RabbitMQ 分布式设置和高可用性讨论
abbitMQ的集群主要有配置方式,分别是:本地局域网Cluster,federation,shovel。
RabbitMQ Cluster主要是用于同一个网段内的局域网。
federation和shovel可以用于广域网,shovel比federation更底层,可以用于更多地方。
RabbitMQ Cluster配置
RabbitMQ Cluster是根据Erlang的实现的。必须满足一下几个要求:
- 所有机器上,必须Erlang运行时和RabbitMQ的版本相同。(否则会不能连接到一起)
- 所有机器上,的Erlang的Cookie都相同。
注意:由于RabbitMQ会使用Node@HostName,如果你在/etc/hosts里面定义了IP HostName关系,当你的IP发生变化时,命令行都会失去作用。
查看机器上的Erlang的Cookie。
linux上位置有两个地方。一个是在$HOME目录下的.erlang.cookie 另外在/var/lib/rabbitmq/.erlang.cookie
通过修改rabbitmq-server脚本文件和rabbitmqctl,在 erl 后面增加 -setcookie wugetestnodes
注意:必须两个脚本同时增加-setcookie "所以写相关cookie",否则rabbitmqctl无法控制对应的rabbitmq
服务器启动
每个节点运行一下命令:
$rabbitmq-server -detached #让当前rabbitmq-server的进程后台运行。
每个节点执行以下命令:
$rabbitmqctl cluster_status #获得集群配置信息。
例子:
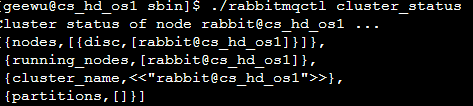
将节点加入到主节点中
首先停止正在运行的节点。
在节点2上运行以下命令:
sudo ./rabbitmqctl stop_app #停止rabbitmq运行
sudo .rabbitmqctl join_cluster --ram rabbit@cs_hd_os1 #加入到rabbit节点中,使用内存模式。
sudo ./rabbitmqctl cluster_status #查看状态

sudo ./rabbitmqctl start_app #启动rabbitmq
sudo ./rabbitmqctl cluster_status #查看状态
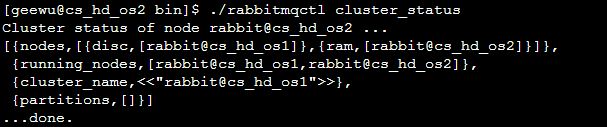
默认分布式现象
当设置完成基本Cluster结构之后,会将 Vhost为"/"下面的Queue队列同步。同步效果如下
节点1:
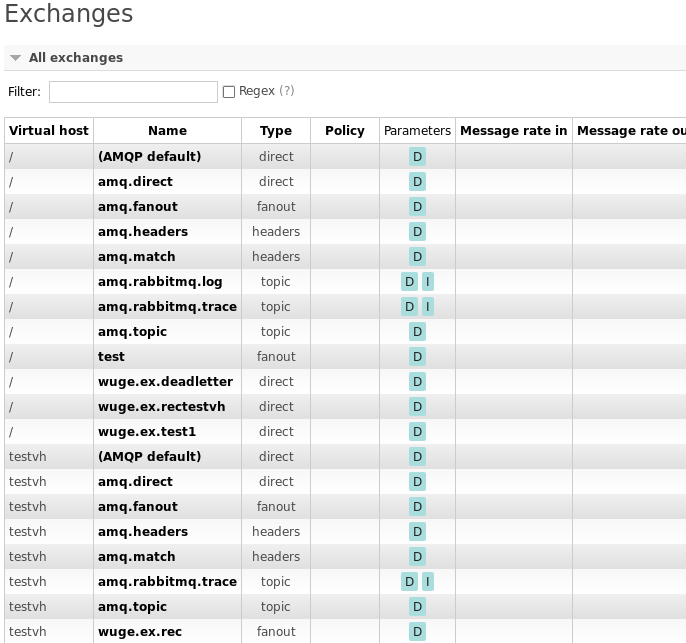
节点2 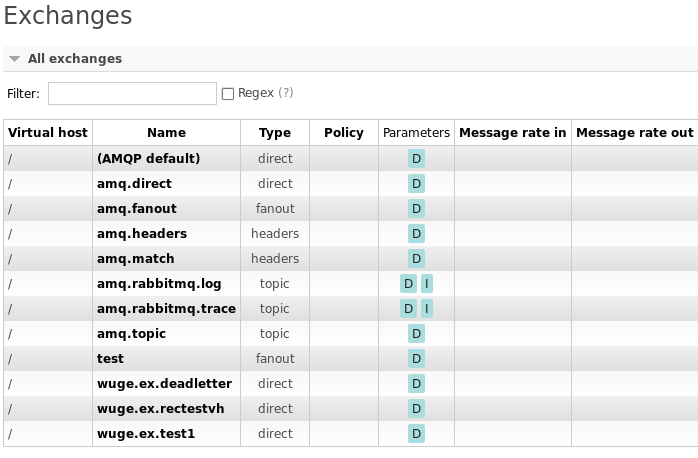
无论是从同一个Cluster中那个节点消费,队列状态都会进行同步.
修改节点类型
我们要将节点2的RAM类型修改为Disc类型。
./rabbitmqctl stop_app
./rabbitmqctl change_cluster_node_type disc
./rabbitmqctl start_app
./rabbitmqctl cluster_status
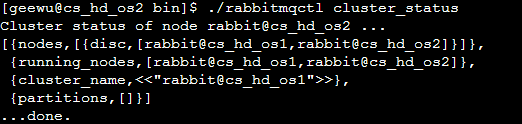
当Cluster集群中仅有一台机器为Disc情况下,这台机器不能修改存储状态。

当集群节点使用./rabbitmqctl stop_app情况下,集群其他节点保存停止节点的信息。但是运行状态会改变。
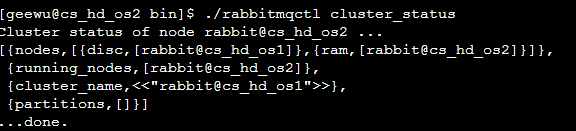
构建Cluster的数据高可靠性
场景描述:
有两台服务器,服务器一:cs_hd_os1。服务器二:cs_hd_os2 设置cs_hd_os2加入到cs_hd_os1的集群里面。
初始化创建Cluster集群数据情况
这里没有配置Policy相关文件。
- 当两台服务器rabbitmq都运行时候。在cs_hd_os1和cs_hd_os2可以看到在 vhost为"/"下的内容相互复制。(Exchange,Bind, Queue)都会复制到对方里面。
- 当其中一台停机之后,另外一台智能看到Exchange名称,Bind,Queue都消失了。
注意:两个RabbitMQ的Queue不能重名,重名之后会有异常产生。
当其中一个Node失效后,另外一个Node也失效
先启动最后一个失效的节点,节点不能启动。


这是因为数据库崩溃了。删除掉RabbitMQ的数据库就可以恢复了。
为节点配置HA策略
HA策略主要配置
HA的策略主要分为 三种:
| ha-mode | ha-params | 说明 |
|---|---|---|
| all | 空 | 镜像队列将会在整个集群中复制。当一个新的节点加入后,也会在这个节点上复制一份。 |
| exactly | count | 镜像队列将会在集群上复制count份。如果集群数量少于count时候,队列会复制到所有节点上。如果大于Count集群,有一个节点crash后,新进入节点也不会做新的镜像。(这位阻止集群雪崩) |
| nodes | node name | 镜像队列会在node name中复制。如果这个名称不是集群中的一个,这不会触发错误。如果在这个node list中没有一个节点在线,那么这个queue会被声明在client连接的节点。 |
节点策略与集群迁移
如果master节点没有包含在这个策略中的时候,只有当有一个slave node与Master同步完成之后,master才会离开。client将要重新连接服务器。
独有的队列(Exclusive queue)
独有的队列不会被镜像话,因为状态无法保证。
设置策略方法
方法1 :使用命令行来设置
set_policy [-p vhostpath] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}
| ha-mode | ha-params | 说明 |
|---|---|---|
| -p /wuge | 设置vhost信息。 | |
| --priority 10 | 设置优先级。高数字会优先处理。 | |
| --apply-to queue | 作用对象。queue、exchanges,all | |
| name | 规则名称 |
./rabbitmqctl set_policy -p '/wuge' --priority 9 --apply-to all testctl "^hello" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
方法2:通过restful API
/api/policies/%2Fwuge/testctl
{"vhost":"/wuge","name":"testctl","pattern":"^hello","apply-to":"all","definition":{"ha-mode":"all","ha-sync-mode":"automatic"}}
定义ha-sync-mode说明
ha-sync-mode分为两种状态设置:一种为手动"manual",另一种为自动"automatic"。 默认的设置为manual
我们可以通过使用rabbitmqctl来同步数据。
| 说明 | 命令 |
|---|---|
| 设置那两个系统之间进行同步 | rabbitmqctl list_queues name slave_pids synchronised_slave_pids |
| 手动同步那个队列 | rabbitmqctl sync_queue name |
| 手动终止对应的队列 | rabbitmqctl cancel_sync_queue name |
分布式数据同步
新的Slave节点加入的处理方法
一个新的Slave节点加入,他需要同步其他节点的数据。而当同步数据的时候,当前同步的Queue就不能被使用。(无法发送消息到Queue中,也无法从里面获取消息进行处理)。

在Slave之间进行数据同步的时候,如果是police策略范围内的。(例如本例:task_police策略中,有task名称开头,性能下降严重)。所有的消息发送和消息消费,性能都降低到极点。仅仅是非同步策略的1/10。

而发送到一个没有策略的数据时候,性能得到很高的提升。与原来相同。
我们可以得到以下结论:
- 在策略下,多个node节点Mirror会降低性能。
- 同步状态下,同步的Queue不能接受数据。其他Queue性能会受到影响。(有同步策略的Queue都有影响,性能降低到1/10。没有同步策略的Queue,性能几乎没有变化。如果没有同步状态,对比单服务器性能下降到1/3)。
- 同步状态下,对非同一个同步策略下的Queue影响。
两个Slave节点的Queue数据之间进行同步之前,最好让Queue中数据被消费完全。否则同步会造成性能的集体降低。
RabbitMQ网络分区影响和选择
在rabbitMQ中,我们可能会因为network partition,导致rabbitmq集群出现不同组。rabbitmq给了我们特定的三个选择。
| ignore(默认) | 认为网络非常好,所有机器都在同一个交换机上。 |
| pause_minority | 暂停,选择最小集群作为可信集群,重新启动其他集群。 |
| autoheal | 根据连接数最高的节点,重启其他节点。 |
如何判断cluster保持状态。 当节点交互keepalive时间超过之后,就会认为节点失败。
[{rabbit:[{cluster_partiton_handling:ignore},{cluster_keepalive_interval:10000}]}]
RabbitMQ同步讨论
当RabbitMQ服务器Mirror Queue队列的其中一个Slave Node停止之后,重新连接到Master Node之后,无论数据是否有变动,都会重新验证数据是否同步。(根据同步状态的时间消耗,可以获知第一次同步时候,会重新发送消息。而第一次同步之后,再次同步不会所有数据都同步)。
同步会造成发送端暂停,数据不会再被发送,客户端会一直等待服务器Broker的Queue队列完成同步。当客户端Producer一直要发送数据到服务端,从而造成IO等待,不能发送数据完成。
解决相关问题:
1,使用Exchange,动态修改Exchange和Queue的版本。 2,举例说明:
首先定义一个Exchange。为task_Exchange.
定义两个queue,为task_queue和task_otherqueue
现将task_Exchange和task_queue构建消费队列。
发送数据到task_Exchange和task_queue,使用routekey为test。当task_queue堆积过大,而且也需要同步的时候。
可以绑定task_Exchange和task_otherqueue。也是用routekey为test。并且取消task_Exchange和task_queue绑定。数据就会发送到其他队列。从而减少阻塞造成的影响。
我通过实验发现,不可以在同步状态下进行以上操作,必须在非同步状态下修改。同步状态会导致客户端连接错误。

RabbitMQ 分布式设置和高可用性讨论的更多相关文章
- 关于RabbitMQ分布式集群架构
RabbitMQ分布式集群架构和高可用性(HA) (一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配 ...
- RabbitMQ分布式集群架构和高可用性(HA)
(一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配置方式 RabbitMQ可以通过三种方法来部署分布 ...
- jmeter 环境部署、数据库设置、分布式设置、多网卡配置等随笔
<!-- linux系统修改系统环境变量 系统语言-->[root@web-249 ~]# env|grep LANGLANG=zh_CN.UTF-8[root@web-249 ~]# ...
- Windows安装RabbitMQ并设置数据存储目录
一.安装Elang 下载otp_win64_xx.x.exe,当前使用otp_win64_21.3.exe版本,按步骤完成安装. 下载地址:http://www.erlang.org/download ...
- CentOS7安装RabbitMQ,并设置远程访问
如果网速慢 可以直接到百度云分享中下载,然后拉到centerOS中,进行第二步即可 两个人安装包地址,提取码:z1oz 1.安装erlang环境 wget http://www.rabbit ...
- RabbitMQ分布式消息队列服务器(一、Windows下安装和部署)
RabbitMQ消息队列服务器在Windows下的安装和部署-> 一.Erlang语言环境的搭建 RabbitMQ开源消息队列服务是使用Erlang语言开发的,因此我们要使用他就必须先进行Erl ...
- Python RabbitMQ 权重设置
消费端recv设置 注:设置消费端处理完一条消息后再发另一条 channel.basic_qos(prefetch_count=1) 由于每一条机器的处理速度不同,所以我们这里就会对应,机 ...
- ABP vNext EventBus For RabbitMQ 分布式事件总线使用注意事项_补充官网文档
[https://docs.abp.io/zh-Hans/abp/latest/Distributed-Event-Bus-RabbitMQ-Integration](ABP vNext官方文档链接) ...
- 搭建 RabbitMQ Server 高可用集群
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
随机推荐
- Python gensim库word2vec 基本用法
ip install gensim安装好库后,即可导入使用: 1.训练模型定义 from gensim.models import Word2Vec model = Word2Vec(senten ...
- goland激活码
http://idea.youbbs.org
- 第一部分:开发前的准备-第三章 Application 基本原理
第3章 应用程序基本原理 首先我们需要强调一下Android 应用程序是用java写的.Android SDK工具编译代码并把资源文件和数据打包成一个文件.这个名字的扩展名是.APK.要在androi ...
- 物联网架构成长之路(3)-EMQ消息服务器了解
1. 了解 物联网最基础的就是通信了.通信协议,物联网协议好像有那么几个,以前各个协议都有优劣,最近一段时间,好像各大厂商都采用MQTT协议,所以我也不例外,不搞特殊,采用MQTT协议,选定了协议,接 ...
- 10个对Web开发者最有用的Python包
Python最近成为了开发人员最喜欢的语言之一.无论你是专业的,业余的,还是一个初学者,你都可以从Python语言及其程序包中受益.Python已经被证明是当今最具活力的面向对象的编程语言之一.这就是 ...
- MT7601 WG209模块驱动移植,并连接路由器
驱动位置: https://github.com/Aplexchenfl/WG209_MT7601 下载之后,查看 Makefile 在这里,我修改了 kernel的位置以及编译器的版本 执行 mak ...
- Go Revel - Logging(日志)
revel提供了4种日志记录器: 1.`TRACE` - 调试信息 2.`INFO` - 信息 3.`WARN` - 一些无害的异常信息 4.`ERROR` - 必须要关注的错误 日志记录器可以在`a ...
- 【原】关于AdaBoost的一些再思考
一.Decision Stumps: Decision Stumps称为单层分类器,主要用作Ensemble Method的组件(弱分类器).一般只进行一次判定,可以包含两个或者多个叶结点.对于离散数 ...
- AllPay(欧付宝)支付接口集成
AllPay,http://www.allpay.com.tw/,欧付宝是台湾知名的第三方支付公司,拥有丰富的支付模式(支持和支付宝.财付通),只需要一次对接,各种支付模式均可使用. 接口编写SDK: ...
- 大数据基础篇----jvm的知识点归纳-5个区和垃圾回收机制
一直对jvm看了又忘,忘了又看的.今天做一个笔记整理存放在这里. 我们先看一下JVM的内存模型图: 上面有5个区,这5个区干嘛用的呢? 我们想象一个场景: 我们有一个class文件,里面有很多的类的定 ...