python + sklearn ︱分类效果评估——acc、recall、F1、ROC、回归、距离
之前提到过聚类之后,聚类质量的评价:
聚类︱python实现 六大 分群质量评估指标(兰德系数、互信息、轮廓系数)
R语言相关分类效果评估:
R语言︱分类器的性能表现评价(混淆矩阵,准确率,召回率,F1,mAP、ROC曲线)
.
一、acc、recall、F1、混淆矩阵、分类综合报告
1、准确率
第一种方式:accuracy_score
# 准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)
Out[127]: 0.33333333333333331
accuracy_score(y_true, y_pred, normalize=False) # 类似海明距离,每个类别求准确后,再求微平均
Out[128]: 3第二种方式:metrics
宏平均比微平均更合理,但也不是说微平均一无是处,具体使用哪种评测机制,还是要取决于数据集中样本分布
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。
微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。(来源:谈谈评价指标中的宏平均和微平均)
from sklearn import metrics
metrics.precision_score(y_true, y_pred, average='micro') # 微平均,精确率
Out[130]: 0.33333333333333331
metrics.precision_score(y_true, y_pred, average='macro') # 宏平均,精确率
Out[131]: 0.375
metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro') # 指定特定分类标签的精确率
Out[133]: 0.5其中average参数有五种:(None, ‘micro’, ‘macro’, ‘weighted’, ‘samples’)
.
2、召回率
metrics.recall_score(y_true, y_pred, average='micro')
Out[134]: 0.33333333333333331
metrics.recall_score(y_true, y_pred, average='macro')
Out[135]: 0.3125.
3、F1
metrics.f1_score(y_true, y_pred, average='weighted')
Out[136]: 0.37037037037037035
.
4、混淆矩阵
# 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
Out[137]:
array([[1, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 1],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0]])横为true label 竖为predict

.
5、 分类报告
# 分类报告:precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 2, 0]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))其中的结果:
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class 2 1.00 1.00 1.00 2
avg / total 0.67 0.80 0.72 5包含:precision/recall/fi-score/均值/分类个数
.
6、 kappa score
kappa score是一个介于(-1, 1)之间的数. score>0.8意味着好的分类;0或更低意味着不好(实际是随机标签)
from sklearn.metrics import cohen_kappa_score
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
cohen_kappa_score(y_true, y_pred).
二、ROC
1、计算ROC值
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)2、ROC曲线
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)来看一个官网例子,贴部分代码,全部的code见:Receiver Operating Characteristic (ROC)
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
# Import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 画图
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
plt.figure()
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
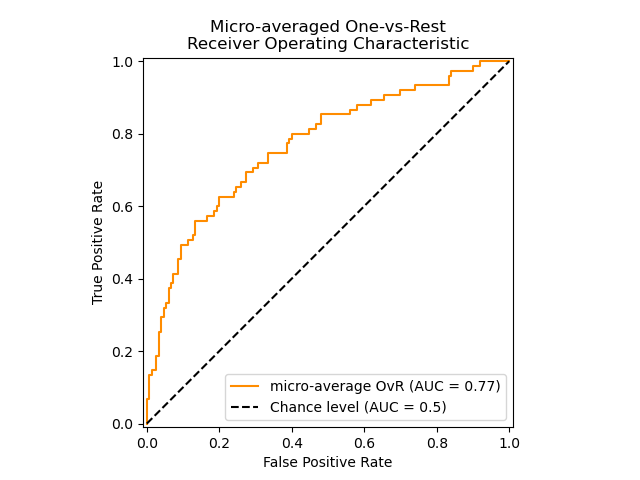
.
三、距离
.
1、海明距离
from sklearn.metrics import hamming_loss
y_pred = [1, 2, 3, 4]
y_true = [2, 2, 3, 4]
hamming_loss(y_true, y_pred)
0.25.
2、Jaccard距离
import numpy as np
from sklearn.metrics import jaccard_similarity_score
y_pred = [0, 2, 1, 3,4]
y_true = [0, 1, 2, 3,4]
jaccard_similarity_score(y_true, y_pred)
0.5
jaccard_similarity_score(y_true, y_pred, normalize=False)
2.
四、回归
1、 可释方差值(Explained variance score)
from sklearn.metrics import explained_variance_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
explained_variance_score(y_true, y_pred) .
2、 平均绝对误差(Mean absolute error)
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_absolute_error(y_true, y_pred).
3、 均方误差(Mean squared error)
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred).
4、中值绝对误差(Median absolute error)
from sklearn.metrics import median_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
median_absolute_error(y_true, y_pred).
5、 R方值,确定系数
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred) .
参考文献:
python + sklearn ︱分类效果评估——acc、recall、F1、ROC、回归、距离的更多相关文章
- Python sklearn 分类效果评估
https://blog.csdn.net/sinat_26917383/article/details/75199996
- scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集 数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载 转成csv载入数据 im ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- Python Sklearn.metrics 简介及应用示例
Python Sklearn.metrics 简介及应用示例 利用Python进行各种机器学习算法的实现时,经常会用到sklearn(scikit-learn)这个模块/库. 无论利用机器学习算法进行 ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- BERT模型在多类别文本分类时的precision, recall, f1值的计算
BERT预训练模型在诸多NLP任务中都取得最优的结果.在处理文本分类问题时,即可以直接用BERT模型作为文本分类的模型,也可以将BERT模型的最后层输出的结果作为word embedding导入到我们 ...
- Spark2.0机器学习系列之8:多类分类问题(方法归总和分类结果评估)
一对多(One-vs-Rest classifier) 将只能用于二分问题的分类(如Logistic回归.SVM)方法扩展到多类. 参考:http://www.cnblogs.com/CheeseZH ...
- Precision,Recall,F1的计算
Precision又叫查准率,Recall又叫查全率.这两个指标共同衡量才能评价模型输出结果. TP: 预测为1(Positive),实际也为1(Truth-预测对了) TN: 预测为0(Negati ...
- Sklearn分类树在合成数集上的表现
小伙伴们大家好~o( ̄▽ ̄)ブ,今天我们开始来看一下Sklearn分类树的表现,我的开发环境是Jupyter lab,所用的库和版本大家参考: Python 3.7.1(你的版本至少要3.4以上) S ...
随机推荐
- 在VMware中使用Nat方式设置静态IP
为了在公司和家中不改变ip,所以采用vm的NAT模式来设置静态ip 1.vm采用NAT模式联网 2.编辑vm虚拟机设置 3.查看该网段的网关 可以看出网关为192.168.44.2,然后开始设置静态i ...
- Ubuntu 18.04配置机场客户端
最近把自己的笔记本电脑安装成ubuntu18.04操作系统,为了更方便的查找文档,所以需要配置一下机场(v2ray)的客户端方便查找资料,以下是配置步骤: 1.下载并执行一键脚本: bash < ...
- 20145216史婧瑶《Java程序设计》第3周学习总结
20145216 <Java程序设计>第3周学习总结 教材学习内容总结 第四章 认识对象 4.1 类与对象 •对象(Object):存在的具体实体,具有明确的状态和行为 •类(Class) ...
- MWeb Lite以及Eclipse的使用感想
MWeb Lite以及Eclipse的使用感想 1.首先说明的是MWeb Lite是一种Markdown软件,Eclipse是用于做java开发的,都用于Mac系统中.因为Mac系统本身较为人性化的设 ...
- 解读:Hadoop Archive
hdfs并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode中占用150byte内存.如果存储大量的小文件,它们会吃掉NameNode节点的大量内存.MR案 ...
- 高手用的SourceInsight配置文件——仿Sublime风格【转】
本文转载自:https://blog.csdn.net/weixin_38233274/article/details/80209100 配置文件下载地址:https://download.csdn. ...
- heartbeat 编译安装配置
一.heartbeat介绍 heartbeat是HA高可用集群的一个重要组件,heartbeat实现了资源转移和心跳信息传递.它的常用组合方式为heartbeat v1,heartbeat v2+cr ...
- 使用淘宝的npm代理下载模块
npm install node-sass --registry=http://registry.npm.taobao.org
- poj 1050 To the Max 最大子矩阵和 经典dp
To the Max Description Given a two-dimensional array of positive and negative integers, a sub-rect ...
- Memcached get 命令
Memcached get 命令获取存储在 key(键) 中的 value(数据值) ,如果 key 不存在,则返回空. 语法: get 命令的基本语法格式如下: get key 多个 key 使用空 ...