Spring Data 分页和排序 PagingAndSortingRepository的使用(九)
继承PagingAndSortingRepository
我们可以看到,BlogRepository定义了这样一个方法:Page<Blog> findByDeletedFalse(Pageable pageable);,我们主要关注它的参数以及返回值。
- Pageable 是Spring Data库中定义的一个接口,该接口是所有分页相关信息的一个抽象,通过该接口,我们可以得到和分页相关所有信息(例如
pageNumber、pageSize等),这样,Jpa就能够通过pageable参数来得到一个带分页信息的Sql语句。 - Page类也是Spring Data提供的一个接口,该接口表示一部分数据的集合以及其相关的下一部分数据、数据总数等相关信息,通过该接口,我们可以得到数据的总体信息(数据总数、总页数...)以及当前数据的信息(当前数据的集合、当前页数等)
Spring Data Jpa除了会通过命名规范帮助我们扩展Sql语句外,还会帮助我们处理类型为Pageable的参数,将pageable参数转换成为sql'语句中的条件,同时,还会帮助我们处理类型为Page的返回值,当发现返回值类型为Page,Spring Data Jpa将会把数据的整体信息、当前数据的信息,分页的信息都放入到返回值中。这样,我们就能够方便的进行个性化的分页查询。
分页:
package org.springdata.repository;
import org.springdata.domain.Employee;
import org.springframework.data.repository.PagingAndSortingRepository;
/**
*/
public interface EmployeePadingAndSortingResponstory extends PagingAndSortingRepository<Employee,Integer> {
}
编写测试类
package org.springdata.crudservice;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.springdata.domain.Employee;
import org.springdata.repository.EmployeePadingAndSortingResponstory;
import org.springdata.service.CrudEmployeeService;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import java.util.List;
/**
*/
public class PagingAndSortingRespositoryTest {
private ApplicationContext ctx = null;
private EmployeePadingAndSortingResponstory employeePadingAndSortingResponstory = null;
@Before
public void setup(){
ctx = new ClassPathXmlApplicationContext("beans_news.xml");
employeePadingAndSortingResponstory = ctx.getBean(EmployeePadingAndSortingResponstory.class);
System.out.println("setup");
}
@After
public void tearDown(){
ctx = null;
System.out.println("tearDown");
}
@Test
public void testPage(){
//index 1 从0开始 不是从1开始的
Pageable page = new PageRequest(0,10);
Page<Employee> employeeList = employeePadingAndSortingResponstory.findAll(page);
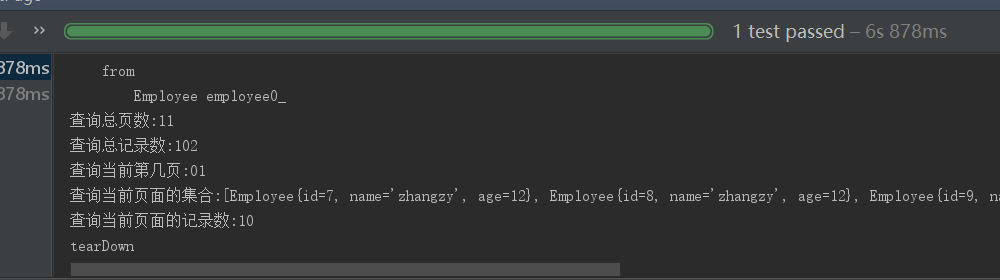
System.out.println("查询总页数:"+employeeList.getTotalPages());
System.out.println("查询总记录数:"+employeeList.getTotalElements());
System.out.println("查询当前第几页:"+employeeList.getNumber()+1);
System.out.println("查询当前页面的集合:"+employeeList.getContent());
System.out.println("查询当前页面的记录数:"+employeeList.getNumberOfElements());
}
}
查询结果 咱们先在Employee 实体类 重写下toString()方法 才能打印集合数据
排序:
基于上面的查询集合 我们新建一个测试方法
@Test
public void testPageAndSord(){
//根据id 进行降序
Sort.Order order = new Sort.Order(Sort.Direction.DESC,"id");
Sort sort = new Sort(order);
//index 1 从0开始 不是从1开始的
Pageable page = new PageRequest(0,10,sort);
Page<Employee> employeeList = employeePadingAndSortingResponstory.findAll(page);
System.out.println("查询总页数:"+employeeList.getTotalPages());
System.out.println("查询总记录数:"+employeeList.getTotalElements());
System.out.println("查询当前第几页:"+employeeList.getNumber()+1);
System.out.println("查询当前页面的集合:"+employeeList.getContent());
System.out.println("查询当前页面的记录数:"+employeeList.getNumberOfElements());
}
 我们可以看到 最大id 排前面了
我们可以看到 最大id 排前面了
Spring Data 分页和排序 PagingAndSortingRepository的使用(九)的更多相关文章
- 整合Spring Data JPA与Spring MVC: 分页和排序
之前我们学习了如何使用Jpa访问关系型数据库.比较完整Spring MVC和JPA教程请见Spring Data JPA实战入门,Spring MVC实战入门. 通过Jpa大大简化了我们对数据库的开发 ...
- 整合Spring Data JPA与Spring MVC: 分页和排序pageable
https://www.tianmaying.com/tutorial/spring-jpa-page-sort Spring Data Jpa对于分页以及排序的查询也有着完美的支持,接下来,我们来学 ...
- Spring data JPA先排序再分页。
//工具类,增删改查等等package com.yunqing.service.impl; import java.util.Map; import org.springframework.beans ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 了解 Spring Data JPA
前言 自 JPA 伴随 Java EE 5 发布以来,受到了各大厂商及开源社区的追捧,各种商用的和开源的 JPA 框架如雨后春笋般出现,为开发者提供了丰富的选择.它一改之前 EJB 2.x 中实体 B ...
- Spring Data JPA
转自: http://www.cnblogs.com/WangJinYang/p/4257383.html Spring 框架对 JPA 的支持 Spring 框架对 JPA 提供的支持主要体现在如下 ...
- 使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- Spring Data JPA 梳理 - 使用方法
1.下载需要的包. 需要先 下载Spring Data JPA 的发布包(需要同时下载 Spring Data Commons 和 Spring Data JPA 两个发布包,Commons 是 Sp ...
- Spring Data JPA基本了解
前言 自 JPA 伴随 Java EE 5 发布以来,受到了各大厂商及开源社区的追捧,各种商用的和开源的 JPA 框架如雨后春笋般出现,为开发者提供了丰富的选择.它一改之前 EJB 2.x 中实体 B ...
随机推荐
- GetLastError 错误码大全(转载)
转载自:GetLastError GetLastError GetLastError返回的值通过在api函数中调用SetLastError或SetLastErrorEx设置.函数 并无必要设置上一 ...
- cocosbuilder的一些坑
主要是大小写问题 在扁平发布模式下,如果存在大小写不同的文件,文件会被替换掉.而模拟上运行没问题,在真机上运行 有问题.找了半天才发现,坑啊!
- java Web监听器导图详解
监听器是JAVA Web开发中很重要的内容,其中涉及到的知识,可以参考下面导图: Web监听器 1 什么是web监听器? web监听器是一种Servlet中的特殊的类,它们能帮助开发者监听web中的特 ...
- Odoo 8.0 new API 概述
相对于7来说,8的api改进了不少,用官方的话来说就是更加面向对象了. 下面探究一下具体的改动. 准备知识:python装饰器的使用 http://blog.csdn.net/thy38/articl ...
- Java反射机制的基本概念与使用
本篇文章分为以下几个部分: 1.认识反射 2.反射的源头(Class类) 3.利用反射操作构造方法 4.利用反射调用类中的方法 5.反射中的invoke方法 6.利用反射调用类中的属性 反射在我们普通 ...
- 为什么对一些矩阵做PCA得到的矩阵少一行?
很多时候会出现把一个N*M的矩阵做pca(对M降维)之后却得到一个M*(M-1)矩阵这样的结果.之前都是数学推导得到这个结论,但是, 今天看到一个很形象的解释: Consider what PCA d ...
- EasyUI 表单 tree
第一步:创建HTML标记 <divid="dlg"style="padding:20px;"> <h2>Account Info ...
- Unity UGUI实现Button按钮长按状态的判断
代码: using UnityEngine.EventSystems; using System.Collections; /// <summary> /// 脚本位置:UGUI按钮组件身 ...
- EF报LINQ to Entities 不识别方法“Web_JZRepository.Models.copy_materials_details get_Item(Int32) ”,因此该方法无法转换为存储表达式。
说明用了如 List<T> list=new List<T>(); je.copy_materials_details.SingleOrDefault(x => x.ID ...
- hdu 1058:Humble Numbers(动态规划 DP)
Humble Numbers Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...