Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘。。。)
应用:
1)正面VS负面的影评(影片分类问题)
2)产品/品牌评价: Google产品搜索
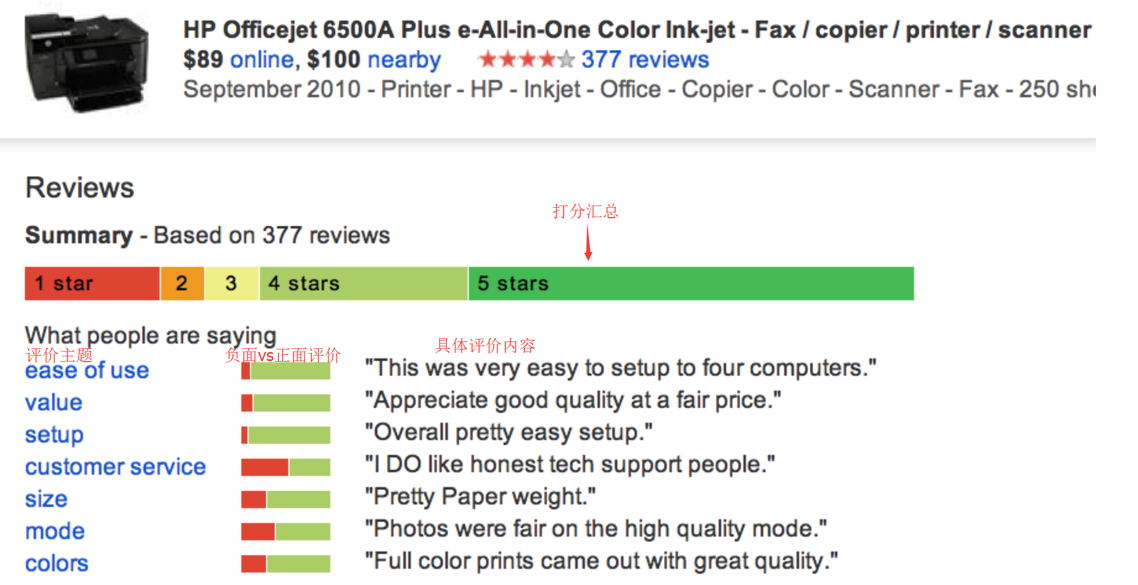
3)twitter情感预测股票市场行情/消费者信心
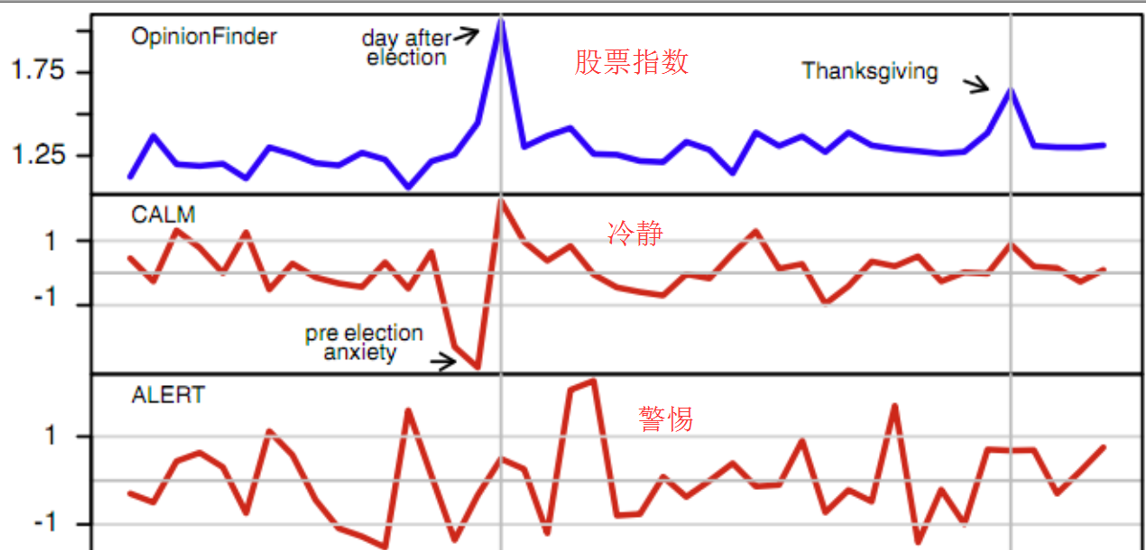
2. 目的
利用机器提取人们对某人或事物的态度,从而发现潜在的问题用于改进或预测。
这里我们所说的情感分析主要针对态度(attitude)。
注:Scherer 情感状态类型主要可以分为:
情绪(emotion):有一定原因引发的同步反应。例如悲伤(sadness),快乐(joy)
心情(mood):没有明显原因引发的长期低强度的主观感受变化。例如忧郁(gloomy),倦怠(listless)
人际立场(interpersonal stance):对他人的特定反应。例如疏远(distant),冷漠(cold)
态度(attitude):对特定人或事物的带有主观色彩的偏好或倾向。喜欢(like),讨厌(hate)
个性特质(personal traits):相对稳定的个性倾向和行为趋势。例如焦虑(nervous),渴望(anxious)
具体定义可以参考这篇文章
3. 情感分析的内容
考虑到态度可以具体分成一下内容:
1) 态度的持有者(source)
2) 态度的目标(aspect)
3) 态度的类型:一系列类型如喜欢(like),讨厌(hate),珍视(value),渴望(desire)等;或着简单的加权极性如积极(positive),消极(negative)和中性(neutral)并可用具体的权重修饰
4) 态度的范围:某句话/全文
因此情感分析的目标可以分为一下几种:
初级:文章的整体感情是积极/消极的?
进阶:对文章的态度从1-5打分
高级:检测态度的目标,持有者和类型
4. 基准算法(Baseline Algorithm)
极性检测(Bo Pang et.al. Thumbs up? Sentiment Classification using Machine Learning Techniques. EMNLP-2002, 79-86)
数据样例: IMDB影评数据
步骤:
1)分词(tokenization)
分词的一些问题:
1.如果数据来自HTML或XML格式,那就需要处理相应的标记;
2.Twitter标记(名字,哈希标签);
3.大小写(中文不存在);
4.均一化电话号码和日期等数字;5. 表情符号(emoticons)
2)特征提取(feature extraction)
特征提取的问题:
1.如何处理否定词;
在否定词的到最近的标点之间的所有词添加NOT_前缀(所有否定词后的词极性取反,最早由Das, Mike Chen et.al 在Yahoo! For Amazon: Extracting market sentiment from stock message boards. 2001. APFA中提出)

2.什么词用于分析:只用形容词/所有词 (在样例数据上表现更好)
3)分类(classification):常用分类器 - 朴素贝叶斯,MaxEnt分类器,SVM
朴素贝叶斯(naïve Bayes)
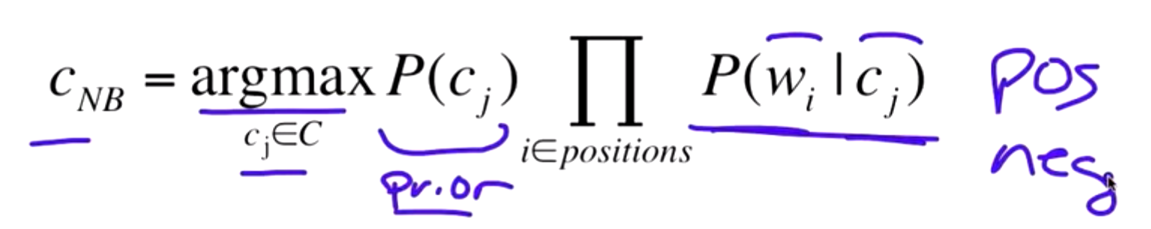
解释一下:左边代表的是这个评论的极性类型,就是右边概率最大的情况下的极性类型。P(cj)指该极性类型出现的概率,ΠP(wi|cj)指在当前极性条件下文档中各个词出现的概率的乘积。
这里的用Laplace(+1 smoothing)转换:
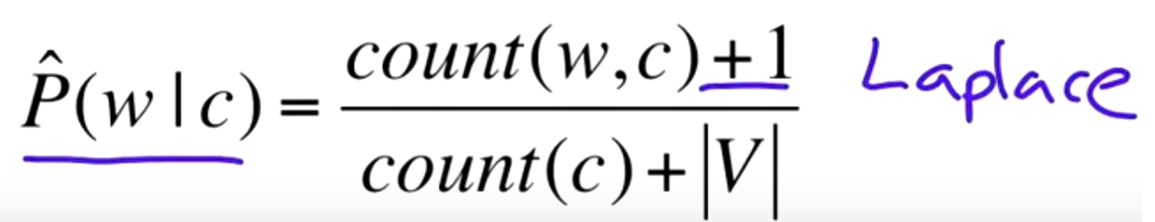
其中V就是当前训练文本的词汇量。
二项(布尔值)多项式朴素贝叶斯(Binarized/Boolean feature multinomial naïve Bayes):一篇文档中出现的所有出现的词的频率计数为1.
原则:对情感而言,词是否出现比其出现的次数更有意义。
a) 模型训练:
1.从训练文库中提取词汇
2.计算P(cj)

3.计算P(wk|cj)

Boolean naïve Bayes的特点就是第一步去重,然后才把所有文档合并为一个大文档;而最后的α就是之前所提到的Laplace处理。
b) 验证集:

c) 具体例子:
一般naïve Bayes:

在测试集上,C类Chinese出现频次为5,P(Chinese|C) = 5/8;在验证集上的频次为3.
Boolean naïve Bayes:

去重后,测试集上C类的Chinese频次为3,P(Chinese|C)=3/6;验证集上频次为1.
注:1. 经过测试Boolean naïve Bayes的效果比计数所有词的一般naive Bayes要好;2. Boolean naïve Bayes与multivariate Bernoulli naïve Bayes(MBNB) 不同,后者不适用与情感分析相关的问题。3. 频次统计除了所有词或去重只保留一个,还可以用log(freq(w)),词频介于两者之间,可能效果会更好。
d) 交叉验证(cross-validation)
这个材料由很多在这就不具体展开了,没听过的可以看这里

注: 一般来说,除此以外最后会用一个没有在交叉验证数据集中的验证数据集来最后测试一下,防止过拟合。
e) 分类的其他问题
MaxEnt与SVM分类器一般在大量数据下表现比naïve Bayes要好
4)问题:无法对那些没有出现明显的感情词汇但表达了积极或消极的情感的文本进行正确分类。例如:

顺序效应(florida expectation problem)(前面描述了很长很期待的句子,但只是为了表达不满)。例如:

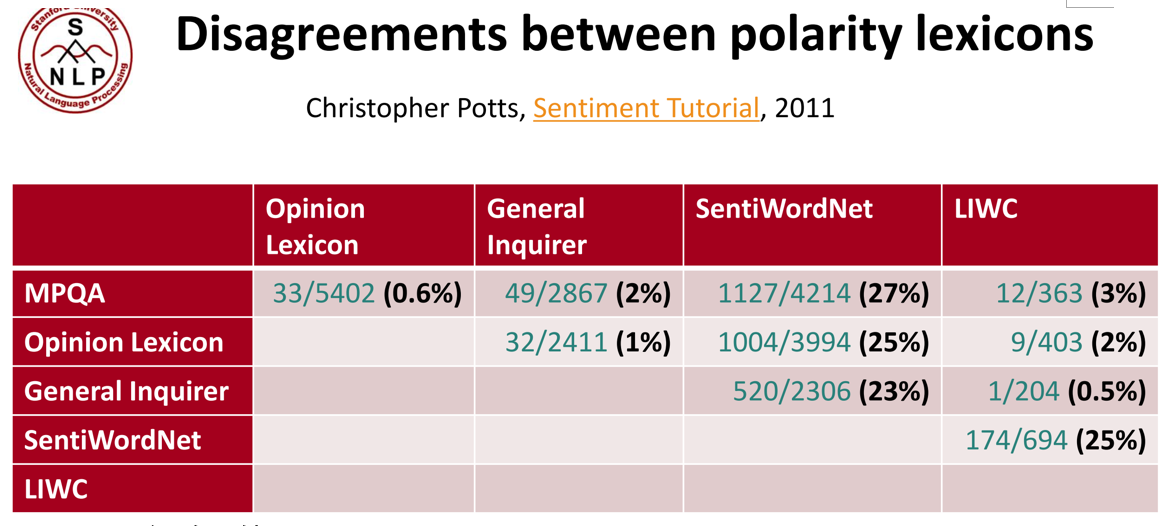
5. 情感词典(sentiment lexicons):这部分讲的都是英文词典(可以略过)。
General Inquirer (Philip, 1966); LIWC (Pennebaker, 2007); MPQA Subjectivity Cues Lexicon (Riloff and Wiebe, 2003); Bing Liu Opinion Lexicons (Bing Liu, 2004); SentiWordNet (Stefano, 2010)
各词典对于极性的判断比较一致,可以随便用。
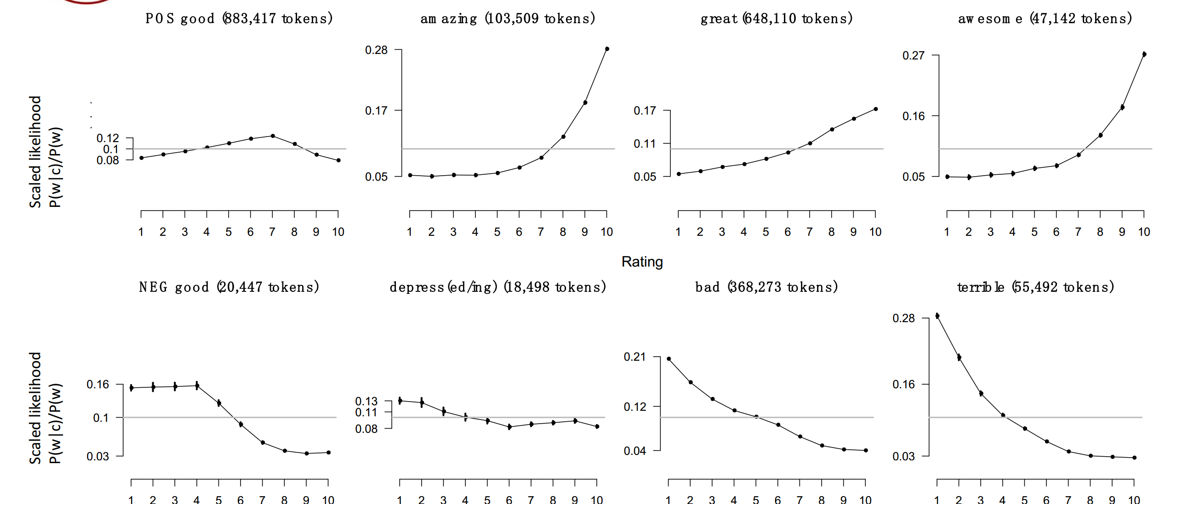
分析IMDB评论极性:
1)将1-3星计数为差评类,但不要使用原始的差评类中的词的个数用于极性分析,因为虽然评高分的人比评一分的人少,但是留下评论的更多的是好评的人(满意的人倾向于留下评论),因此直接用会由偏差,需要用似然度(likelihood):

其中f(w, c)指c类中w的个数,分母为该类所有词的个数。
然后归一化(scale)使词与词之间的频率可以相互比较: P(w|c)/P(w)
2)一些词在各评分的出现频率
3)Pott’s 2011 experiment result: more negations in negative sentiment(否定词常出现于负面情绪)
6. 情感词典的构建
半监督学习法(Semi-supervised learning)
使用少量打标的样本和制定的规则来bootstrap(大概是自举的意思)词典。
方法1:Hatzivassiloglou and McKeown原则 – and连接的形容词极性相同, but连接的形容词极性相反。例如: Fair(公平) and legitimate (正当); fair(公平) but brutal(残忍)。
此方法使用于单个词
步骤:
a)人工打标种子形容词极性集(pos & neg)
b)扩展与种子集共同出现的形容词。方法可以如下:
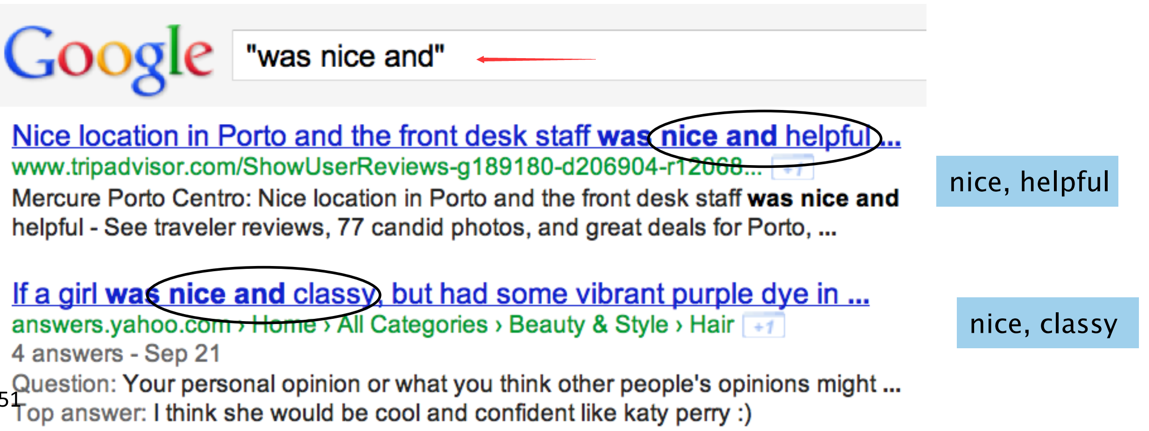
google上前排出现的连体词一般都是高频的,不太容易出错。
c)用监督分类器对各个词对进行极性相似度打分:count(and)高的表示相同的极性,count(but)高的表示相反的极性。
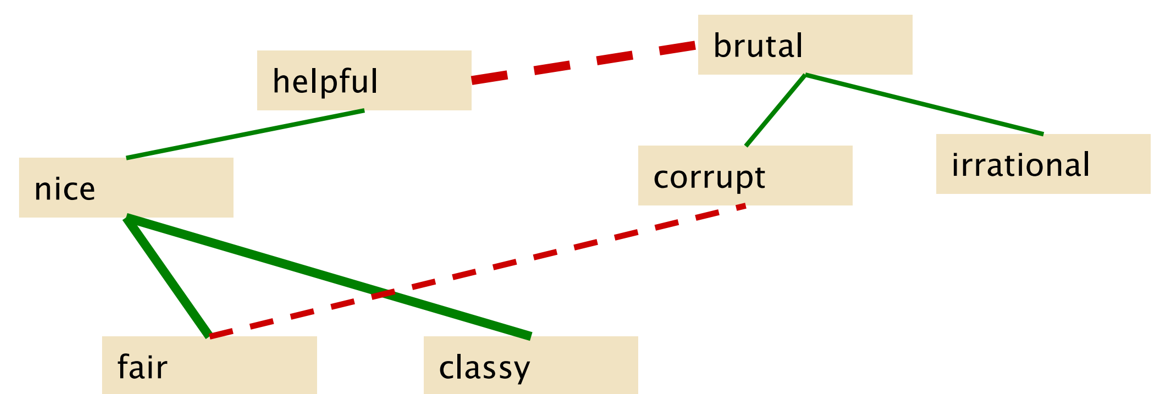
d)基于相似度聚类将所得的词分成两类
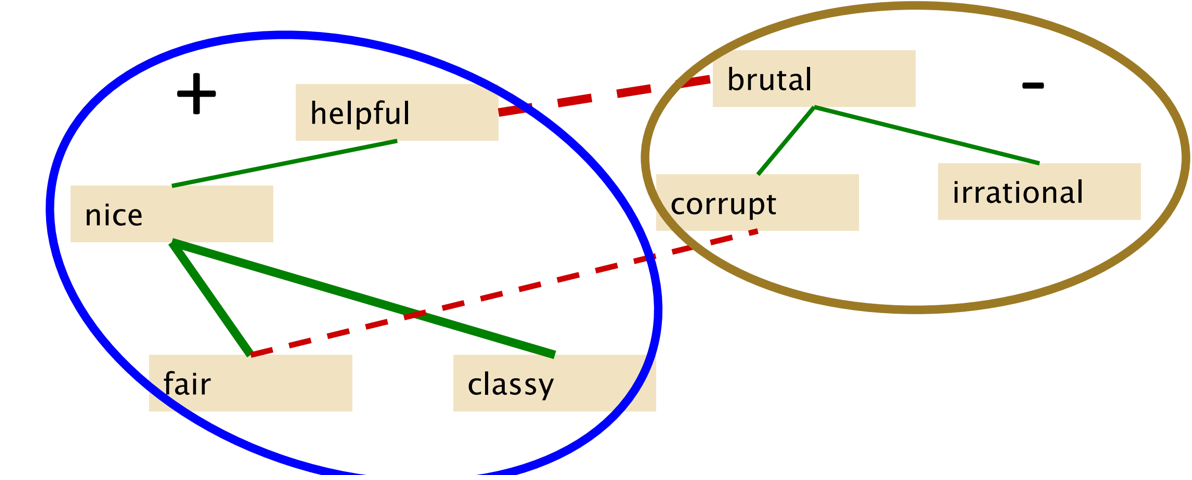
e)手动矫正一些误分类的词
方法2:Turney Algorithm:适用于短语,可学习到局部信息特征。
a)提取短语词典: 提取与形容词相关的2词短语,标准如下:
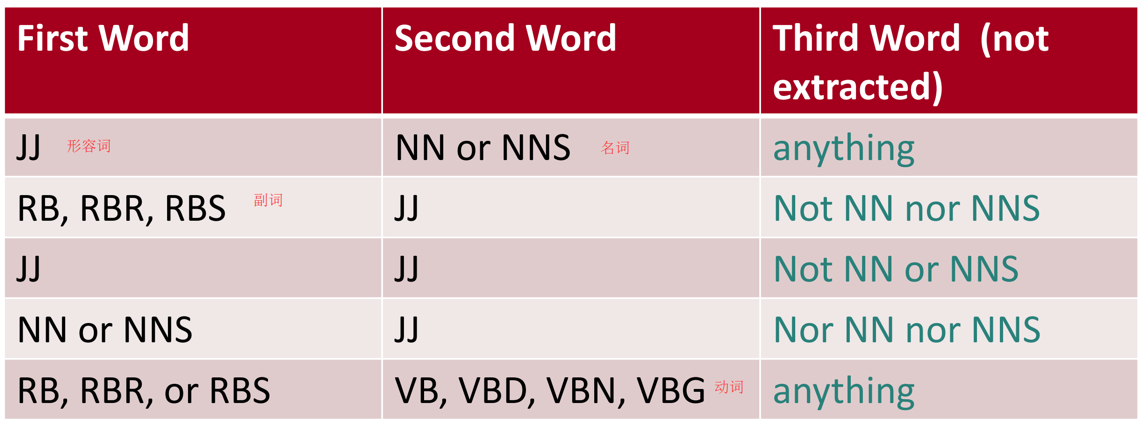
b)学习短语极性
衡量两个词的共现程度:PMI (Point mutual information) .
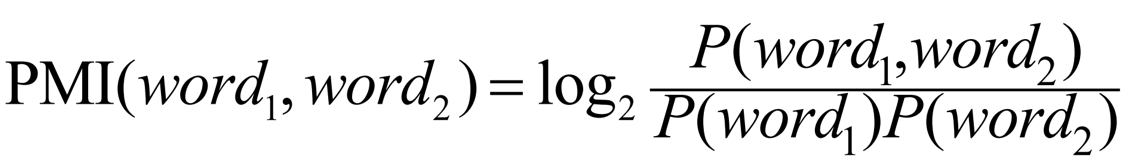
两个词相互独立。
注:PMI是交互信息(mutual information)衡量方式的变体。
具体方法:
通过搜索引擎搜索,P(word) = hits(word)/N,分子为搜索结果中出现该词的条目数,分母为所有搜索到的条目数;而P(word1, word2) = hits(word1 NEAR word2)/N^2,分子为两个词出现在同一处地方的条目数,分母为所有搜索到的条目数。
评价某个词的极性就只需要将正向词的PMI减去负向词的PMI,若大于0,则可认为正,反之可认为负。比如:
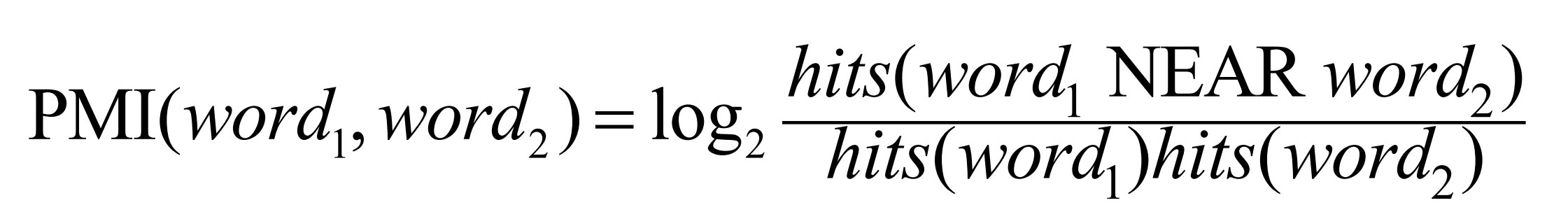
c)基于短语的平均极性对评论总体极性进行打标,比如
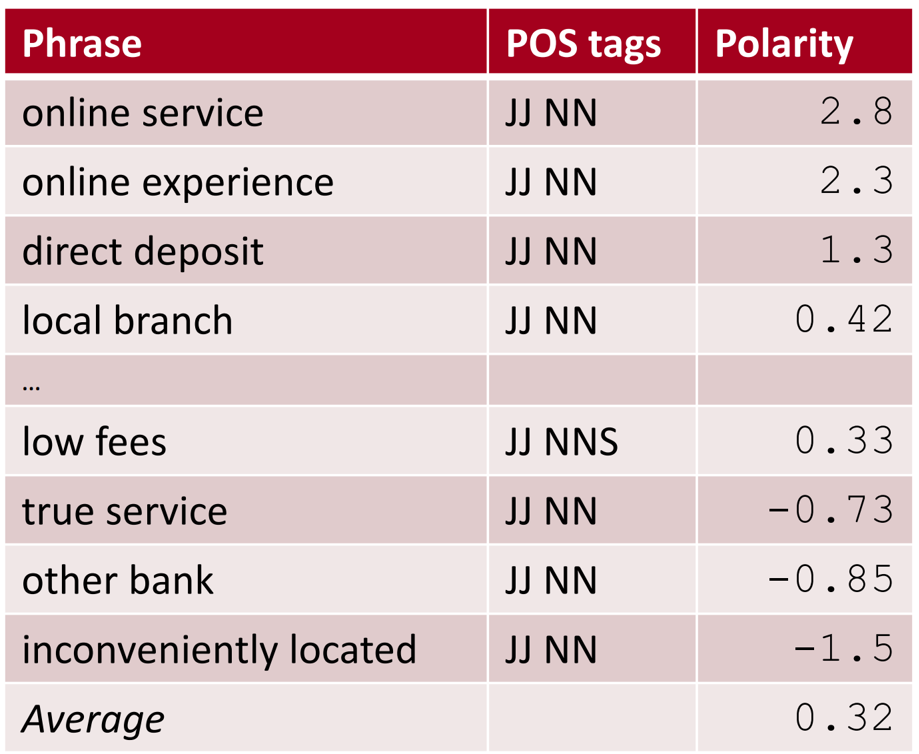
方法3:利用WordNet学习极性
WordNet为同义词典,因此提取极性词典只需要将种子正向词在WordNet中的近义词(synonym)和反向词在WordNet中的反义词(antonym)加入到种子积正向词库,将种子负向词的同义词和种子正向词的反义词加入到种子反向词库,往复迭代数次即可。
总结:因为用了多个词的短语,相比单个词的极性分析,可以了解文本局部的信息,而且容错能力更强。
7.其他一些情感分析内容
1)单句情感:寻找情感描述的对象

方法(raised by Hu 2004 & Goldensohn 2008):
1.高频短语+规则。首先获取评论中出现的高频短语,然后制定规则,比如对评价食物我们可以将出现在情感词之后的高频词作为情感的对象 – 高频词为fish tacos, 那么评论中出现great fish tacos我们就认为fish tacos是great的情感描述对象。
2.对于描述内容的方向比较明确的评论可以预先定义对象然后用监督学习的方法进行对象分类。比如对于餐馆评论而言,一般描述的对象为food, décor, service, value,NONE(其他),首先将一些餐馆评论语句人工打标为上述标签,然后作为训练集训练一个描述对象的分类器。
总体流程如下:
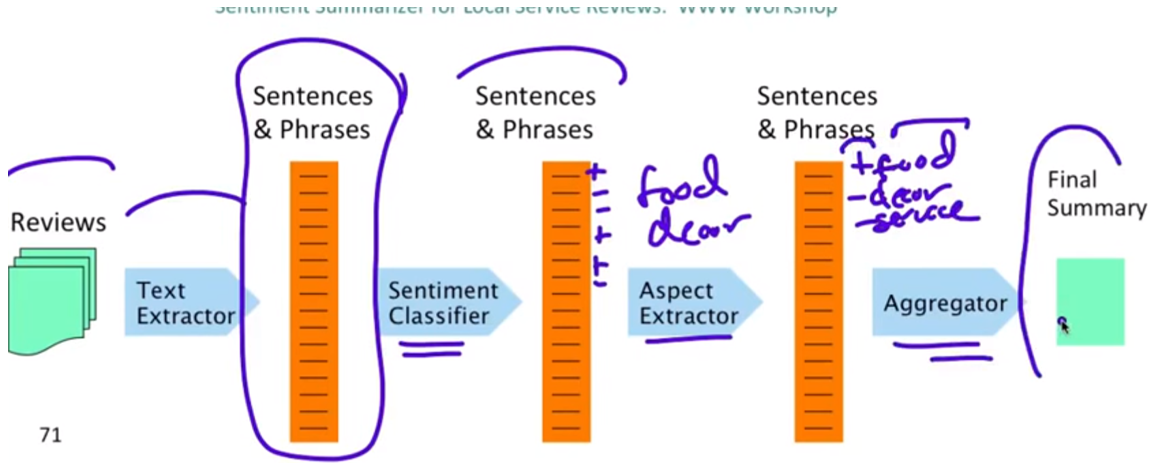
分句 -> 情感极性分类 -> 提取主题 -> 汇总得到增提评论
2)样本不平衡问题(机器学习常见问题了)
不同极性的评论数量差距太大(比如10^6好评vs10^4差评),会导致分类器模型参数异常。解决方式为重抽样(好评只取10^4条)或者采用代价敏感学习(cost-sensitive learning),比如在训练SVM分类器的时候 将稀有样本错误分类的惩罚加大。
3)处理打分问题(例如5星)
1.可将其转化为二元分类问题,比如小于2.5星的视为neg,大于2.5星的视为pos。
2.直接将星与极性强度用线性回归或其他方式拟合
8.总结
1.情感分析本质上还是分类问题(二分或者回归)
2.否定词在情感描述中很重要
3.使用所有词的naïve Byes模型在一些问题上表现较好,而使用子集短语的模型则在另一些表现较好。
4.构建极性词库流程:手动标记种子极性词库,然后用半监督学习方式扩展词库
5.除了态度(attitude)以外,Scherer情感状态的其他类型,emotion,mood,interpersonal stance,personal traits都是情感分析的重要方向。
9.传送门:
1.Stanford nlp公开课视频:https://www.youtube.com/playlist?list=PLuBJa2RktQX-N0flCReMywxy1E-tsF0ZC
2.课件:https://web.stanford.edu/~jurafsky/NLPCourseraSlides.html
Stanford NLP学习笔记:7. 情感分析(Sentiment)的更多相关文章
- Stanford NLP学习笔记1:课程介绍
Stanford NLP课程简介 1. NLP应用例子 问答系统: IBM Watson 信息提取(information extraction) 情感分析 机器翻译 2. NLP应用当前进展 很成熟 ...
- Stanford NLP 学习笔记2:文本处理基础(text processing)
I. 正则表达式(regular expression) 正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里). ^(在字符前): 负选择,匹配除括号以外 ...
- stanford NLP学习笔记3:最小编辑距离(Minimum Edit Distance)
I. 最小编辑距离的定义 最小编辑距离旨在定义两个字符串之间的相似度(word similarity).定义相似度可以用于拼写纠错,计算生物学上的序列比对,机器翻译,信息提取,语音识别等. 编辑距离就 ...
- UML和模式应用学习笔记-1(面向对象分析和设计)
UML和模式应用学习笔记-1(面向对象分析和设计) 而只是对情节的记录:此处的用例场景为:游戏者请求掷骰子.系统展示结果:如果骰子的总点数是7,则游戏者赢得游戏,否则为输 (2)定义领域模型:在领域模 ...
- ArcGIS案例学习笔记4_2_水文分析批处理地理建模
ArcGIS案例学习笔记4_2_水文分析批处理地理建模 联系方式:谢老师,135_4855_4328,xiexiaokui#139.com 概述 计划时间:第4天下午 目的:自动化,批量化,批处理,提 ...
- ArcGIS案例学习笔记4_1_水文分析
ArcGIS案例学习笔记4_1_水文分析 联系方式:谢老师,135_4855_4328,xiexiaokui#139.com 概述 计划时间:第4天上午 教程: pdf page478 数据:实验数据 ...
- Stanford parser学习:LexicalizedParser类分析
上次(http://www.cnblogs.com/stGeekpower/p/3457746.html)主要是对应于javadoc写了下LexicalizedParser类main函数的功能,这次看 ...
- Stanford Corenlp学习笔记——词性标注
使用Stanford Corenlp对中文进行词性标注 语言为Scala,使用的jar的版本是3.6.0,而且是手动添加jar包,使用sbt添加其他版本的时候出现了各种各样的问题 添加的jar包有5个 ...
- 自然语言处理NLP学习笔记一:概念与模型初探
前言 先来看一些demo,来一些直观的了解. 自然语言处理: 可以做中文分词,词性分析,文本摘要等,为后面的知识图谱做准备. http://xiaosi.trs.cn/demo/rs/demo 知识图 ...
随机推荐
- MSSQL—字符串分离(Split函数)
前面提到了记录合并,有了合并需求肯定也会有分离需求,说到字符串分离,大家肯定会想到SPLIT函数,这个在.NET,Java和JS中都有函数,很可惜在SQL SERVER中没有,我们只能自己来写这么一个 ...
- Python学习-day2
这周时间充裕,把第一周的两个作业登陆验证和三级菜单做完后又用零零散散的时间看完了第二周的课程,不得不说老男孩这个教育方式感觉还是不错的,其实说白了就是花钱找个人监督自己学习呗,而且还强行让我们养成一些 ...
- 学android: android-studio从main开始
android-studio 创建hello world很容易,一路next创建blank activity,再接好手机或者avd(andorid virtual device)就好了. 但是对于我 ...
- VS 打开工程后 自动关闭
今天在打开一个VS2008的工程的时候,会提示vs2008 已停止工作的异常信息,具体的解决办法如下: 打开vs2008命令提示窗口: 打开窗口后:键入:devenv.exe /resetuserda ...
- HSV与RGB颜色空间的转换
一.本质上,H的取值范围:0~360 S的取值范围:0~1 V的取值范围:0~255 但是,当图像为32F型的时候,各 ...
- zend studio 的使用
1.将php项目导入到zend studio 中的方式为:http://my.oschina.net/maomi/blog/86077: 2.zend studio中将php项目导出的方式为:如果你会 ...
- JDBC的应用实例
首先要添加一个引用的库 在项目上右键--构建路径--配置构建路径--在(库)中选择添加外部JAR--选择jar包添加 jar文件是驱动包 添加后包资源管理器中显示一个引用的库会有jar包 加载数据访问 ...
- Linux达人养成第一季
Linux简介 一.Linux发展史 二.开源软件简介 三.Linux应用领域 四.Linux学习方法 五.Linux与Windows的不同 六.字符界面的优势 Linux系统安装 一.虚拟机安装 二 ...
- WaitForMultipleObjects返回失败原因之一
上网搜了下 关于 WaitForMultipleObjects等待多个线程退出的状态失败的情况,也有人遇到类似的情况. 一次项目中我也遇到这么个情况.项目中创建线程都是用的 _beginthread ...
- java代码
io的使用 package com.tan.io; import java.io.*; import java.util.*; class Employee{ private String name; ...