日志系统实战(三)-分布式跟踪的Net实现
介绍
在大型系统开发调试中,跨系统之间联调开始变得不好使了。莫名其妙一个错误爆出来了,日志虽然有记录,但到底是哪里出问题了呢?
是Ios端参数传的不对?还是A系统或B系统提供的接口导致?相信有不少人遇到这种情况,大多数问题往往不大,但排查起来比较费劲。
下面介绍下怎么通过上下文跟踪的方法,最快定位到其问题。
阅读目录:
概述
简单介绍就是,通过一个TraceId把整个业务请求逻辑相关联起来,根据时间顺序形成一个完整的调用链。
这样无论任何地方报错,只要拿TraceId去日志系统简查下,根据上下文的顺序就知道是哪一步、哪个函数、哪个参数出错了,能以最快速度定位处理BUG。
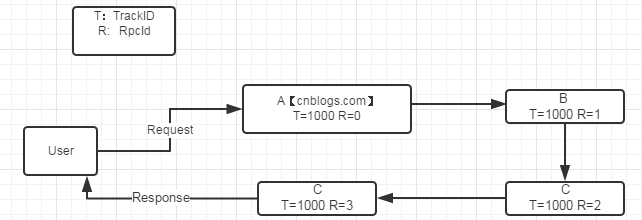
如图以博客园为例。当博客园收到一个请求后,自动为生产个唯一ID 1000,之后所有处理工作都是用这个1000。
每个处理模块都维持一个上下文ID自增,rpcid++。
其处理模块可以是函数级,逻辑层级,服务器级等都可以。
一旦发现有异常后,自动将TraceId发给博客园。这样程序员们,就能根据TraceId最快定位问题了。
关于各种环境下具体的代码实现:
web环境
定义跟踪日志需要的参数,进行上下文传递。
public class LogBody
{
/// <summary>
/// 跟踪ID
/// </summary>
public string TraceId { get; set; }
/// <summary>
/// 上下文ID
/// </summary>
public int RpcId { get; set; }
/// <summary>
/// 处理时间
/// </summary>
public DateTime LastTime { get; set; }
}
在global.asax全局Application_BeginRequest函数中,使用HttpContext.Current上下文,开始进行埋点(跟踪),设置rpc 0。
void Application_BeginRequest(object sender, EventArgs e)
{
var lb = new LogBody();
lb.TraceId = Guid.NewGuid().ToString("N");
lb.RpcId=0;
lb.LastTime = DateTime.Now;
HttpContext.Current.Response.AppendHeader("traceID", lb.TraceId);
HttpContext.Current.Items.Add(lb.TraceId, lb);
//记录日志,例:用户请求参数,userAgent等。
}
在default页开始业务逻辑,设置rpc 1。
protected void Page_Load(object sender, EventArgs e)
{
var traceID = HttpContext.Current.Response.Headers["traceID"];
LogBody logbody = HttpContext.Current.Items[traceID] as LogBody;
logbody.RpcId++;
logbody.LastTime = DateTime.Now;
//业务逻辑。
//记录日志。。。
}
如上就完成上下文的传递。
Application_BeginRequest 中在实际使用中,只需要对有用的页面(例:aspx,ashx)进行埋点。
日志记录的时候,可以把logbody都存储起来。
存储到Headers可以让前端通过JS也能拿到TraceId,方便去排查问题。
LastTime这个字段,可以与上一次的相减,这样就得出中间逻辑处理所花费的时间了。
多线程环境
在web程序中可以用httpcontext的上下文传递。
在单线程的程序中,按照线性顺序即可。
多线程中利用用threadlocal传递。
public static ThreadLocal<LogBody> Body = new ThreadLocal<LogBody>();
static void Main(string[] args)
{
var t1 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = ,
TraceId = Guid.NewGuid().ToString("N")
};
//业务1
Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); Thread.Sleep(); Body.Value.RpcId++;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t1.Start(); var t2 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = ,
TraceId = Guid.NewGuid().ToString("N")
};
//业务1
Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); Thread.Sleep();
Body.Value.RpcId++;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t2.Start();
}
运行如下:

异步环境
往往在生产环境中,会有大量的异步操作。如果有异步行为的话,打乱上下文怎么办?这时候需要引入另外一个概念,父节点Id。
这样异步操作的行为就父节点之下,最终在日志后台展示的是一个倒着的树形结构。
如图可以看到业务2异步派生出来的子节点。
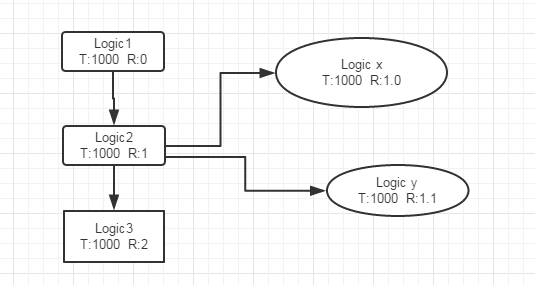
把上下文rpcid修改成double类型。
static void Main(string[] args)
{
var t2 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = 1,
TraceId = Guid.NewGuid().ToString("N")
};
var t1 = new Thread((lb) =>
{
var temp = lb as LogBody;
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = temp.RpcId,
TraceId = temp.TraceId
};
Body.Value.RpcId += 0.1;
//业务x
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime ); Thread.Sleep(5000); Body.Value.RpcId+=0.1;
Body.Value.LastTime = DateTime.Now;
//业务y
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t1.Start(Body.Value); //业务1
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); Thread.Sleep(2000);
Body.Value.RpcId+=1;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t2.Start();
}
代码中用参数传递给了异步线程中,运行如下:

性能,大数据量,隐私安全
关于性能
从代码中可以看出,这种方式对程序性能影响可以忽略不计。
需要注意是:如果在生产环境跑的话,不论是写文件,还是数据库,或写统一日志平台。都会导致大量IO读写,网络资源消耗。
如果服务器都消耗这上面,就得不偿失了。
可以用内存队列+队列+批量push或pull的方式,并且注意设置阀值。
关于大数据量
大量的请求,其实多数是无效的。这里引入采样率的概念。 例如按求余取,或者按地区,时间等。也可以单独写采样规则。
日志可以只记录error以上的级别,只有在排查生产环境的时候才开启debug,info级别信息。
存储这块,可以根据实际需要选择sql server,mongodb,hbase hdfs。
关于隐私安全
如果有敏感数据,可根据安全级别进行加密。
总结
本文是基于Google dapper论文的思路展开,基于此进行很多扩展。
示例中采用的是手动记录,在实际使用中,可以简化调用,封装成自动构建的,有兴趣的可以看前2篇自动注入的相关介绍。
参考资源
Google dapper论文
淘宝EagleEye系统
日志系统实战(三)-分布式跟踪的Net实现的更多相关文章
- 布式实时日志系统(三) 环境搭建之centos 6.4下hadoop 2.5.2完全分布式集群搭建最全资料
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- 日志系统实战(一)—AOP静态注入
背景 近期在写日志系统,需要在运行时在函数内注入日志记录,并附带函数信息,这时就想到用Aop注入的方式. AOP分动态注入和静态注入两种注入的方式. 动态注入方式 利用Remoting的Context ...
- 日志系统实战(二)-AOP动态获取运行时数据
介绍 这篇距上一篇已经拖3个月之久了,批评自己下. 通过上篇介绍了解如何利用mono反射代码,可以拿出编译好的静态数据.例如方法参数信息之类的. 但实际情况是往往需要的是运行时的数据,就是用户输入等外 ...
- 日志系统实战 AOP静态注入
http://www.cnblogs.com/mushroom/p/3932698.html http://www.cnblogs.com/mushroom/p/4124878.html http:/ ...
- atitit. 日志系统的原则and设计and最佳实践(1)-----原理理论总结.
atitit. 日志系统的原则and设计and最佳实践总结. 1. 日志系统是一种不可或缺的单元测试,跟踪调试工具 1 2. 日志系统框架通常应当包括如下基本特性 1 1. 所输出的日志拥有自己的分类 ...
- Android日志系统Logcat源代码简要分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/6606957 在前面两篇文章Android日志系 ...
- 【转载】CentOS日志系统组成详解
日志系统有三部分组成:一.使用什么工具记录系统产生的日志信息? syslog服务脚本管理的两个进程: syslogd.klogd 来记录系统产生的日志信息: klogd 进 ...
- 使用日志系统graylog获取Ceph集群状态
前言 在看集群的配置文件的时候看到ceph里面有一个graylog的输出选择,目前看到的是可以收集mon日志和clog,osd单个的日志没有看到,Elasticsearch有整套的日志收集系统,可以很 ...
- 搭建Loki、Promtail、Grafana轻量级日志系统(centos7)
搭建Loki.Promtail.Grafana轻量级日志系统(centos7)--简称PLG 需求 公司项目采用微服务的架构,服务很多,每个服务都有自己的日志,分别存放在不同的服务器上.当查找日志时需 ...
随机推荐
- Unity引擎IOS执行档大小优化
简介 苹果对于IOS执行档的大小是有明确的限制的,其中TEXT段的大小不能超过80M,否则提审将会被苹果拒绝,同时,如果TEXT段过于太大,那么在苹果进行加密之后,很容易出现解压失败等各种异常,最终导 ...
- linux 命令 ---- 同步当前服务器时间
原因:昨天临走前,虚拟机没有关机,是挂起状态,然后今天来的时候,发现数据库表中存(更新)的时间,不是系统时间, 解决:先运行起我们的虚拟机, (对于asterisk) 1.先查看当前服务器(linux ...
- 动画效果interpolator
Interpolator 被用来修饰动画效果,定义动画的变化率 AccelerateDecelerateInterpolator 在动画开始与结束的地方速率改变比较慢,在中间的时候加速 Accel ...
- Netty参数配置表
- iOS drewRect方法
You do not need to override this method if your view sets its content in other ways. By the time thi ...
- LeetCode 136. Single Number
最原始的方法:先排序,然后从头查找.若nums[i] = nums[i] + 1则为一对相同的数,i = i + 2,继续判断.若nums[i] != nums[i] + 1,则输出nums[i]. ...
- 从OOP的角度看Golang
资料来源 https://github.com/luciotato/golang-notes/blob/master/OOP.md?hmsr=toutiao.io&utm_medium=tou ...
- ng-repeat循环出来的部分调用同一个函数并且实现每个模块之间不能相互干扰
使用场景:用ng-repeat几个部分,每个部分调用同一个函数,但是每个模块之间的功能不能相互干扰 问题:在用repeat实现.content块repeat的时候打算这样做:新建一个空的数组(nmbe ...
- MYSQL的安装
1.将mysql的安装文件放入虚拟机 2.搭建yum库 3.依次安装mysql的5个文件 最后一个server需要的依赖太多,所以用yum进行安装. 6.进行mysql的重置 mysql_instal ...
- cocoapods
iOS 最新版 CocoaPods 的安装流程 1.移除现有Ruby默认源 $gem sources --remove https://rubygems.org/ 2.使用新的源 $gem sourc ...