[转]Hadoop YARN任务提交流程
Yarn是随着hadoop发展而催生的新框架,全称是Yet Another Resource Negotiator,可以翻译为“另一个资源管理器”。yarn取代了以前hadoop中jobtracker(后面简写JT)的角色,因为以前JT的 任务过重,负责任务的调度、跟踪、失败重启等过程,而且只能运行mapreduce作业,不支持其他编程模式,这也限制了JT使用范围,而yarn应运而 生,解决了这两个问题。
为了表述清楚,大家可以先看hadoop版本说明这篇文章,我这里要说的是hadoop2.0,也就是新增了yarn之后的版本。
1. Yarn(或称MRv2)
Yarn把jobtracker的任务分解开来,分为:
- ResourceManager(简写RM)负责管理分配全局资源
- ApplicationMaster(简写AM),AM与每个具体任务对应,负责管理任务的整个生命周期内的所有事宜
除了上面两个以外,tasktracker被NodeManager(简写NM)替代,RM与NM构成了集群的计算平台。这种设计允许NM上长期运 行一些辅助服务,这些辅助服务一般都是应用相关的,通过配置项指定,在NM启动时加载。例如在yarn上运行mapreduce程序时,shuffle就 是一个由NM加载起来的辅助服务。需要注意的是,在hadoop 0.23之前的版本,shuffle是tasktracker的一部分。
与每个应用相关的AM是一个框架类库,它与RM沟通协商如何分配资源,与NM协同执行并且监测应用的执行情况。在yarn的设计 中,mapreduce只是一种编程模式,yarn还允许像MPI(message passing interface),Spark等应用构架部署在yarn上运行。
2. Yarn设计
上图是一个典型的YARN集群。可以看到RM有两个主要服务:

- 可插拔的Scheduler,只负责用户提交任务的调度
- ApplicationsMaster的(简写AsM)负责管理集群中每个任务的ApplicationMaster(简写AM),负责任务的监控、失败重起等
在hadoop1.0时,资源分配的单位是slot,再具体分为map的slot与reduce的slot,而且这些slot的个数是在任务运行前
事先定义的,在任务运行过程中不能改变,很明显,这会造成资源的分配不均问题。在haodop2.0中,yarn采用了container的概念来分配资
源。每个container由一些可以动态改变的属性组成,到现在为止,仅支持内存、cpu两种。但是yarn的这种资源管理方式是通用的,社区以后会加
入更多的属性,比如网络带宽,本地硬盘大小等等。
3. Yarn主要组件
在这小节里,主要介绍yarn各个组件,以及他们之间是如何通信的。
3.1 Client<—>RM
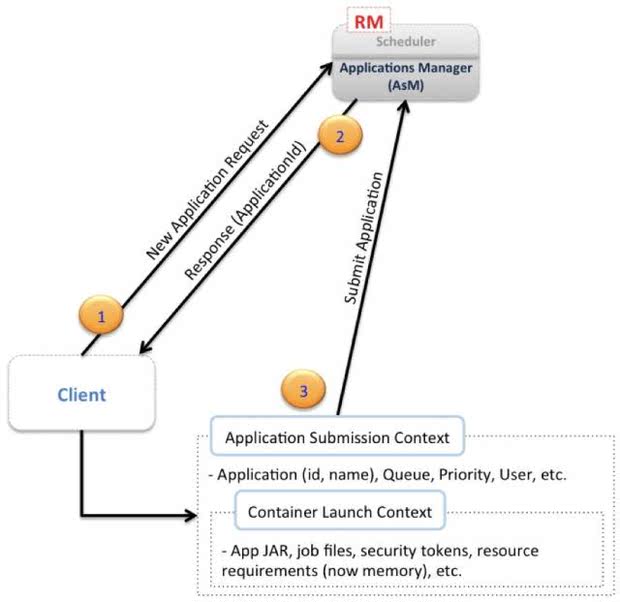
上面这个图是Client向RM提交任务时的流程。
(1) Client通过New Application Request来通知RM中的AsM组建
(2) AsM一般会返回一个新生成的全局ID,除此之外,传递的信息还有集群的资源状况,这样Client就可以在需要时请求资源来运行任务的第一个container即AM。
(3) 之后,Client就可以构造并发送ASC了。ASC中包括了调度队列,优先级,用户认证信息,除了这些基本的信息之外,还包括用来启动AM的CLC信息,一个CLC中包括jar包、依赖文件、安全token,以及运行任务过程中需要的其他文件。
经过上面这三步,一个Client就完成了一次任务的提交。之后,Client可以直接通过RM查询任务的状态,在必要时,可以要求RM杀死这个应用。如下图: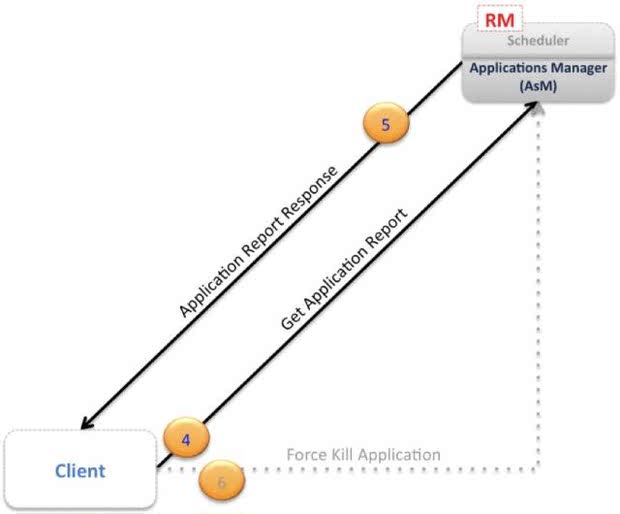
3.2 RM<—>AM
RM在收到Client端发送的ASC后,它会查询是否有满足其资源要求的container来运行AM,找到后,RM会与那个container所在机器上的NM通信,来启动AM。下面这个图描述了这其中的细节。
(1) AM向RM注册,这个过程包括handshaking过程,并且传递一些信息,包括AM监听的RPC端口、用于监测任务运行状态的URL等。
(2) RM中的Scheduler部件做回应。这个过程会传递AM所需的信息,比如这个集群的最大与最小资源使用情况等。AM利用这些信息来计算并请求任务所需的资源。
(3) 这个过程是AM向RM请求资源。传递的信息主要包含请求container的列表,还有可能包含这个AM已经释放的container的列表。
(4) 在AM经过(3)请求资源之后,在稍微晚些时候,会把心跳包与任务进度信息发送给RM
(5) Scheduler在收到AM的资源请求后,会根据调度策略,来分配container以满足AM的请求。
(6) 在任务完成后,AM会给RM发送一个结束消息,然后退出。
在上面(5)与(6)之间,AM在收到RM返回的container列表后,会与每个container所在机器的NM通信,来启动这个container,下面就说说这个过程。
3.2 AM<—>NM

(1) AM向container所在机器的NM发送CLC来启动container
(2)(3) 在container运行过程中,AM可以查询它的运行状态
4. API
通过上面的描述,开发者在开发YARN上的应用时主要需要关注以下接口:
-
Client使用这个协议来与RM通信,来启动一个新应用,检查任务的运行状态或杀死任务
-
AM使用这个协议来向RM注册/撤销,请求资源来运行任务。
-
AM使用这个协议来与NM通信,来启动/停止container,查询container的状态。
5. 总结
用户在使用hadoop1.0 API编写的MapReduce可以不用修改直接运行在yarn上,不过随着yarn的发展,向后兼容性还不知道怎么样。不管怎样,新的yarn平台绝对值得我们使用。
[转]Hadoop YARN任务提交流程的更多相关文章
- Yarn任务提交流程(源码分析)
关键词:yarn rm mapreduce 提交 Based on Hadoop 2.7.1 JobSubmitter addMRFrameworkToDistributedCache(Configu ...
- Hadoop YARN 的工作流程简述
1.Client 向 YARN 提交应用程序,其中包括 ApplicationMaster 程序及启动 ApplicationMaster 命令2.ResourceManager 为该 Applica ...
- YARN作业提交流程剖析
YARN(MapReduce2) Yet Another Resource Negotiator / YARN Application Resource Negotiator对于节点数超出4000的大 ...
- Flink(二)【架构原理,组件,提交流程】
目录 一.运行架构 1.架构 2.组件 二.核心概念 TaskManager . Slots Parallelism(并行度) Task .Subtask Operator Chains(任务链) E ...
- 4 weekend110的YARN的通用性意义 + yarn的job提交流程
Mr程序写完之后,提交给yarn,yarn会产生一个MRAppMaster,想说的是,yarn变得很 通用,yarn集群上,不光可以跑mr程序,还可以跑各种运算模型. 海量批处理,mapreduce ...
- Hadoop - YARN 启动流程
一 YARN的启动流程 watermark/2/text/aHR ...
- hadoop Yarn 编程API
客户端编程库: 所在jar包: org.apache.hadoop.yarn.client.YarnClient 使用方法: 1 定义一个YarnClient实例: private YarnClien ...
- Hadoop YARN介绍
YARN产生背景 MRv1的局限 YARN是在MRv1基础上演化而来的,它克服了MRv1中的各种局限性.在正式介绍YARN之前,先了解下MRv1的一些局限性,主要有以下几个方面: 扩展性差.在MRv1 ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
随机推荐
- ITQ迭代量化方法解析
一.问题来源 来源于换关键字,从LSH转换为hash检索,这要感谢李某. 二.解析 笔者认为关键思想是数据降维后使用矩阵旋转优化,其他和LSH一样的. 2.1 PCA降维 先对原始空间的数据集 X∈R ...
- UnitOfWork机制的实现和注意事项
UnitOfWork机制 /*一点牢骚: * UnitOfWork机制的蛋疼之处: * UnitOfWork机制,决定了插入新的实体前,要预先设置数据库中的主键Id,尽管数据库自己生产主键. * ...
- uva 125
floyd 算法 如果存在无数条路 则存在a->a的路 a->b的路径数等于 a->i 和 i->b(0=<i<=_max) 路径数的乘积和 #includ ...
- hdu 4403
水水的dfs #include <cstdio> #include <cstring> #include <cstdlib> #include <cmath& ...
- VC中不同类型DLL及区别
1. DLL的概念可以向程序提供一些函数.变量或类. 静态链接库与动态链接库的区别:(1)静态链接库与动态链接库都是共享代码的方式.静态链接库把最后的指令都包含在最终生成的EXE文件中了:动态链接库不 ...
- 关于delete和delete[]
[精彩] 求问delete和delete[] 的区别??http://www.chinaunix.net/jh/23/311058.html C++告诉我们在回收用 new 分配的单个对象的内存空间的 ...
- 在linux下,查看一个运行中的程序, 占用了多少内存
1. 在linux下,查看一个运行中的程序, 占用了多少内存, 一般的命令有 (1). ps aux: 其中 VSZ(或VSS)列 表示,程序占用了多少虚拟内存. RSS列 表示, 程序占用了多少物 ...
- 深入理解Java内存模型(二)——重排序
本文属于作者原创,原文发表于InfoQ:http://www.infoq.com/cn/articles/java-memory-model-2 数据依赖性 如果两个操作访问同一个变量,且这两个操作中 ...
- MSSQLServer基础03(数据检索(查询))
执行备注中的代码创建测试数据表. 简单的数据检索 :SELECT * FROM Student 只检索需要的列 :SELECT sName FROM Student .ame FROM Student ...
- *IntelliJ IDEA使用Hibernate连接数据库
在IntelliJ IDEA中配置MySQL Database.