吴恩达机器学习笔记(十一) —— Large Scale Machine Learning
主要内容:
一.Batch gradient descent
二.Stochastic gradient descent
三.Mini-batch gradient descent
四.Online learning
五.Map-reduce and data parallelism
一.Batch gradient descent
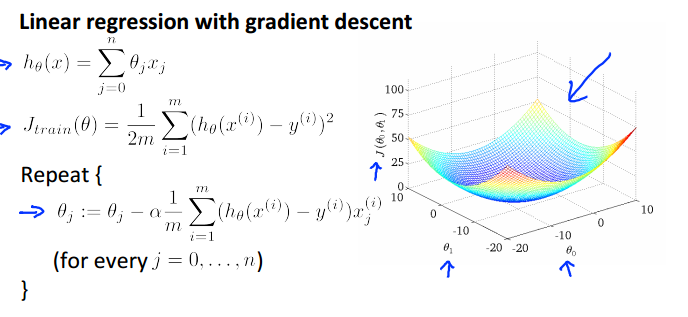
batch gradient descent即在损失函数对θ求偏导时,用上了所有的训练集数据(假设有m个数据,且m不太大)。这种梯度下降方法也是我们之前一直使用的。
如线性回归的batch gradient descent:
二.Stochastic gradient descent0
当数据集的规模m不太大时,利用batch gradient descent可以很好地解决问题;但是当m很大时,如 m = 100,000,000 时,如果在求偏导的时候,都利用上这100,000,000个数据,那么一次的迭代所耗的时间都是无法接受的。既然如此,就在求偏导的时候,只利用一个数据,但每一次迭代都利用上所有的数据。详情如下:
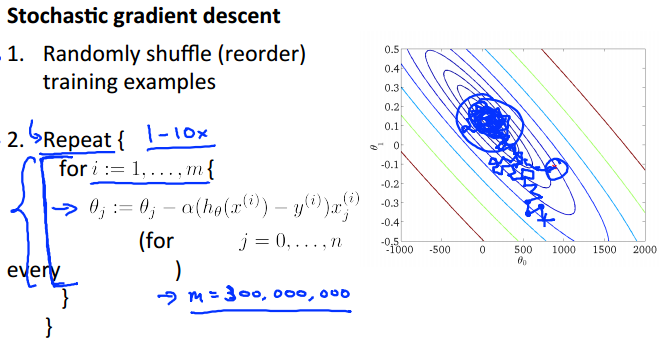
相当于把数据集抽到外面单独作为一层循环。
迭代效果:在迭代的过程中,由于求偏导时只用到了一个数据,所以很容易导致方向走偏。因而轨迹是迂回曲折的,且最终也不会收敛,而是在收敛点的附近一直徘徊。
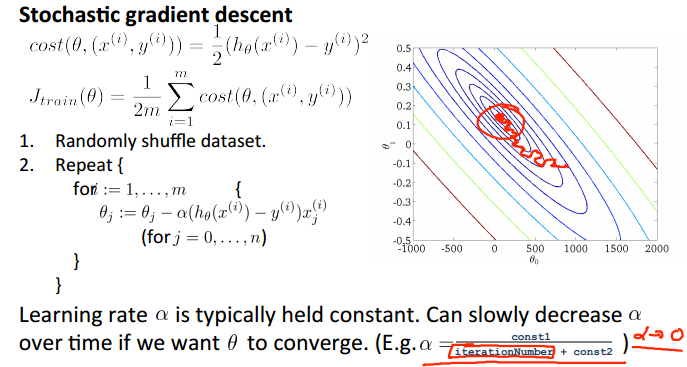
那么,如何检测stochastic gradient descent的收敛情况?
对于batch gradient descent,我么可以画出损失函数随每一次迭代的变化情况。而对于stochastic gradient descent,我们可以在经过若干次迭代之后(如1000次后),求出这若干次迭代的平均损失值,并画图进行观察收敛情况。

优化:可知stochastic gradient descent在靠近最优点的时候,依然“大踏步”地徘徊,为了更加接近最优点(提高精度),我们可以:在每一次迭代靠近最优点的时候,都降低其学习率,即步长。这样,在越靠近最优点的时候,走的步伐就越细了,自然能更加接近最优点:
三.Mini-batch gradient descent
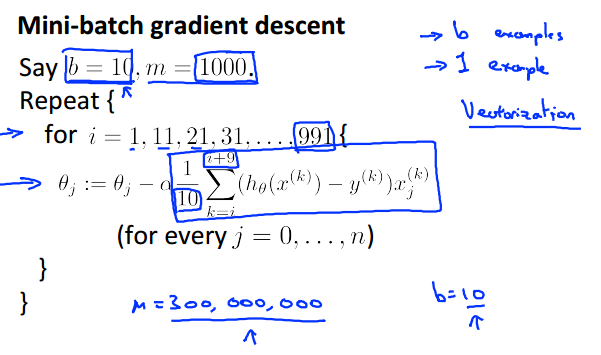
在求损失函数对θ求偏导时,batch gradient descent用上了所有的数据,而stochastic gradient descent则只利用了一个数据。可知,这两种做法都属于极端情况:batch gradient descent的轨迹是“心无旁骛,一直往最优点靠近”,而stochastic gradient descent是“像醉汉一样跌跌撞撞地往最优点靠近,且最后一直徘徊于最优点附近”。为了平衡这两种情况,我们可以采取这种的方法:求偏导的时候,即不用上所有数据,也不只是用一个数据,而是用一个子集的数据(子集的大小为b,假设b为10)。具体如下:
四.Online learning
很多时候,数据并不是一下子就能够收集完的,或者庞大的数据量只能慢慢地收集,如某一网站的一些链接的被点击次数等,都需要时间的积累。这时,就要用上在线学习了。
一下是两个在线学习的例子:


五.Map-reduce and data parallelism
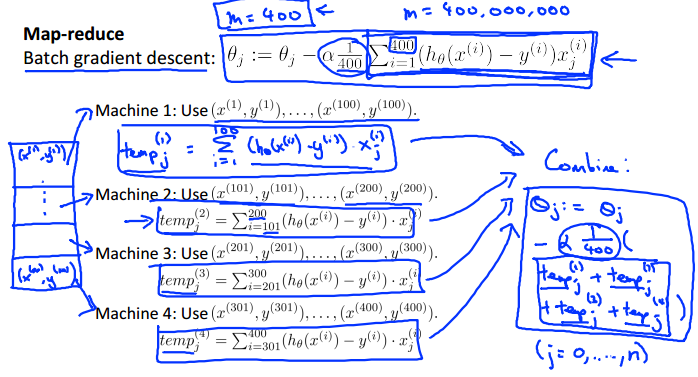
当数据量很大时,我们可以将计算任务分配到多台计算机上(假如一台电脑有多个CPU,还可以是一台计算机上的多CPU分布式计算),然后再汇总计算结果,即所谓的分布式计算。
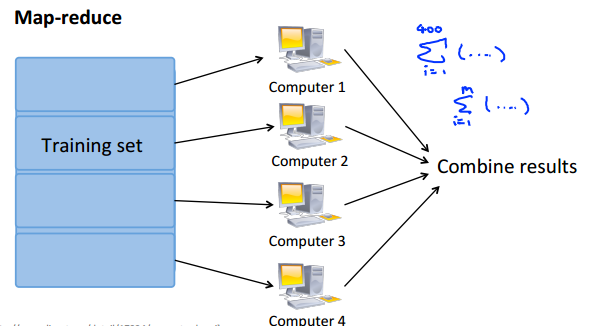
如可以将梯度下降求偏导的计算分布到赌台计算机上,然后汇总:
吴恩达机器学习笔记(十一) —— Large Scale Machine Learning的更多相关文章
- 吴恩达机器学习笔记37-学习曲线(Learning Curves)
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差.方差问题.学习曲线是学习算法的一个很好的合理检验(sanity check).学习曲线是将训练集误差和交叉验证集误差作为 ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记
Week1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记(完结)
Week 1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning——吴恩达机器学习笔记(酷
[1] ML Introduction a. supervised learning & unsupervised learning 监督学习:从给定的训练数据集中学习出一个函数(模型参数), ...
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- 吴恩达机器学习笔记60-大规模机器学习(Large Scale Machine Learning)
一.随机梯度下降算法 之前了解的梯度下降是指批量梯度下降:如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法. 在随机梯度下降法中,我们定义代价函数为一个 ...
- 吴恩达机器学习笔记43-SVM大边界分类背后的数学(Mathematics Behind Large Margin Classification of SVM)
假设我有两个向量,
- 吴恩达机器学习笔记42-大边界的直观理解(Large Margin Intuition)
这是我的支持向量机模型的代价函数,在左边这里我画出了关于
- [吴恩达机器学习笔记]12支持向量机3SVM大间距分类的数学解释
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.3 大间距分类背后的数学原理- Mathematic ...
随机推荐
- Linux常用的几个vi小命令
输入跳转命令: 命令行前 Ctrl+A 命令行后 Ctrl+E VI命令中: 当前行 行首 "0" 当前行 行尾 "Shift+4" 当前文档首行首字符:& ...
- html小知识,怎么实现一个td占据2行
<table border="1" width="100%"> <tr> <td rowspan="2"> ...
- 【Excle数据透视表】如何移动数据透视表的位置
数据透视表创建完成了,现在需要将它移动到D5位置,如何移动呢? 解决办法 通过"移动数据透视表"功能实现数据透视表的位置移动 步骤1 单击数据透视表任意单元格→数据透视表工具→分析 ...
- iOS开发 - "Cast from pointer to smaller type 'int' loses information” 解决的方法
今天要写一个联系人搜索算法. 百度了下, 在code4App中找到相关代码. 可是自己跑了下, 发现报错. 错误内容例如以下: "Cast from pointer to smaller t ...
- Java String 常用函数
1>获取 1.1:字符串中包含的字符数,也就是字符串的长度. int length():获取长度 1.2:根据位置获取位置上某个字符. char charAt(int index) ...
- items" does not support runtime expression
<%@taglib prefix="c" uri="http://java.sun.com/jstl/core"%> 更改为 <%@tagl ...
- 用GetTickCount()计算一段代码执行耗费的时间的小例子
var aNow,aThen,aTime:Longint; begin aThen := GetTickCount(); Sleep();//代码段 aNow := GetTickCount(); a ...
- Github的基本功能:
作者:Fadeoc Khaos链接:http://www.zhihu.com/question/20070065/answer/30521531来源:知乎著作权归作者所有,转载请联系作者获得授权. G ...
- erlang进程监控:link和monitor
Erlang最开始是为了电信产品而发展起来的语言,因为这样的目的,决定了她对错误处理的严格要求.Erlang除了提供exception,try catch等语法,还支持Link和Monitor两种监控 ...
- 【转】win7 任务计划 任务映像已损坏或篡改(异常来自HRESULT:0x80041321)
请这样操作:1. 以管理员身份运行命令提示符并执行命令chcp 437schtasks /query /v | find /i "ERROR: Task cannot be loaded:& ...