Hadoop案例(八)辅助排序和二次排序案例(GroupingComparator)
辅助排序和二次排序案例(GroupingComparator)
1.需求
有如下订单数据
|
订单id |
商品id |
成交金额 |
|
0000001 |
Pdt_01 |
222.8 |
|
0000001 |
Pdt_05 |
25.8 |
|
0000002 |
Pdt_03 |
522.8 |
|
0000002 |
Pdt_04 |
122.4 |
|
0000002 |
Pdt_05 |
722.4 |
|
0000003 |
Pdt_01 |
222.8 |
|
0000003 |
Pdt_02 |
33.8 |
现在需要求出每一个订单中最贵的商品。
2.数据准备
GroupingComparator.txt
Pdt_01 222.8
Pdt_05 722.4
Pdt_05 25.8
Pdt_01 222.8
Pdt_01 33.8
Pdt_03 522.8
Pdt_04 122.4
输出数据预期:
222.8
part-r-00000.txt
722.4
part-r-00001.txt
222.8
part-r-00002.txt
3.分析
(1)利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce。
(2)在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值。
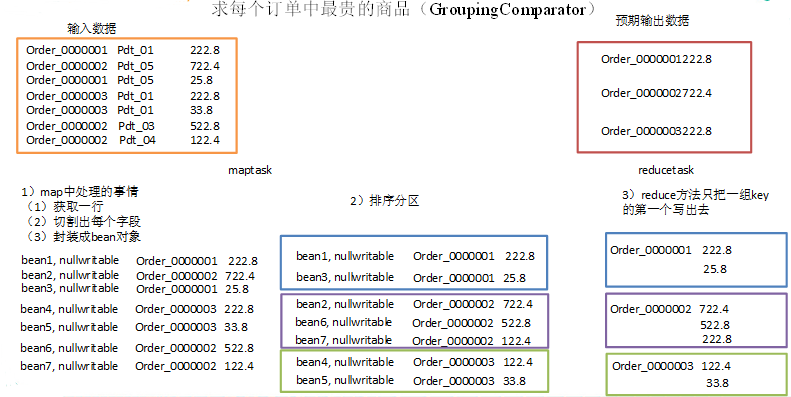
4.实现
定义订单信息OrderBean
package com.xyg.mapreduce.order; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable; public class OrderBean implements WritableComparable<OrderBean> { private int order_id; // 订单id号
private double price; // 价格 public OrderBean() {
super();
} public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
} @Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
} @Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
price = in.readDouble();
} @Override
public String toString() {
return order_id + "\t" + price;
} public int getOrder_id() {
return order_id;
} public void setOrder_id(int order_id) {
this.order_id = order_id;
} public double getPrice() {
return price;
} public void setPrice(double price) {
this.price = price;
} // 二次排序
@Override
public int compareTo(OrderBean o) { int result = order_id > o.getOrder_id() ? : -; if (order_id > o.getOrder_id()) {
result = ;
} else if (order_id < o.getOrder_id()) {
result = -;
} else {
// 价格倒序排序
result = price > o.getPrice() ? - : ;
} return result;
}
}
编写OrderSortMapper处理流程
package com.xyg.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 封装对象
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 写出
context.write(k, NullWritable.get());
}
}
编写OrderSortReducer处理流程
package com.xyg.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer; public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
编写OrderSortDriver处理流程
package com.xyg.mapreduce.order; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OrderDriver { public static void main(String[] args) throws Exception, IOException { // 1 获取配置信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); // 2 设置jar包加载路径
job.setJarByClass(OrderDriver.class); // 3 加载map/reduce类
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class); // 4 设置map输出数据key和value类型
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class); // 5 设置最终输出数据的key和value类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class); // 6 设置输入数据和输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); // 10 设置reduce端的分组
job.setGroupingComparatorClass(OrderGroupingComparator.class); // 7 设置分区
job.setPartitionerClass(OrderPartitioner.class); // 8 设置reduce个数
job.setNumReduceTasks(); // 9 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? : );
}
} OrderSortDriver
编写OrderSortPartitioner处理流程
package com.xyg.mapreduce.order;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class OrderPartitioner extends Partitioner<OrderBean, NullWritable> { @Override
public int getPartition(OrderBean key, NullWritable value, int numReduceTasks) {
return (key.getOrder_id() & Integer.MAX_VALUE) % numReduceTasks;
}
}
编写OrderSortGroupingComparator处理流程
package com.xyg.mapreduce.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; public class OrderGroupingComparator extends WritableComparator { protected OrderGroupingComparator() {
super(OrderBean.class, true);
} @SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a, WritableComparable b) { OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b; int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
} return result;
}
}
Hadoop案例(八)辅助排序和二次排序案例(GroupingComparator)的更多相关文章
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
转载:http://blog.tianya.cn/m/post.jsp?postId=53271442 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了 ...
- MapReduce之GroupingComparator分组(辅助排序、二次排序)
指对Reduce阶段的数据根据某一个或几个字段进行分组. 案例 需求 有如下订单数据 现在需要找出每一个订单中最贵的商品,如图 需求分析 利用"订单id和成交金额"作为key,可以 ...
- python 实现排序算法(二)-合并排序(递归法)
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Nov 21 22:28:09 201 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- python 实现Hadoop的partitioner和二次排序
我们知道,一个典型的Map-Reduce过程包 括:Input->Map->Partition->Reduce->Output. Partition负责把Map任务输出的中间结 ...
- Hadoop(八)Hadoop数据压缩与企业级优化
一 Hadoop数据压缩 1.1 概述 压缩技术能够有效减少底层存储系统(HDFS)读写字节数.压缩提高了网络带宽和磁盘空间的效率.在Hadood下,尤其是数据规模很大和工作负载密集的情况下,使用数据 ...
随机推荐
- 前端解放生产力之–动画(Adobe Effects + bodymovin + lottie)
大概很久很久以前,2017年,参加了第二届中国前端开发者大会(FDCon2017),除了看了一眼尤雨溪,印象最深刻的就是手淘渚薰分享的关于H5交互的内容了.时光荏苒,最近再次接触,简单回顾一下. 示例 ...
- Codeforces 585.D Lizard Era: Beginning
D. Lizard Era: Beginning time limit per test 2 seconds memory limit per test 256 megabytes input sta ...
- 手脱nSPack 3.7
方法一: 1. OD查壳—nSpack3.7的壳 2. 载入OD 看起来很眼熟,F8一次,然后下面就可以使用ESP定律了,使用ESP定律下断点,然后F9四次 3. F9四次后落到这个位置 接下 ...
- RabbitMQ的基础介绍
转自:http://blog.csdn.net/whycold/article/details/41119807 一.引言 你是否遇到过两个(多个)系统间需要通过定时任务来同步某些数据?你是否在为异构 ...
- js知识点乱炖
修改属性 元素.style.样式=值 document.getElementById('box').style.width='200px'; 属性操作方式 1.. 的 元素.属性名如果属性是单 ...
- struts2验证规则validation配置文件命名方式总结
1.Action级别校验命名格式: ActionClassName-validation.xml 2.Action中某个方法的校验命名格式: ActionClassName-ActionAliasNa ...
- HDU 1811 拓扑排序 并查集
有n个成绩,给出m个分数间的相对大小关系,问是否合法,矛盾,不完全,其中即矛盾即不完全输出矛盾的. 相对大小的关系可以看成是一个指向的条件,如此一来很容易想到拓扑模型进行拓扑排序,每次检查当前入度为0 ...
- C++面试中可能考察的基础知识(1)
1 C++中允许函数的嵌套调用,但不允许函数的嵌套定义 2 构建派生类对象时,先调用基类的构造函数,在调用成员对象的构造函数,最后调用派生类构造函数. 3 volatile关键字 volatile提醒 ...
- MAC泛洪攻击
先来解释一下啥是泛洪攻击 交换机里有一张专门记录MAC地址的表,为了完成数据的快速转发,该表具有自动学习机制:泛洪攻击即是攻击者利用这种学习机制不断发送不同的MAC地址给交换机,充满整个MAC表,此时 ...
- python并发编程之Queue线程、进程、协程通信(五)
单线程.多线程之间.进程之间.协程之间很多时候需要协同完成工作,这个时候它们需要进行通讯.或者说为了解耦,普遍采用Queue,生产消费模式. 系列文章 python并发编程之threading线程(一 ...