Storm(三)Storm的原理机制
一.Storm的数据分发策略
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。 轮询,平均分配
2. Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,把tuple分配给task id最低的task 。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8.customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
二.Storm的并发机制
Worker – 进程
一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology) 这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中多台服务器上的进程所组成
Executor – 线程
Executor是由Worker进程中生成的一个线程 每个Worker进程中会运行拓扑当中的一个或多个Executor线程 一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些Task任务都是对应着同一个组件(Spout、Bolt)。
Task
实际执行数据处理的最小单元 每个task即为一个Spout或者一个Bolt Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整 (默认情况下,Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务)
设置Worker进程数
Config.setNumWorkers(int workers)
设置Executor线程数
TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint) ,TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint) :其中, parallelism_hint即为executor线程数
设置Task数量
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
Rebalance – 再平衡
即,动态调整Topology拓扑的Worker进程数量、以及Executor线程数量
支持两种调整方式: 1、通过Storm UI 2、通过Storm CLI
通过Storm CLI动态调整: storm help rebalance
例:storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 将mytopology拓扑worker进程数量调整为5个, “ blue-spout ” 所使用的线程数量调整为3个 ,“ yellow-bolt ”所使用的线程数量调整为10个。
三.Storm的通信机制
Worker进程间的数据通信
ZMQ ZeroMQ 开源的消息传递框架,并不是一个MessageQueue Netty Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
Worker内部的数据通信
Disruptor 实现了“队列”的功能。 可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。
Worker内部的消息传递机制
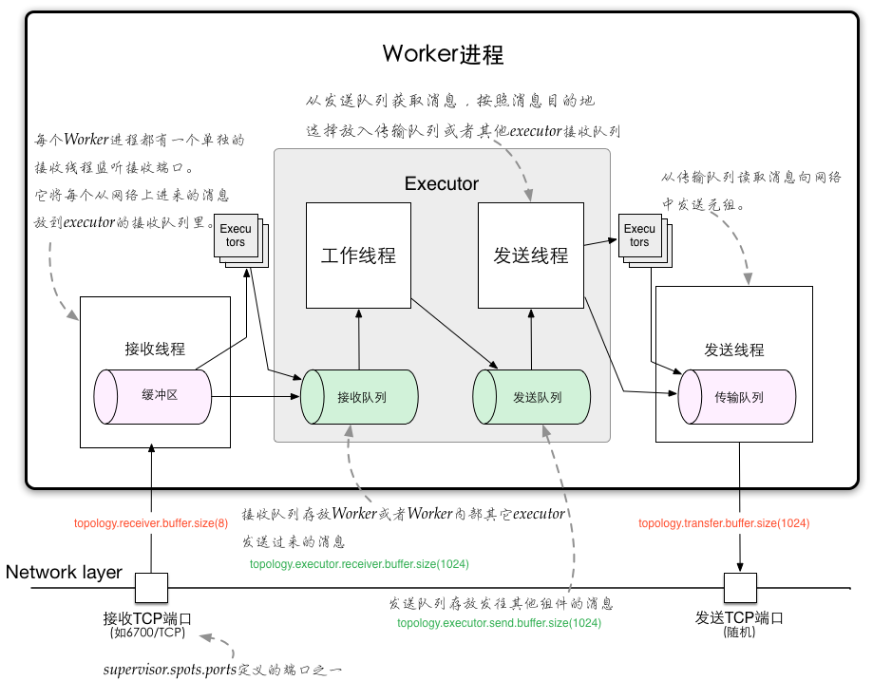
四.Storm的容错机制
1、集群节点宕机
Nimbus服务器 单点故障? 非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimbus会将这些Task任务重新分配到其他服务器上运行
2、进程挂掉
Worker 挂掉时,Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该Worker重新分配到其他服务器上 Supervisor 无状态(所有的状态信息都存放在Zookeeper中来管理) 快速失败(每当遇到任何异常情况,都会自动毁灭) Nimbus 无状态(所有的状态信息都存放在Zookeeper中来管理) 快速失败(每当遇到任何异常情况,都会自动毁灭)
3、消息的完整性

从Spout中发出的Tuple,以及基于他所产生Tuple(例如上个例子当中Spout发出的句子,以及句子当中单词的tuple等) 由这些消息就构成了一棵tuple树 当这棵tuple树发送完成,并且树当中每一条消息都被正确处理,就表明spout发送消息被“完整处理”,即消息的完整性
Acker -- 消息完整性的实现机制 Storm的拓扑当中特殊的一些任务 负责跟踪每个Spout发出的Tuple的DAG(有向无环图)
五.Storm的DRPC
DRPC (Distributed RPC) 分布式远程过程调用
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。 DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm中运行的 Topology,等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。 (其实,从客户端的角度来说,DPRC 与普通的 RPC 调用并没有什么区别。)
DRPC设计目的: 为了充分利用Storm的计算能力实现高密度的并行实时计算。 (Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。)
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一个函数调用流。DRPC 服务器会为每个函数调用都标记了一个唯一的 id。随后拓扑会执行函数来计算结果,并在拓扑的最后使用一个名为 ReturnResults 的 bolt 连接到 DRPC 服务器,根据函数调用的 id 来将函数调用的结果返回。
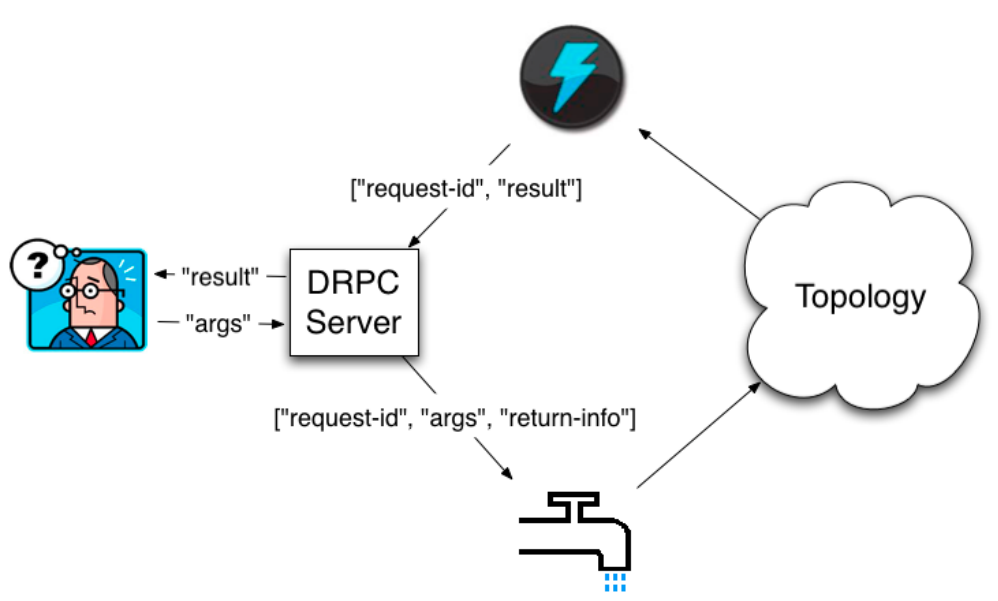
定义DRPC拓扑:
方法1: 通过LinearDRPCTopologyBuilder (该方法也过期,不建议使用) 该方法会自动为我们设定Spout、将结果返回给DRPC Server等,我们只需要将Topology实现

方法2: 直接通过普通的拓扑构造方法TopologyBuilder来创建DRPC拓扑 需要手动设定好开始的DRPCSpout以及结束的ReturnResults

运行模式:
1、本地模式

2.远程模式(集群模式)
修改配置文件conf/storm.yaml drpc.servers: - "node21“ 启动DRPC Server bin/storm drpc & 通过StormSubmitter.submitTopology提交拓扑
六.Storm的事务
事务性拓扑(Transactional Topologies)
保证消息(tuple)被且仅被处理一次
Design 1
强顺序流(强有序) 引入事务(transaction)的概念,每个transaction(即每个tuple)关联一个transaction id。 Transaction id从1开始,每个tuple会按照顺序+1。 在处理tuple时,将处理成功的tuple结果以及transaction id同时写入数据库中进行存储。
两种情况:
1、当前transaction id与数据库中的transaction id不一致
2、两个transaction id相同
缺点: 一次只能处理一个tuple,无法实现分布式计算
Design 2
强顺序的Batch流
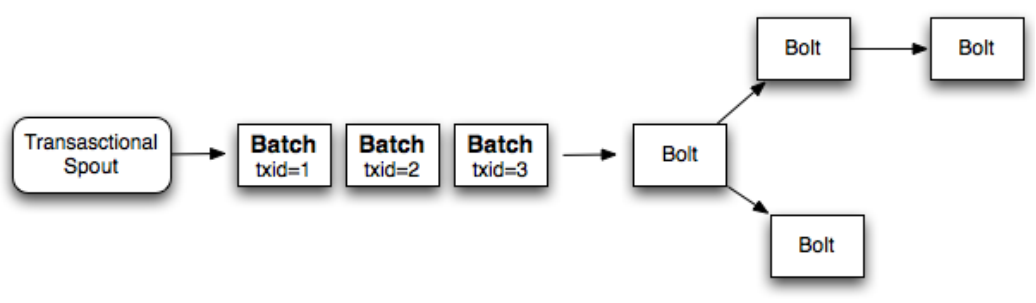
事务(transaction)以batch为单位,即把一批tuple称为一个batch,每次处理一个batch。 每个batch(一批tuple)关联一个transaction id ,每个batch内部可以并行计算
缺点

Design 3
Storm's design
将Topology拆分为两个阶段:
1、Processing phase 允许并行处理多个batch
2、Commit phase 保证batch的强有序,一次只能处理一个batch
Design details
Manages state - 状态管理
Storm通过Zookeeper存储所有transaction相关信息(包含了:当前transaction id 以及batch的元数据信息)
Coordinates the transactions - 协调事务
Storm会管理决定transaction应该处理什么阶段(processing、committing)
Fault detection - 故障检测
Storm内部通过Acker机制保障消息被正常处理(用户不需要手动去维护)
First class batch processing API
Storm提供batch bolt接口
三种事务:
1、普通事务
2、Partitioned Transaction - 分区事务
3、Opaque Transaction - 不透明分区事务
Storm(三)Storm的原理机制的更多相关文章
- 【转】apache storm 内置的定时机制
原文:http://www.cnblogs.com/kqdongnanf/p/4778672.html ------------------------------------------------ ...
- Nimbus<三>Storm源码分析--Nimbus启动过程
Nimbus server, 首先从启动命令开始, 同样是使用storm命令"storm nimbus”来启动看下源码, 此处和上面client不同, jvmtype="-serv ...
- Storm学习笔记 - 消息容错机制
Storm学习笔记 - 消息容错机制 文章来自「随笔」 http://jsynk.cn/blog/articles/153.html 1. Storm消息容错机制概念 一个提供了可靠的处理机制的spo ...
- Java提高篇——JVM加载class文件的原理机制
在面试java工程师的时候,这道题经常被问到,故需特别注意. 1.JVM 简介 JVM 是我们Javaer 的最基本功底了,刚开始学Java 的时候,一般都是从“Hello World ”开始的,然后 ...
- TCP三次握手原理详解
TCP/IP协议不是TCP和IP这两个协议的合称,而是指因特网整个TCP/IP协议族. 从协议分层模型方面来讲,TCP/IP由四个层次组成:网络接口层.网络层.传输层.应用层. TCP协议:即传输控制 ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- JVM加载class文件的原理机制
Java中的所有类,都需要由类加载器装载到JVM中才能运行.类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中.在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的 ...
- JVM加载class文件的原理机制(转)
JVM加载class文件的原理机制 1.Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中 2.java中的 ...
- Java加载Class文件的原理机制
详见:http://blog.sina.com.cn/s/blog_6cbfd2170100ljmp.html 1.Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器 ...
随机推荐
- typealias
类的别名
- 《深入理解java虚拟机》第二章 Java内存区域与内存溢出异常
第二章 Java内存区域与内存溢出异常 2.2 运行时数据区域
- Regex实例
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- sql 储存过程的使用
--获取所有数据 根据自定义函数传人类型id返回类型名称 USE [Cloths] GO /****** Object: StoredProcedure [dbo].[Proc_all] Script ...
- quartz开源插件(定时心跳后台执行)
定时心跳,一般应用场景都是服务或者exe控制台程序来搜集数据推送等,供其他页面来调用或者向服务推送等,但又不限于此. 1.先来介绍下quartz吧. 2.quartz用法: 3.我写个小例子来巩固下q ...
- proxysql 系列~审核功能
一 简介:今天我们来探讨下具体的审核功能 二 平台审计功能 一 proxysql 设置 set mysql-eventslog_filename = '/data/ProxySQL/log/sql. ...
- ros navigation stack 各个包的作用
nav_core 该包定义了整个导航系统关键包的接口函数,包括base_global_planner, base_local_planner以及recovery_behavior的接口.里面的函数全是 ...
- 【转】Shell编程基础篇-上
[转]Shell编程基础篇-上 1.1 前言 1.1.1 为什么学Shell Shell脚本语言是实现Linux/UNIX系统管理及自动化运维所必备的重要工具, Linux/UNIX系统的底层及基础应 ...
- Kaggle 泰坦尼克
入门kaggle,开始机器学习应用之旅. 参看一些入门的博客,感觉pandas,sklearn需要熟练掌握,同时也学到了一些很有用的tricks,包括数据分析和机器学习的知识点.下面记录一些有趣的数据 ...
- spring data redis使用1——连接的创建
spring data redis集成了几个Redis客户端框架,Jedis , JRedis (Deprecated since 1.7), SRP (Deprecated since 1.7) a ...