Hive的三种Join方式
Hive的三种Join方式
Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示。
参考链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
Common/Shuffle/Reduce Join
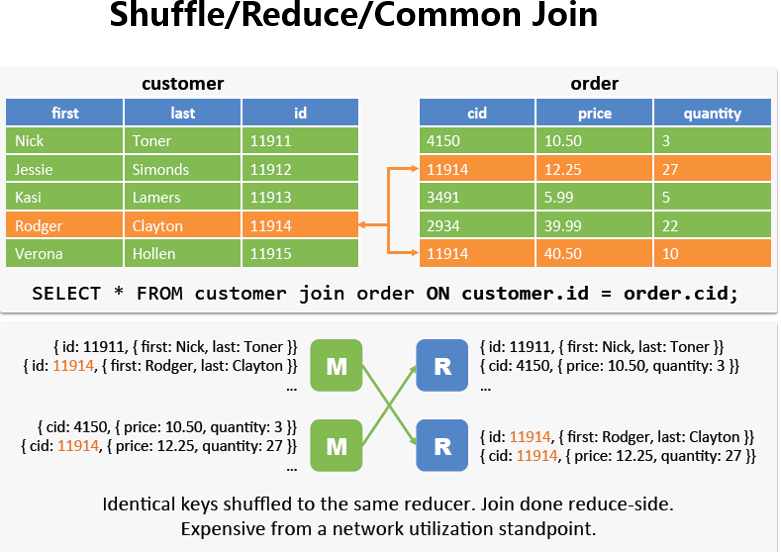
Reduce Join在Hive中也叫Common Join或Shuffle Join
如果两边数据量都很大,它会进行把相同key的value合在一起,正好符合我们在sql中的join,然后再去组合,如图所示。
Map Join
- 1) 大小表连接:
-
如果一张表的数据很大,另外一张表很少(<1000行),那么我们可以将数据量少的那张表放到内存里面,在map端做join。
Hive支持Map Join,用法如下
select /*+ MAPJOIN(time_dim) */ count(1) from
store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
- 2) 需要做不等值join操作(a.x < b.y 或者 a.x like b.y等)
-
这种操作如果直接使用join的话语法不支持不等于操作,hive语法解析会直接抛出错误
如果把不等于写到where里会造成笛卡尔积,数据异常增大,速度会很慢。甚至会任务无法跑成功~
根据mapjoin的计算原理,MapJoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
select /*+ MAPJOIN(a) */
a.start_level, b.*
from dim_level a
join (select * from test) b
where b.xx>=a.start_level and b.xx<end_level;
3) MAPJOIN 结合 UNIONALL
原始sql:
select a.*,coalesce(c.categoryid,’NA’) as app_category
from (select * from t_aa_pvid_ctr_hour_js_mes1
) a
left outer join
(select * fromt_qd_cmfu_book_info_mes
) c
on a.app_id=c.book_id;
速度很慢,老办法,先查下数据分布:
select *
from
(selectapp_id,count(1) cnt
fromt_aa_pvid_ctr_hour_js_mes1
group by app_id) t
order by cnt DESC
limit 50;
数据分布如下:
NA 617370129
2 118293314
1 40673814
d 20151236
b 1846306
s 1124246
5 675240
8 642231
6 611104
t 596973
4 579473
3 489516
7 475999
9 373395
107580 10508
我们可以看到除了NA是有问题的异常值,还有appid=1~9的数据也很多,而这些数据是可以关联到的,所以这里不能简单的随机函数了。而t_qd_cmfu_book_info_mes这张app库表,又有几百万数据,太大以致不能放入内存使用mapjoin。
解决方:首先将appid=NA和1到9的数据存入一组,并使用mapjoin与维表(维表也限定appid=1~9,这样内存就放得下了)关联,而除此之外的数据存入另一组,使用普通的join,最后使用union all 放到一起。
select a.*,coalesce(c.categoryid,’NA’) as app_category
from --if app_id isnot number value or <=9,then not join
(select * fromt_aa_pvid_ctr_hour_js_mes1
where cast(app_id asint)>9
) a
left outer join
(select * fromt_qd_cmfu_book_info_mes
where cast(book_id asint)>9) c
on a.app_id=c.book_id
union all
select /*+ MAPJOIN(c)*/
a.*,coalesce(c.categoryid,’NA’) as app_category
from –if app_id<=9,use map join
(select * fromt_aa_pvid_ctr_hour_js_mes1
where coalesce(cast(app_id as int),-999)<=9) a
left outer join
(select * fromt_qd_cmfu_book_info_mes
where cast(book_id asint)<=9) c
--if app_id is notnumber value,then not join
on a.app_id=c.book_id
- 设置:
-
当然也可以让hive自动识别,把join变成合适的Map Join如下所示
注:当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
set hive.auto.convert.join=true;
select count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
SMB(Sort-Merge-Buket) Join
- 场景:
-
大表对小表应该使用MapJoin,但是如果是大表对大表,如果进行shuffle,那就要人命了啊,第一个慢不用说,第二个容易出异常,既然是两个表进行join,肯定有相同的字段吧。
-
tb_a - 5亿(按排序分成五份,每份1亿放在指定的数值范围内,类似于分区表)
a_id
100001 ~ 110000 - bucket-01-a -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000 -
tb_b - 5亿(同上,同一个桶只能和对应的桶内数据做join)
b_id
100001 ~ 110000 - bucket-01-b -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000 -
注:实际生产环境中,一天的数据可能有50G(举例子可以把数据弄大点,比如说10亿分成1000个bucket)。
- 原理:
-
在运行SMB Join的时候会重新创建两张表,当然这是在后台默认做的,不需要用户主动去创建,如下所示:
-

设置(默认是false):
set hive.auto.convert.sortmerge.join=true
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
- 总结:
-
其实在写程序的时候,我们就可以知道哪些是大表哪些是小表,注意调优。
Hive的三种Join方式的更多相关文章
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- Hive metastore三种配置方式
http://blog.csdn.net/reesun/article/details/8556078 Hive的meta数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储.远端存储比较适 ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- 数据库常见的三种join方式
数据库常见的join方式有三种:inner join, left outter join, right outter join(还有一种full join,因不常用,本文不讨论).这三种连接方式都是将 ...
- Hive之 hive的三种使用方式(CLI、HWI、Thrift)
Hive有三种使用方式——CLI命令行,HWI(hie web interface)浏览器 以及 Thrift客户端连接方式. 1.hive 命令行模式 直接输入/hive/bin/hive的执行程 ...
- Oracle中的三种Join 方式
基本概念 Nested loop join: Outer table中的每一行与inner table中的相应记录join,类似一个嵌套的循环. Sort merge join: 将两个表排序,然后再 ...
- corss、inner、outer三种join方式
cross join(没有on)inner join(一般用于交集)outer join(你懂得)后面两个 on 1=1 效果同cross join
- MapReduce三种join实例分析
本文引自吴超博客 实现原理 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下: Map端的主要工作:为来自不同 ...
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
随机推荐
- ObjectId
BSON Types — MongoDB Manual https://docs.mongodb.com/manual/reference/bson-types/#objectid ObjectId ...
- React中ref的用法
在React数据流中,父子组件唯一的通信方式是通过props属性:那么如果有些场景需要获取某一个真实的DOM元素来交互,这时候就要用到React的refs属性. 1.可以给DOM元素添加ref属性 c ...
- Django 框架之 URL
URL配置就像Django所支撑网站的目录.它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表. # 示例: urlpatterns = [ path(route, view, kwa ...
- Sqoop简介及使用
一.Sqoop概述 1)官网 http://sqoop.apache.org/ 2)场景 传统型缺点,分布式存储.把传统型数据库数据迁移. Apache Sqoop(TM)是一种用于在Apache H ...
- linux知识体系
0. Linux简介与厂商版本 1. Linux开机启动 2. Linux文件管理 3. Linux的架构 4. Linux命令行与命令 5. Linux文件管理相关命令 6. Linux文本流 7. ...
- 004-hadoop家族概述
hadoop家族 名称 简介 Hadoop 分布式基础架构 Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了 ...
- 将 ssh (security shell) 移植到 vxworks
openssh 依赖 openssl,这两个东西主要针对posix系统,移植到 vxworks 等实时系统有相当的难度. 可以考虑移植如下的库(ssh server): dropbear: https ...
- Spark2.0 特征提取、转换、选择之一:数据规范化,String-Index、离散-连续特征相互转换
数据规范化(标准化) 在数据预处理时,这两个术语可以互换使用.(不考虑标准化在统计学中有特定的含义). 下面所有的规范化操作都是针对一个特征向量(dataFrame中的一个colum)来操作的. 首先 ...
- linux根文件系统 /etc/resolv.conf 文件详解(转)
大家好,今天51开源给大家介绍一个在配置文件,那就是/etc/resolv.conf.很多网友对此文件的用处不太了解.其实并不复杂,它是DNS客户机配置文件,用于设置DNS服务器的IP地址及DNS域名 ...
- 设置npm淘宝代理
来源:https://cnodejs.org/topic/4f9904f9407edba21468f31e 镜像使用方法(三种办法任意一种都能解决问题,建议使用第三种,将配置写死,下次用的时候配置还在 ...