Lucene的Query类介绍
把Lucene的查询当成sql的查询,也许会笼统的明白些query的真相了。
查询分为大致两类,1:精准查询。2,模糊查询。
创建测试数据。
private Directory directory;
private IndexReader reader;
private String[] ids = {"1","2","3","4","5","6"};
private String[] emails = {"aa@itat.org","bb@itat.org","cc@cc.org","dd@sina.org","ee@zttc.edu","ff@itat.org"};
private String[] contents = {
"welcome to visited the space,I like book",
"hello boy, I like pingpeng ball",
"my name is cc I like game",
"I like football",
"I like football and I like basketball too",
"I like movie and swim"
};
private int[] attachs = {2,3,1,4,5,5};
private String[] names = {"zhangsan","lisi","john","jetty","lisi","jake"};
先建立索引。
private Map<String,Float> scores = new HashMap<String,Float>();
public SearchUtil(){
try {
directory = FSDirectory.open(Paths.get("D://lucene//index"));
scores.put("itat.org", 1.5f);
scores.put("cc.org", 2.0f);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 创建索引
*/
@SuppressWarnings("deprecation")
public void index(){
IndexWriter writer = null;
try {
directory = FSDirectory.open(Paths.get("D://lucene//index"));
writer = getWriter();
Document doc = null;
for(int i=0;i<ids.length;i++){
doc = new Document();
doc.add(new Field("id", ids[i], Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("name", names[i], Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("content", contents[i], Field.Store.NO,Field.Index.ANALYZED));
//存储数字
doc.add(new IntField("attach", attachs[i], Field.Store.YES));
// 加权操作
TextField field = new TextField("email", emails[i], Field.Store.YES);
String et = emails[i].substring(emails[i].lastIndexOf("@")+1);
if (scores.containsKey(et)) {
field.setBoost(scores.get(et));
}
doc.add(field);
// 添加文档
writer.addDocument(doc);
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}finally{
try {
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
索引建立完毕。

构造方法。
/**
* getSearcher
* @return
*/
public IndexSearcher getSearcher(){
try {
directory = FSDirectory.open(Paths.get("D://lucene//index"));
if(reader==null){
reader = DirectoryReader.open(directory);
}else{
reader.close();
}
return new IndexSearcher(reader);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
一、精准匹配。
1,精准查询
就是查什么给什么。
/**
* 精准匹配
*/
public void search(String searchField,String field){
// 得到读取索引文件的路径
IndexReader reader = null;
try {
directory = FSDirectory.open(Paths.get("D://lucene//index"));
reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 运用term来查找
Term t = new Term(searchField, field);
Query q = new TermQuery(t);
// 获得查询的hits
TopDocs hits = searcher.search(q, 10);
// 显示结果
System.out.println("匹配 '" + q + "',总共查询到" + hits.totalHits + "个文档");
for (ScoreDoc scoreDoc : hits.scoreDocs){
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("id:"+doc.get("id")+":"+doc.get("name")+",email:"+doc.get("email"));
} } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
reader.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
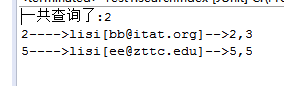
2,区间查询。
/**
* between
* @param field
* @param start
* @param end
* @param num
*/
public void searchByTermRange(String field,String start,String end,int num) {
try {
IndexSearcher searcher = getSearcher();
BytesRef lowerTerm = new BytesRef(start.getBytes()) ;
BytesRef upperTerm = new BytesRef(end.getBytes()) ; Query query = new TermRangeQuery(field, lowerTerm , upperTerm, true, true);
TopDocs tds = searcher.search(query, num); System.out.println("一共查询了:"+tds.totalHits);
for(ScoreDoc sd:tds.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
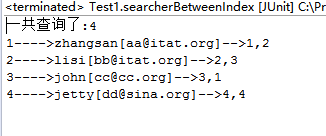
3、匹配其索引开始以指定的字符串的文档
/**
* 匹配其索引开始以指定的字符串的文档
* @param field
* @param value
* @param num
*/
public void searchByPrefix(String field,String value,int num) {
try {
IndexSearcher searcher = getSearcher();
Query query = new PrefixQuery(new Term(field,value));
TopDocs tds = searcher.search(query, num);
System.out.println("一共查到:"+tds.totalHits);
for(ScoreDoc scoreDoc:tds.scoreDocs){
Document doc = searcher.doc(scoreDoc.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach"));
}
} catch (Exception e) {
e.printStackTrace();
}
}

4、数字搜索
/**
* 数字搜索
* @param field
* @param start
* @param end
* @param num
*/
public void searchByNums(String field,int start,int end,int num){
try {
IndexSearcher searcher = getSearcher();
Query query = NumericRangeQuery.newIntRange(field, start, end, true, true);
TopDocs tds = searcher.search(query, num);
System.out.println("一共查到:"+tds.totalHits);
for(ScoreDoc scoreDoc:tds.scoreDocs){
Document doc = searcher.doc(scoreDoc.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
二、模糊匹配
/**
* 通配符
* @param field
* @param value
* @param num
*/
public void searchByWildcard(String field,String value,int num){
try {
IndexSearcher searcher = getSearcher();
WildcardQuery query = new WildcardQuery(new Term(field,value));
TopDocs tds = searcher.search(query, num);
System.out.println("一共查到:"+tds.totalHits);
for(ScoreDoc scoreDoc:tds.scoreDocs){
Document doc = searcher.doc(scoreDoc.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach"));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
/**
* BooleanQuery可以连接多个子查询
* Occur.MUST表示必须出现
* Occur.SHOULD表示可以出现
* Occur.MUSE_NOT表示不能出现
* @param field
* @param value
* @param num
*/
@SuppressWarnings("deprecation")
public void searchByBoolean(String[] field,String[] value,int num){
try {
if(field.length!=value.length){
System.out.println("field的长度需要与value的长度相等!");
System.exit(0);
}
IndexSearcher searcher = getSearcher();
BooleanQuery query = null;
TopDocs tds = null;
for(int i = 0;i<field.length;i++){
query = new BooleanQuery();
query.add(new TermQuery(new Term(field[i],value[i])),Occur.SHOULD);
tds = searcher.search(query, num);
}
System.out.println("一共查询:"+tds.totalHits);
for(ScoreDoc doc:tds.scoreDocs){
Document document = searcher.doc(doc.doc);
System.out.println(document.get("id")+"---->"+
document.get("name")+"["+document.get("email")+"]-->"+document.get("id")+","+
document.get("attach"));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
public void searchByPhrase(int num){
try {
IndexSearcher searcher = getSearcher();
PhraseQuery query = new PhraseQuery();
query.setSlop(3);
query.add(new Term("content","like"));
// //第一个Term
query.add(new Term("content","football"));
TopDocs tds = searcher.search(query, num);
System.out.println("一共查询了:"+tds.totalHits);
for(ScoreDoc sd:tds.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach"));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
/**
* 相似度匹配查询
* @param num
*/
public void searchByFuzzy(int num) {
try {
IndexSearcher searcher = getSearcher();
FuzzyQuery query = new FuzzyQuery(new Term("name","jake"));
TopDocs tds = searcher.search(query, num);
System.out.println("一共查询了:"+tds.totalHits);
for(ScoreDoc sd:tds.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach")+","+doc.get("date"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public void searchByQueryParse(Query query,int num) {
try {
IndexSearcher searcher = getSearcher();
TopDocs tds = searcher.search(query, num);
System.out.println("一共查询了:"+tds.totalHits);
for(ScoreDoc sd:tds.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println(doc.get("id")+"---->"+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+
doc.get("attach")+","+doc.get("date")+"=="+sd.score);
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
Lucene的Query类介绍的更多相关文章
- ArcGIS API for JavaScript 4.2学习笔记[21] 对3D场景上的3D要素进行点击查询【Query类学习】
有人问我怎么这个系列没有写自己做的东西呢? 大哥大姐,这是"学习笔记"啊!当然主要以解读和笔记为主咯. 也有人找我要实例代码(不是示例),我表示AJS尚未成熟,现在数据编辑功能才简 ...
- 并发编程--Concurrent-工具类介绍
并发编程--Concurrent-工具类介绍 并发编程--Concurrent-工具类介绍 CountDownLatch CylicBarrier Semaphore Condition 对象监视器下 ...
- CYQ.Data.Orm.DBFast 新增类介绍(含类的源码及新版本配置工具源码)
前言: 以下功能在国庆期就完成并提前发布了,但到今天才有时间写文介绍,主要是国庆后还是选择就职了,悲催的是上班的地方全公司都能上网,唯独开发部竟不让上网,是个局域网. 也不是全不能上,房间里有三台能上 ...
- MediaRecorder类介绍
audiocallbackvideojavadescriptorencoding 目录(?)[+] 找到个MediaRecorder类介绍和大家分享一下. Mediarecorder类在官网的介绍和在 ...
- Object类介绍
一.Object类介绍
- istringstream、ostringstream、stringstream 类介绍 .
istringstream.ostringstream.stringstream 类介绍 . 转自:http://www.cnblogs.com/gamesky/archive/2013/01/09/ ...
- C#中的Dictionary字典类介绍
Dictionary字典类介绍 必须包含名空间System.Collection.Generic Dictionary里面的每一个元素都是一个键值对(由二个元素组成:键和值) 键必须是 ...
- POI 导出导入工具类介绍
介绍: Apache POI是Apache软件基金会的开源项目,POI提供API给Java程序对Microsoft Office格式档案读和写的功能. .NET的开发人员则可以利用NPOI (POI ...
- Android Paint类介绍以及浮雕和阴影效果的设置
Paint类介绍 Paint即画笔,在绘制文本和图形用它来设置图形颜色, 样式等绘制信息. 1.图形绘制 setARGB(int a,int r,int g,int b); 设置绘制的颜色,a代表透明 ...
随机推荐
- 开发神器之--Sublime Text
原来还有这么个神器啊,忍痛丢掉了notepad++,投入她的怀抱!! 使用和介绍就不写了,大牛们已经整理了. 官网:http://www.sublimetext.com/ 入门及心得:http://w ...
- c语音中打印参数调用层级即call stack, call trace
http://stackoverflow.com/questions/105659/how-can-one-grab-a-stack-trace-in-c There's backtrace(), a ...
- mongodb在window下和linux下的部署 和 安装可视化工具
Windows安装 安装Mongo数据库: 在发布本文的时间官方提供的最新版本是:2.4.0 ,如果不做特殊声明,本教程所用的版本将会是这个版本. 第一步:下载安装包:http://www.mo ...
- UVA 10194 Football (aka Soccer)
Problem A: Football (aka Soccer) The Problem Football the most popular sport in the world (america ...
- 激活Navicat?如何注册Navicat?
在注册界面里面输入信息 名:顺便输入 组织:顺便输入 注册码:NAVH-WK6A-DMVK-DKW3
- iOS中SQLite知识点总结2
数据库(SQLite) 01-多表查询 格式:select 字段1,字段2,... from 表名1,表名2; 别名:select 别名1.字段1 as 字段别名1,别名2.字段2 as 字段别名2, ...
- Android 获取手机总内存和可用内存等信息
在android开发中,有时候我们想获取手机的一些硬件信息,比如android手机的总内存和可用内存大小.这个该如何实现呢? 通过读取文件"/proc/meminfo"的信息能够获 ...
- oracle2
为什么选择oracle--性能优越 概述:目前主流数据库包括 微软: sql server和access 瑞典MySql: AB公司mysql ibm公司: db2(处理海量) 美国Sybase公司: ...
- SDWebImage 原理及使用
这个类库提供一个UIImageView类别以支持加载来自网络的远程图片.具有缓存管理.异步下载.同一个URL下载次数控制和优化等特征. SDWebImage 加载图片的流程 入口 setImageWi ...
- hdu2018java
母牛的故事 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...