Hive复制分区表和数据
1. 非分区表:
复制表结构: create table new_table as select * from exists_table where 1=0;
复制表结构和数据: create table new_table as select * from exists_table;
2. 分区表:
-- 创建一个分区表 drop table if exists kimbo_test; create table kimbo_test ( order_id int, system_flag string ) PARTITIONED BY(dt string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' STORED AS TEXTFILE ; -- 插入数据 insert overwrite table kimbo_test partition(dt=') values (,,'B') ; insert overwrite table kimbo_test partition(dt=') values (,,'W') ; create table test_par like kimbo_test; -- 用 as select 复制一个新表 create table test_par2 as ; -- 用 like 复制一个新表 create table test_par3 like kimbo_test; -- 注意差异: as select 复制的是一个非分区表, like 复制的是一个分区表。
表结构截图:
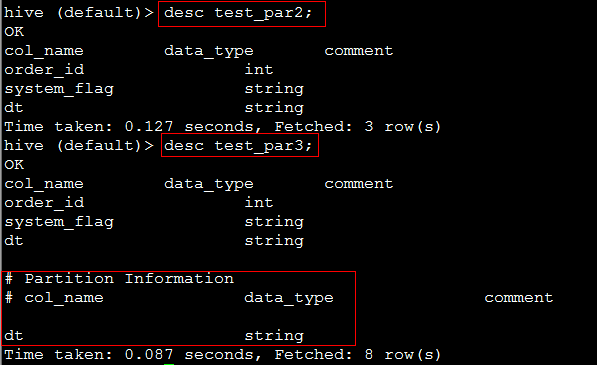
3. 将原表的数据复制到 新表(test_par3)
1. 创建新表: create table test_par3 like kimbo_test;
2. 将HDFS的数据文件复制一份到新表目录,hive cmd模式下: dfs -cp -f /user/hive/warehouse/kimbo_test/* /user/hive/warehouse/test_par3/
3. 修复分区元数据信息,hive cmd模式下: MSCK REPAIR TABLE test_par3;
结果查询:

参考博客:https://www.cnblogs.com/kimbo/p/7102571.html
Hive复制分区表和数据的更多相关文章
- Hive 复制分区表和数据
1. 非分区表: 复制表结构: create table new_table as select * from exists_table where 1=0; 复制表结构和数据: create tab ...
- 一起学Hive——总结复制Hive表结构和数据的方法
在使用Hive的过程中,复制表结构和数据是很常用的操作,本文介绍两种复制表结构和数据的方法. 1.复制非分区表表结构和数据 Hive集群中原本有一张bigdata17_old表,通过下面的SQL语句可 ...
- hive 修复元数据命令 & 如何快速复制一张hive的分区表
hive 元数据修复命令 msck repair table xxx; 也可以用于分区表的快速复制 例如你需要从线上往线下导一张分区表,但是网又没有连通,你需要如何操作呢? 1.复制建表语句 2.从线 ...
- hive(在大数据集合上的类SQL查询和表)学习
1.jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&use ...
- hive加载json数据解决方案
hive官方并不支持json格式的数据加载,默认支持csv格式文件加载,如何在不依赖外部jar包的情况下实现json数据格式解析,本编博客着重介绍此问题解决方案 首先创建元数据表: create EX ...
- Hive数据导入——数据存储在Hadoop分布式文件系统中,往Hive表里面导入数据只是简单的将数据移动到表所在的目录中!
转自:http://blog.csdn.net/lifuxiangcaohui/article/details/40588929 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop ...
- hive建表与数据的导入导出
建表: create EXTERNAL table tabtext(IMSI string,MDN string,MEID string,NAI string,DestinationIP string ...
- 使用hive访问elasticsearch的数据
使用hive访问elasticsearch的数据 1.配置 将elasticsearch-hadoop-2.1.1.jar拷贝到hive/lib hive -hiveconf hive.aux.jar ...
- ORACLE+PYTHON实战:复制A表数据到B表
最近在学习python ,看到了pythod的oracle,不仅可以一次fetch多条,也可以一次insert多条,想写一个复制A表数据到B表的程序来看看实际效率能不能提高.写完发现,非常惊艳!效率提 ...
随机推荐
- python3 open()函数调用方法简单示例
python3 open()函数调用简介.Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError. 注 ...
- MySQL准入规范及容量评估
一.数据库设计 1.表结构设计 -表中的自增列(auto_increment属性)推荐使用bigint类型 -首选使用非空的唯一键, 其次选择自增列或发号器 不使用更新频繁的列,尽量不选择字符串列,不 ...
- Font Awesome 最简单应用例子
简介: Font Awesome为您提供可缩放的矢量图标,您可以使用CSS所提供的所有特性对它们进行更改,包括:大小.颜色.阴影或者其它任何支持的效果. 使用方法: 引入<link rel=&q ...
- 十步完全理解SQL(转载)
1. SQL 是一种声明式语言 首先要把这个概念记在脑中:“声明”. SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例,而不是告诉计算机如何能够得到结果.这是不是很棒? (译 ...
- Learn golang: Top 30 Go Tutorials for Programmers Of All Levels
https://stackify.com/learn-go-tutorials/ What is Go Programming Language? Go, developed by Google in ...
- Tx.Origin 用作身份验证
Solidity 中有一个全局变量,tx.origin,它遍历整个调用栈并返回最初发送调用(或交易)的帐户的地址.在智能合约中使用此变量进行身份验证会使合约容易受到类似网络钓鱼的攻击. 有关进一步阅读 ...
- leetcode 198打家劫舍
讲解视频见刘宇波leetcode动态规划第三个视频 记忆化搜索代码: #include <bits/stdc++.h> using namespace std; class Solutio ...
- Go linux 实践4
这是目前学习的最难的Go demo例子 ***************************************** 如果能看懂,你就出师了,我的任务也就结束了 **************** ...
- jQuery UI 中Tabs Ajax载入时出现Http 304的问题
最近发现jQueryUI中tabs的ajax载入,总是会出现304未修改的情况,明明数据有变化的么~应该返回200才对. 于是尝试在beforeLoad中设置: ui.ajaxSettings.cac ...
- 巧用CurrentThread.Name来统一标识日志记录(java-logback篇)
▄︻┻┳═一Agenda: ▄︻┻┳═一巧用CurrentThread.Name来统一标识日志记录 ▄︻┻┳═一巧用CurrentThread.Name来统一标识日志记录(续) ▄︻┻┳═一巧用Cur ...