
ShoneSharp语言(S#)的设计和使用介绍 系列(2)- 掀开盖头 作者:Shone 声明:原创文章欢迎转载,但请注明出处,https://www.cnblogs.com/ShoneSharp. ...
- 【MySQL疑难杂症】如何将树形结构存储在数据库中(方案一、Adjacency List)
今天来看看一个比较头疼的问题,如何在数据库中存储树形结构呢? 像mysql这样的关系型数据库,比较适合存储一些类似表格的扁平化数据,但是遇到像树形结构这样有深度的人,就很难驾驭了. 举个栗子:现在有一 ...
- CCF-201509-2-日期计算
问题描述 试题编号: 201509-2 试题名称: 日期计算 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 给定一个年份y和一个整数d,问这一年的第d天是几月几日? 注意闰年 ...
- Centos7 下安装Docke
为什么 要用centos7呢. 现在哪个企业用的是centos7呀.不都是老版本么. 对咱们是新技术.所以只有新系统才可以用.因为docker要求服务CentOS6以上,kernel 版本必须2.6. ...
- Spark之导出PMML文件(Python)
PMML,全称预言模型标记语言(Predictive Model Markup Language),利用XML描述和存储数据挖掘模型,是一个已经被W3C所接受的标准.PMML是一种基于XML的语言,用 ...
- vue.js介绍,常用指令,事件,以及制作简易留言版
一.vue是什么? 一个mvvm框架(库).和angular类似,比较容易上手.小巧,让我们的代码更加专注于业务逻辑,而不是去关注DOM操作 二.vue和angular之间的区别 vue--简单易学 ...
- Java二分法
public class Dichotomy { //定义查找次数 static int count = 0; public static void main(Str ...
- BZOJ 1032 JSOI2007 祖码Zuma 动态规划
题目大意:给定一个祖玛序列,任选颜色射♂出珠子,问最少射♂出多少珠子 输入法近期越来越奇怪了0.0 首先我们把连续同样的珠子都缩在一起 令f[i][j]表示从i開始的j个珠子的最小消除次数 初值 f[ ...