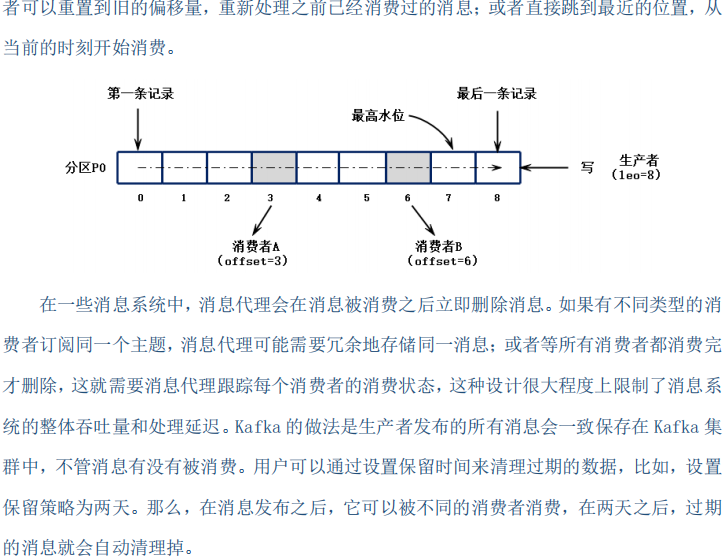
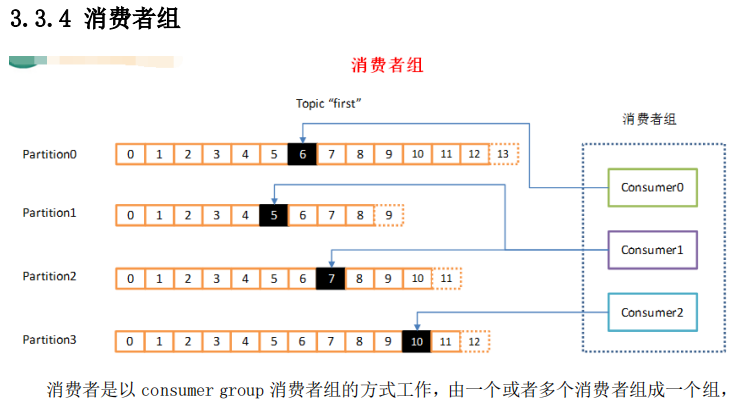
kafka的api操作(官网http://kafka.apache.org/documentation/#producerapi)










Kafka API 简单用法
本篇会用到以下依赖:(本人包和这个不同,去maven里查找)
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.10.2.0</version>
</dependency>



package com.yjsj.kafka;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class OldProducer {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("metadata.broker.list", "master:9092");
properties.put("request.required.acks", "1");
properties.put("serializer.class",
"kafka.serializer.StringEncoder");
Producer<Integer, String> producer = new Producer<Integer,String>(new
ProducerConfig(properties));
KeyedMessage<Integer, String> message = new KeyedMessage<Integer,
String>("first", "hello world");
producer.send(message );
}
}


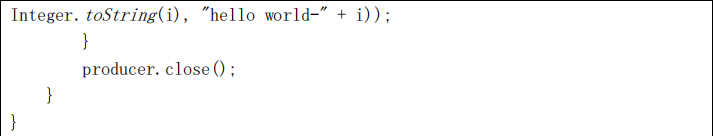
package com.yjsj.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class NewProducer {
public static void main(String[] args) {
Properties props = new Properties();
// Kafka 服务端的主机名和端口号
props.put("bootstrap.servers", "master:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key 序列化
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// value 序列化
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 50; i++) {
producer.send(new ProducerRecord<String, String>("first",
Integer.toString(i), "hello world-" + i));
}
producer.close();
}
}

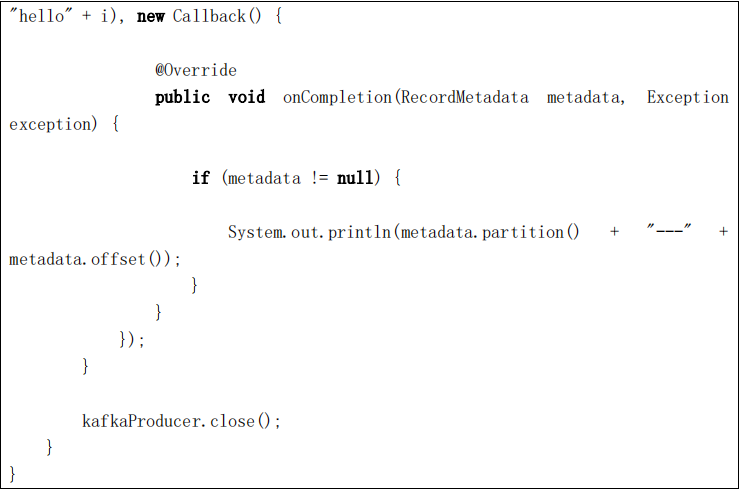
for (int i = 0; i < 50; i++) {
kafkaProducer.send(new ProducerRecord<String, String>("first",
"hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception
exception) {
if (metadata != null) {
System.out.println(metadata.partition() + "---" +
metadata.offset());
}
}
});
}
kafkaProducer.close();
}
}



package com.yjsj.kafka;
import java.util.Map;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object
value, byte[] valueBytes, Cluster cluster) {
// 控制分区
return 0;
}
@Override
public void close() {
}
}



package com.yjsj.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class PartitionerProducer {
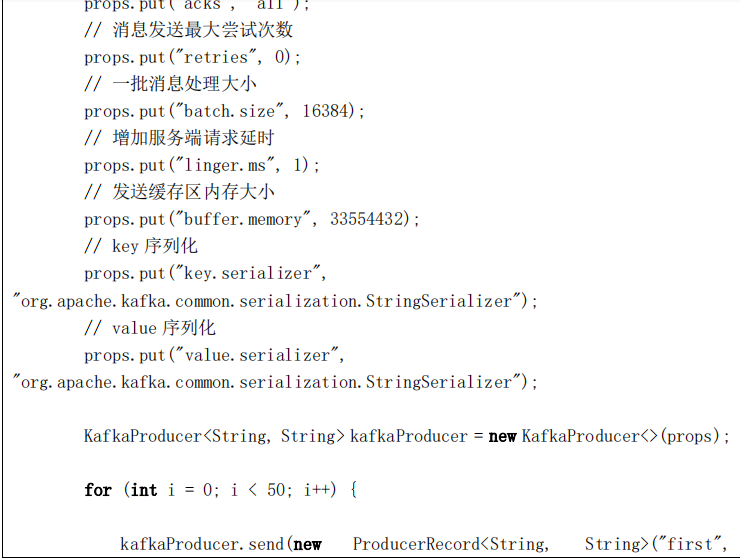
public static void main(String[] args) {
Properties props = new Properties();
// Kafka 服务端的主机名和端口号
props.put("bootstrap.servers", "node1:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 增加服务端请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key 序列化
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// value 序列化
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 自定义分区
props.put("partitioner.class", "com.yjsj.kafka.CustomPartitioner");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<String, String>("first", "1",
"hadoop"));
producer.close();
}
}








package com.yjsj.kafka.consume;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class CustomNewConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 定义 kakfa 服务的地址,不需要将所有 broker 指定上
props.put("bootstrap.servers", "master:9092");
// 制定 consumer group
props.put("group.id", "test");
// 是否自动确认 offset
props.put("enable.auto.commit", "true");
// 自动确认 offset 的时间间隔
props.put("auto.commit.interval.ms", "1000");
// key 的序列化类
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
// value 的序列化类
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
// 定义 consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅的 topic, 可同时订阅多个
consumer.subscribe(Arrays.asList("first", "second","third"));
while (true) {
// 读取数据,读取超时时间为 100ms
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
}
}




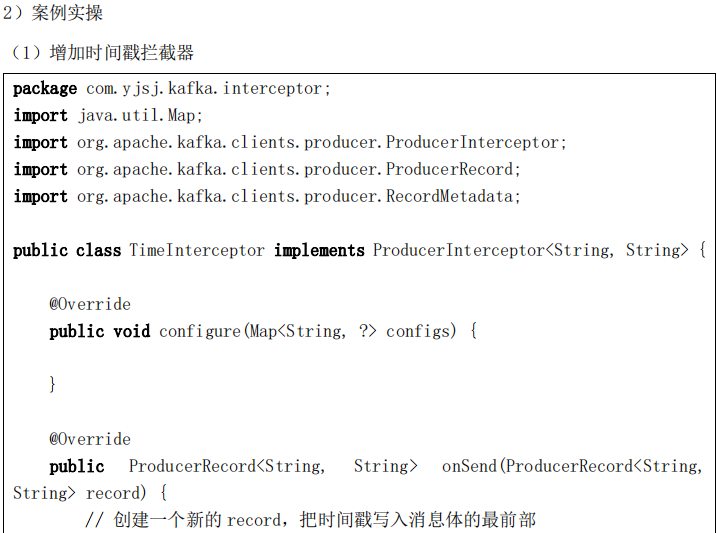



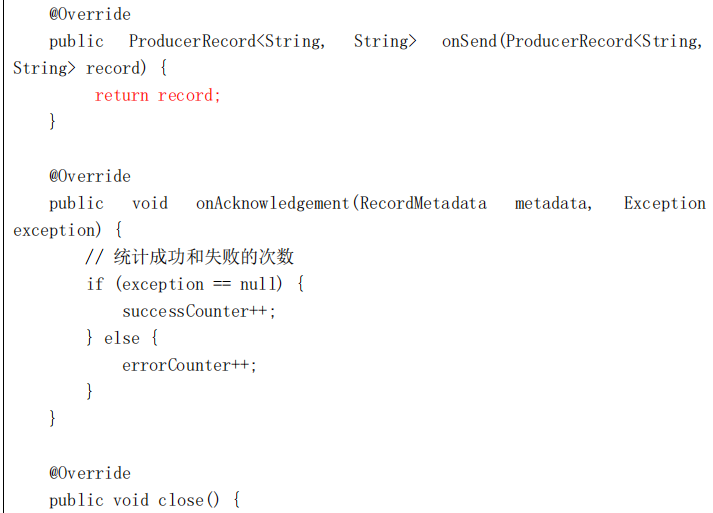

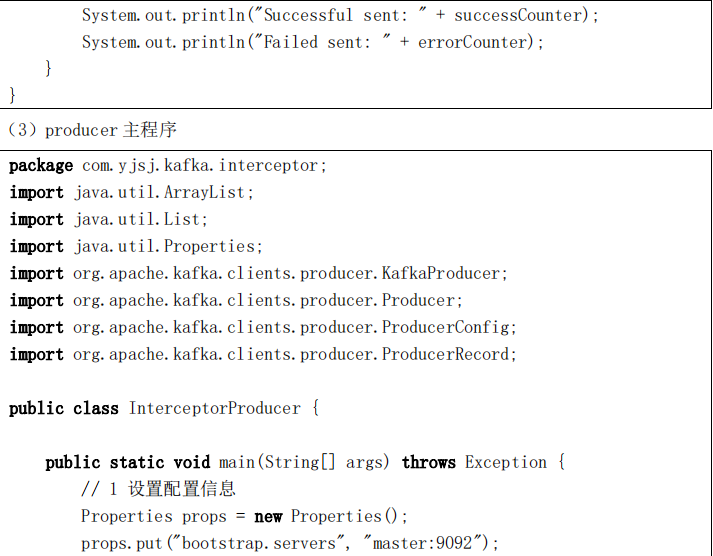















package com.yjsj.kafka.stream;
import java.util.Properties;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder;
public class Application {
public static void main(String[] args) {
// 定义输入的 topic
String from = "first";
// 定义输出的 topic
String to = "second";
// 设置参数
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092");
StreamsConfig config = new StreamsConfig(settings);
// 构建拓扑
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", from)
.addProcessor("PROCESS", new ProcessorSupplier<byte[],
byte[]>() {
@Override
public Processor<byte[], byte[]> get() {
// 具体分析处理
return new LogProcessor();
}
}, "SOURCE")
.addSink("SINK", to, "PROCESS");
// 创建 kafka stream
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
具体业务处理
package com.yjsj.kafka.stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
public class LogProcessor implements Processor<byte[], byte[]> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(byte[] key, byte[] value) {
String input = new String(value);
// 如果包含“>>>”则只保留该标记后面的内容
if (input.contains(">>>")) {
input = input.split(">>>")[1].trim();
// 输出到下一个 topic
context.forward("logProcessor".getBytes(), input.getBytes());
}else{
context.forward("logProcessor".getBytes(), input.getBytes());
}
}
@Override
public void punctuate(long timestamp) {
}
@Override
public void close() {
}
}
kafka的api操作(官网http://kafka.apache.org/documentation/#producerapi)的更多相关文章
- 1.1 Introduction中 Kafka for Stream Processing官网剖析(博主推荐)
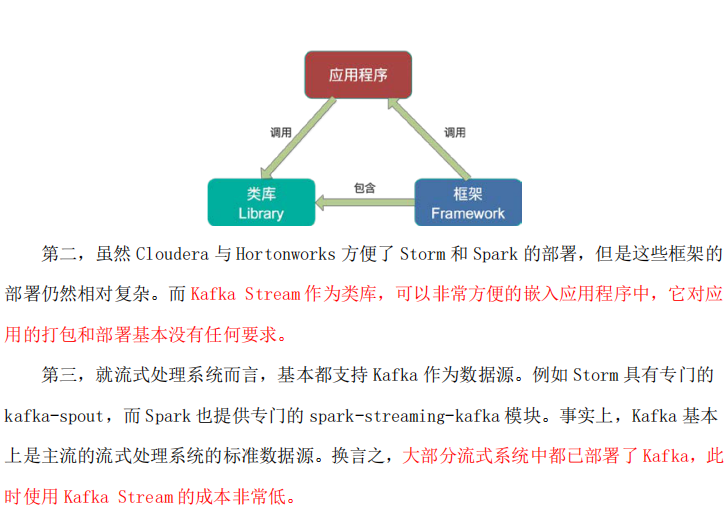
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Kafka for Stream Processing kafka的流处理 It i ...
- Kafka(五)Kafka的API操作和拦截器
一 kafka的API操作 1.1 环境准备 1)在eclipse中创建一个java工程 2)在工程的根目录创建一个lib文件夹 3)解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的 ...
- kafka (搜索) 在idea api操作(官方apihttp://kafka.apache.org/documentation/#producerapi)
https://blog.csdn.net/isea533/article/details/73822881 这个不推荐,可以看一下(https://www.cnblogs.com/b ...
- 有用的官方API和官网
1.Bootstrap API:http://www.runoob.com/bootstrap/bootstrap-tutorial.html 2.百度地图API示例:http://lbsyun.ba ...
- apache官网怎样下载apache HTTP Server服务器
我相信有些朋友刚用apache服务器时,都希望从官网上下载,而面对着官网上众多的项目和镜像以及目录,也许有点茫然.下面是具体步骤 第一步:打开apache官网 第二步:点击右上角Download,出现 ...
- Kafka 0.8翻译官网精华.md
1主要的设计元素 Kafka之所以和其它绝大多数信息系统不同,是因为下面这几个为数不多的比较重要的设计决策: Kafka在设计之时为就将持久化消息作为通常的使用情况进行了考虑. 主要的设计约束是吞吐量 ...
- Kafka Java API操作topic
Kafka官方提供了两个脚本来管理topic,包括topic的增删改查.其中kafka-topics.sh负责topic的创建与删除:kafka-configs.sh脚本负责topic的修改和查询,但 ...
- kafka的API操作
在集群的接收端 启动producer 在consumer这边能接收到producer发来的数据
- Asp.Net Web API 2 官网菜鸟学习系列导航[持续更新中]
详情请查看http://aehyok.com/Blog/Detail/67.html 个人网站地址:aehyok.com QQ 技术群号:206058845,验证码为:aehyok 本文文章链接:ht ...
随机推荐
- JavaScript中的可枚举属性与不可枚举属性
在JavaScript中,对象的属性分为可枚举和不可枚举之分,它们是由属性的enumerable值决定的.可枚举性决定了这个属性能否被for…in查找遍历到. 一.怎么判断属性是否可枚举 js中基本包 ...
- 何用glmnet或lars包进行feature selection
#datalibrary(lars)data(diabetes)attach(diabetes) #glmnetlibrary(glmnet)library(foreach)library(Matri ...
- 第八篇 实例化Flask的参数 及 对app的配置
Flask 是一个非常灵活且短小精干的web框架 , 那么灵活性从什么地方体现呢? 有一个神奇的东西叫 Flask配置 , 这个东西怎么用呢? 它能给我们带来怎么样的方便呢? 首先展示一下: from ...
- /etc/rc5.d/s991local: line25: eject:command not found错误
使用虚拟机安装centos出现错误,原因是我使用的镜像是最小级别的,没有图形化界面,只有终端窗口 有人用vmware安装minimal centos报错/etc/rc5.d/s99local : ...
- java多线程-慎重使用volatile关键字
Java语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量.这两种机制的提出都是为了实现代码线程的安全性.其中 Volatile 变量的同步性较差(但有时它更简单并且开销更低),而 ...
- 词法解析 用reactjs和bootstrap创建页面IDE
- 刷题向》一道逆向思维题(BZOJ1046)(NORMAL)
这道题对于一类题都有一个通用思路:反向递减序列即为正向字典序. 对于逆向思维的题还要多做才能培养这种对于逆向思维的感觉. 想到这种方法之后,就很简单了. 因为n×m不会炸,所以反向LIS叠一个贪心就能 ...
- Linux系统profile、bashrc、bash_profile等环境设置文件的使用
一.前言 关于bash的环境设置文件,分为系统设置和个人设置,一般来说建议用户直接修改个人的设置. 本文测试环境为:centos6.5. 二.系统设置值 1. /etc/sysconfig/i18n ...
- ajax+servlet 简易时间效果
<!DOCTYPE html> <html> <head> <title>index.html</title> <meta name= ...
- code1074 食物链
开3*n的并查集,其中x用来连接与x同类的,x+n用来连接x吃的,x+2*n用来连接x被吃的. 1 x y时,如果 x吃y 或 x被y吃,那么为假话, 否则x与y同类,x吃的y也吃,x被吃的y也被吃: ...