pandas数据表

安装 pip3 install pandas
s=pd.Series([1,3,6,90,44,1]) #创建序列【用列表创建】。数据源的维度必须是一维
#data 指定数据源
print(s)

前面自动产生一个序号
s=pd.Series(data=np.arange(5,9),index=['语文','数学','物理','化学']) #创建序列[用numpy创建]
# index 指定索引

dic={'物理':87,'化学':67,'语文':77,'数学':54}
s=pd.Series(data=dic) #创建序列[用字典创建].
#不能使用index 字典中的key就是索引
s=pd.date_range(start='20170101',end='20170105') #生成一个日期时间索引
# start 指定开始时间; end 指定结束时间

s=pd.date_range(start='20170101',periods=4)
# periods 数据的个数

s=pd.date_range(start='20170101',periods=6,freq='2D')
#freq:日期偏移量,取值为string或DateOffset,默认为'D'

s=pd.date_range(start='20170101',end='20170110',freq='3D',name='dt')
# 对象的名称
s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s')
# 偏移量是 秒

s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s',normalize=True)
#normalize:若参数为True表示将start、end参数值正则化到午夜时间戳

s=pd.date_range(start='20170101',end='20170110',freq='3D')
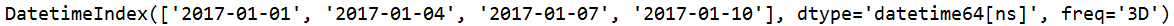
s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='left')
#顾左不顾右
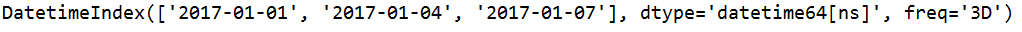
与上图对比一下
s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='right')
#closed='right' 顾右不顾左
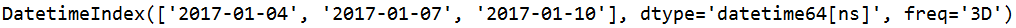
与上面两图对比一下
q=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD')) #创建数据表
#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表
#DataFrame可以设置列名columns与行名index,可以通过位置获取数据也可以通过列名和行名定位
#第一个参数是存放在数据表里的数据 可以是:numpy的矩阵对象、字典、列表
#index就是设置行名 columns设置列明 可以省略
#后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配

s=pd.date_range(start='20170101',end='20170110',freq='3D')
q=pd.DataFrame(np.random.randn(4,4),index=s,columns=list('ABCD')) #创建数据表
# s 是date_range日期时间索引对象

dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'性别':['男','女','女','男']}
q=pd.DataFrame(dic1) #用字典创建数据表
#每个key的value代表一列,而key是这一列的列名

s=q.dtypes #返回各列的数据类型

q=pd.DataFrame(np.random.randn(6,6))
s=q.head(3) #返回数据表前n行数据
#参数 指定行数 默认5

s=q.tail(3) #返回数据表后n行数据

s=q.index #返回数据表的行名
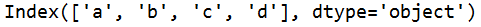
s=q.columns #返回数据表的列名

s=q.values #返回数据表的数据
#返回值类型:numpy矩阵

s=q['B'].values #返回B列的数据
#返回值类型:numpy矩阵
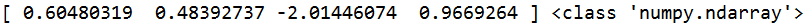
s=q.loc['b'] #返回b行的列名和对应的数据
#只能根据行来查看

s=q.iloc[1] #返回指定索引行的列名和对应的数据

s=q.shape[0] #查看数据表行数 4 <class 'int'>
s=q.shape[1] #查看数据表列数 4 <class 'int'>
s=q.T #行列转置
s=q.describe() #对数值型的列进行统计
#如果想对行进行描述性统计,转置后进行describe
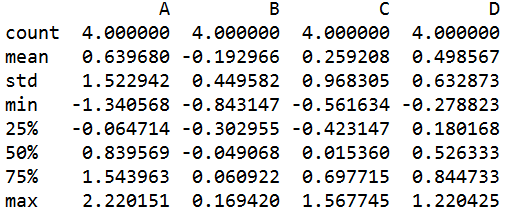
count 行数 mean 平均值 std 标准差
min 最小值 max 最大值
s=q.sum() #对所有列求和
s = self.df['物理'].sum() #对物理列求和
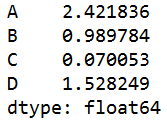
如果是文本列,就是把所有文本加成一个字符串
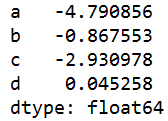
s=q.sum(1) #对每行求和
#而一行中,有字符串有数值则只计算数值
x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.apply(lambda x:x*2) #对每个元素进行计算
#如果元素是字符串,则会把字符串再重复一遍
#乘方运算如果有元素是字符串的话,会报错

q['E']=[99,34,12,3] #在后面添加一列
#E 添加的列名

q.insert(1,'F',[88,888,8,888]) #插入一列
#参数1 插入列的索引 其他的列顺延
# 参数2 列名

df6=pd.DataFrame(['my','name','is','a'],index=list('abch'),columns=list('G'))
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],index=list('abcd'),columns=list('ABCD'))
s=df2.join(df6) #把df6合并到df2
#根据行名 列名 来合并
#两个表有列名相同时就会报错
#s的行是以df2的行index为基准的,在df2相应行不存在数据时,就NaN=空 来填充
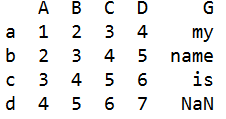
df8=df2.join(df6,how='inner') #把df6合并到df2
#how='inner' 交集:只返回两个数据表相同行名的行

df9=df2.join(df6,how='outer') #把df6合并到df2
#'outer'表示并集 :返回两个表的所有行
#如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe
df10=pd.DataFrame([1,2,3,4],index=list('abcd'),columns=['A'])
df11=pd.DataFrame([10,20,30,40],index=list('abcd'),columns=['B'])
df12=pd.DataFrame([100,200,300,400],index=list('abcd'),columns=['A'])
list1=[df10, df11, df12]
df13=pd.concat(list1) #合并多个数据表
#参数 是 数据表的列表
#df13 的列是所有数据表不同列名的总和
#df13 的行是所有数据表的总行数
x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.sort_index(axis=0,ascending=False)#排序.根据列名或行名
#axis=1 对列名排序;axis=0 对行名排序
#ascending=False 降序;ascending=True 升序
s=q.sort_values(by='b',ascending= False,axis=1) #排序。根据数据
#by 根据哪一行或哪一列
#ascending=False 降序;ascending=True 升序
#axis=1 根据某行数据; axis=0 根据某列数据
df.sort_values(by='物理',inplace=True) #排序--根据数据排序
#by='物理'--排序的列
#inplace=True---在原数据表排序,不生成新数据表
s=q['A'] #返回某列数据
s=q.A #返回某列数据

s=q[['B','C']] #返回某n列的数据

s=q[1:3] #返回1到3行的数据。骨头不顾尾
s=q['b':'c'] #返回b行到c行的数据。包括c行
s=q.loc['b'] #返回b行数据

s=q.loc[:,['B','C']] #返回B列、C列所有行的数据

s=q.loc['c',['B','C']] #返回c行的B列、C列数据
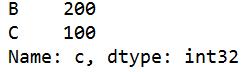
s=q.iloc[1:3,1:3] #返回第一行到第三行的第一列到第三列数据
s=q.iloc[2] #返回某行数据
s=q.iloc[2,2] #返回某行某列的数据
s=q.iloc[[1,3],1:3] #返回第一行和第三行的第一列到第三列数据
s=q.ix[0:3,['A','C']] #返回 0:3行,A列和C列 【混合筛选】
s=q.ix[['a','c'],0:3] #返回 a行c行,0:3列
s=q[q.A>8] #筛选A列大于8的所有数据

e=[40,200]
s=q[q['B'].isin(e)] #筛选出所有B列的值在e=[40,200]这个范围内的记录

q[q.B>20]=0 #B列>20的行数据都改成0
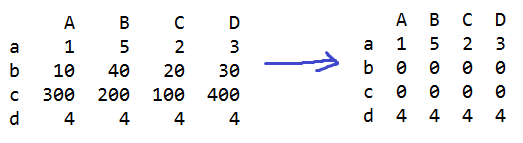
q.A[q.B>20]=0 #B列>20的A列行数据都改成0

s=q.dropna(axis=0,how='any') #删除存在NaN时的数据
#axis=0 删除存在NaN所在行 ;axis=1 删除存在NaN所在列
#how='any' 存在一个NaN时就删除;how='all' 都是NaN时才删除

s=q.fillna(value=0) #把NaN都改成0

s=q.fillna({'A':10,'B':20,'C':30}) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30
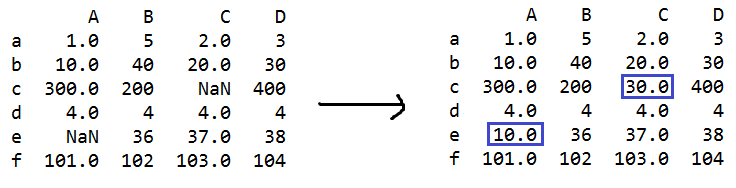
q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30
#inplace=True 不创建副本,在原数据表中修改
s=q.fillna(method='ffill')
#method='ffill' 或者 method='pad' 用前一个非缺失值去填充NaN
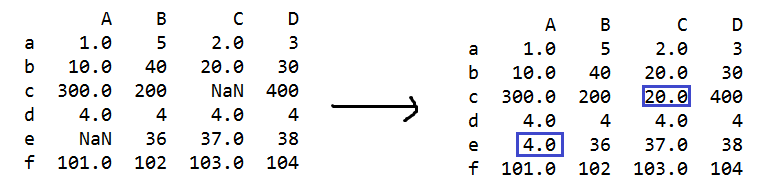
s=q.fillna(method='backfill') #用下一个非缺失值填充NaN

s=q.fillna(method='backfill',limit=1)
#limit=1 限制每列或每行连续NaN的修改次数

s=q.fillna(method='backfill',limit=1,axis=1)
#limit=1 限制每列或每行连续NaN的修改次数
#axis=1 limit按行方向计算;axis=0 limit按列方向计算
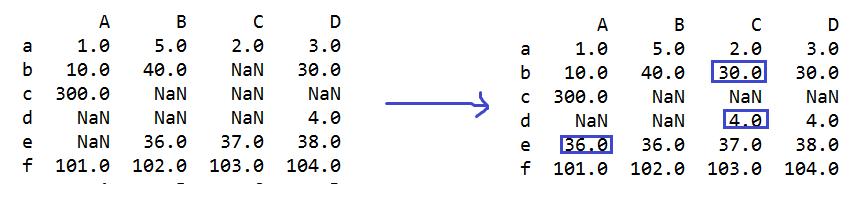
s=q.isnull() #判断每个元素是否为缺省值NaN
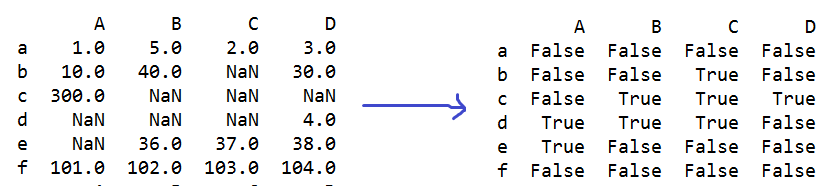
e=np.any(s) == True #s数据表中只要有一个数据是True就返回True
e=np.all(s) == True #s数据表中所有数据都是True就返回True
Pandas中的数据可以加载、存储的文件格式:

q=pd.read_csv(r'D:/ss/成绩1.csv') #读取CSV(逗号分割)文件到数据表
q.to_pickle(r'D:/ss/成绩1.pickle') #把数据表存储为pickle文件
s=pd.concat([q,q1,q2],axis=0,ignore_index=True) #数据表合并
#axis=0 纵向合并
#ignore_index=True 新数据表的索引重新排列

s=pd.concat([q,q3],axis=0,ignore_index=True,join='outer') #数据表合并
#join='outer' 各表中不同的列名或行名 都合并
#join='inner' 只取各表相同的列名或行名


s=pd.concat([q,q3],axis=1,ignore_index=True,join_axes=[q.index]) #数据表合并
#join_axes=[q.index] 横向合并时只取q的行
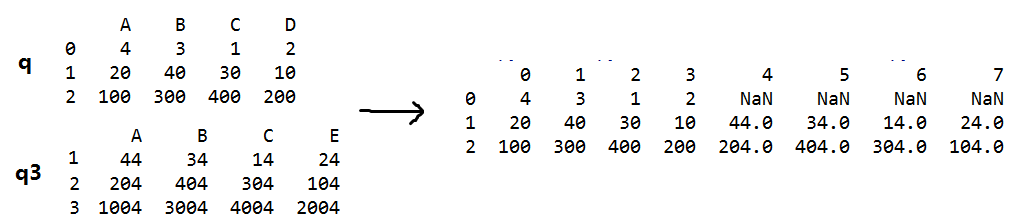
s=pd.concat([q,q3],axis=0,ignore_index=True,join_axes=[q.columns]) #数据表合并
#join_axes=[q.columns] 纵向合并时只取q的列

s=q.append(q1,ignore_index=True) #在q表后面追加q1表
#不修改q1表
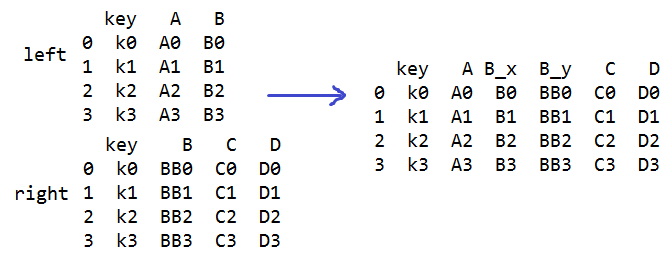
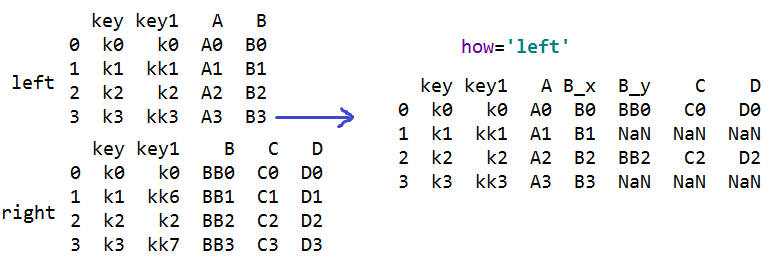
s=pd.merge(left,right,on='key') #合并数据表
#on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次
#非连接键都会出现,有同名的会自动改名
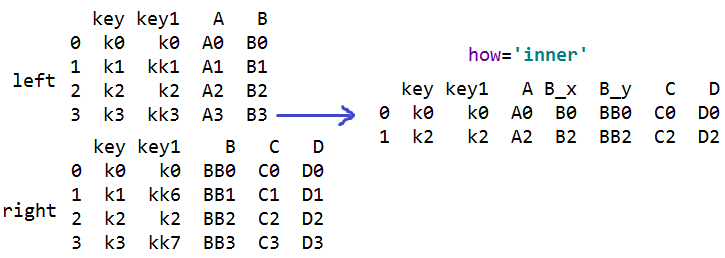
s=pd.merge(left,right,on=['key','key1']) #合并数据表,多个连接键合并
#on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次
#非连接键都会出现,有同名的会自动改名
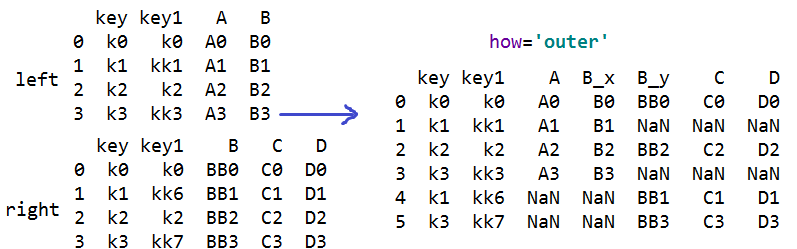
#多个连接键合并:how='inner' 只会合并连接键相同的行,默认;
#how='outer' 都合并进来
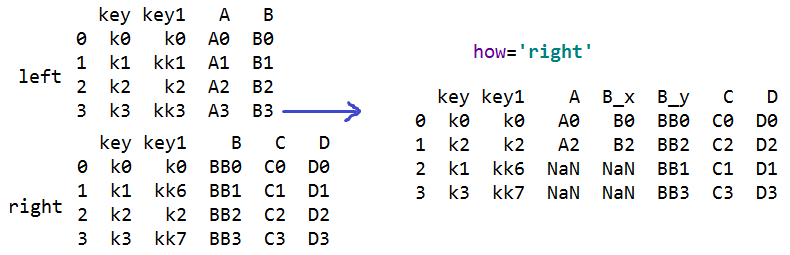
#how='right' 只合并右对象的连接键
#how='left' 只合并左对象的连接键
#indicator=True 显示出此行在哪个表格中出现

import pandas as pd
import numpy as np s=pd.Series(data=[1,3,6,90,44,1]) #创建序列[用列表创建]。数据源的维度必须是一维
#data 指定数据源
s=pd.Series(data=np.arange(5,9),index=['语文','数学','物理','化学']) #创建序列[用numpy创建]
# index 指定索引
dic={'物理':87,'化学':67,'语文':77,'数学':54}
s=pd.Series(data=dic) #创建序列[用字典创建].
#不能使用index 字典中的key就是索引
s=pd.date_range(start='',end='') #生成一个日期时间索引
# start 指定开始时间; end 指定结束时间
s=pd.date_range(start='',periods=4)
# # periods 数据的个数
s=pd.date_range(start='',periods=6,freq='2D')
#freq:日期偏移量,取值为string或DateOffset,默认为'D'
s=pd.date_range(start='',end='',freq='3D',name='dt')
# 对象的名称
s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s')
# 偏移量是 秒
s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s',normalize=True)
#normalize:若参数为True表示将start、end参数值正则化到午夜时间戳 s=pd.date_range(start='',end='',freq='3D',closed='left')
#closed='left' 顾左不顾右 s=pd.date_range(start='',end='',freq='3D',closed='right')
#closed='right' 顾右不顾左 q=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD')) #创建数据表
#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表
#DataFrame可以设置列名columns与行名index,可以通过位置获取数据也可以通过列名和行名定位
#第一个参数是存放在数据表里的数据 可以是:numpy的矩阵对象、字典、列表
#index就是设置行名 columns设置列明 可以省略
#后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配 s=pd.date_range(start='',end='',freq='3D')
q=pd.DataFrame(np.random.randn(4,4),index=s,columns=list('ABCD')) #创建数据表
# s 是date_range日期时间索引对象 dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'性别':['男','女','女','男']}
q=pd.DataFrame(dic1) #用字典创建数据表
#每个key的value代表一列,而key是这一列的列名 s=q.dtypes #返回各列的数据类型 q=pd.DataFrame(np.random.randn(6,6))
s=q.head(3) #返回数据表前n行数据
#参数 指定行数 默认5 s=q.tail(3) #返回数据表后n行数据
q=pd.DataFrame(np.random.randn(4,4),index=list('abcd'),columns=list('ABCD'))
s=q.index #返回数据表的行名
s=q.columns #返回数据表的列名
s=q.values #返回数据表的数据
#返回值类型:numpy矩阵
s=q['B'].values #返回B列的数据
#返回值类型:numpy矩阵
s=q.loc['b'] #返回b行的列名和对应的数据
#只能根据行来查看 s=q.iloc[1] #返回指点索引行的列名和对应的数据
s=q.shape[0] #查看行数 4 <class 'int'>
s=q.shape[1] #查看列数 4 <class 'int'> s=q.T #行列转置
s=q.describe() #对数值型的列进行统计
#如果想对行进行描述性统计,转置后进行describe
s=q.sum() #对每列求和
s=q.sum(1) #对每行求和
#而一行中,有字符串有数值则只计算数值 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.apply(lambda x:x*2) #对每个元素进行计算
#如果元素是字符串,则会把字符串再重复一遍
#乘方运算如果有元素是字符串的话,会报错 q['E']=[99,34,12,3] #在后面添加一列
#E 添加的列名
q.insert(1,'F',[88,888,8,888]) #参数一列
#参数1 插入列的索引 其他的列顺延
# 参数2 列名 df6=pd.DataFrame(['my','name','is','a'],index=list('abch'),columns=list('G'))
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],index=list('abcd'),columns=list('ABCD'))
s=df2.join(df6) #把df6合并到df2
#根据行名 列名 来合并
#两个表有列名相同时就会报错
#s的行是以df2的行index为基准的,在df2相应行不存在数据时,就NaN=空 来填充 df8=df2.join(df6,how='inner') #把df6合并到df2
#how='inner' 交集:只返回两个数据表相同行名的行 df9=df2.join(df6,how='outer') #把df6合并到df2
#'outer'表示并集 :返回两个表的所有行 #如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe
df10=pd.DataFrame([1,2,3,4],index=list('abcd'),columns=['A'])
df11=pd.DataFrame([10,20,30,40],index=list('abcd'),columns=['B'])
df12=pd.DataFrame([100,200,300,400],index=list('abcd'),columns=['C'])
list1=[df10, df11, df12]
df13=pd.concat(list1) #合并多个数据表
#参数 是 数据表的列表
#df13 的列是所有数据表不同列名的总和
#df13 的行是所有数据表的总行数 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.sort_index(axis=0,ascending=False)#排序.根据列名或行名
#axis=1 对列名排序;axis=0 对行名排序
#ascending=False 降序;ascending=True 升序
s=q.sort_values(by='b',ascending= False,axis=1) #排序。根据数据
#by 根据哪一行或哪一列
#ascending=False 降序;ascending=True 升序
#axis=1 根据某行数据; axis=0 根据某列数据 s=q['A'] #返回某列数据
s=q[['B','C']] #返回某n列的数据
s=q.A #返回某列数据
s=q[1:3] #返回1到3行的数据。骨头不顾尾
s=q['b':'c'] #返回b行到c行的数据。包括c行
s=q.loc['b'] #返回b行数据
s=q.loc[:,['B','C']] #返回B列、C列所有行的数据
s=q.loc['c',['B','C']] #返回c行的B列、C列数据
s=q.iloc[2] #返回某行数据
s=q.iloc[2,2] #返回某行某列的数据
s=q.iloc[1:3,1:3] #返回第一行到第三行的第一列到第三列数据
s=q.iloc[[1,3],1:3] #返回第一行和第三行的第一列到第三列数据
s=q.ix[0:3,['A','C']] #返回 0:3行,A列和C列 【混合筛选】
s=q.ix[['a','c'],0:3] #返回 a行c行,0:3列
s=q[q.A>8] #筛选出A列大于8的所有数据 e=[40,200]
s=q[q['B'].isin(e)] #筛选出所有B列的值在e=[40,200]这个范围内的记录 #q.iloc[2,2]=77 #修改某行某列的值
#q.loc['c','B']=54 #修改某行某列的值
q[q.B>20]=0 #B列>20的行数据都改成0 print(q)
print(s)
import pandas as pd
import numpy as np x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD')) #q[q.B>20]=0 #B列>20的行数据都改成0
q.A[q.B>20]=0 #B列>20的A列行数据都改成0 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4],[35,36,37,38],[101,102,103,104]])
q=pd.DataFrame(x,index=list('abcdef'),columns=list('ABCD'))
q.iloc[2,2]=np.NaN
q.iloc[4,0]=np.NaN
#s=q.dropna(axis=0,how='any') #删除存在NaN时的数据
#axis=0 删除存在NaN所在行 ;axis=1 删除存在NaN所在列
#how='any' 存在一个NaN时就删除;how='all' 都是NaN时才删除 #s=q.fillna(value=0) #把NaN都改成0
#s=q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30 #q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30
#inplace=True 不创建副本,在原数据表中修改 # s=q.fillna(method='ffill')
# #method='ffill' 或者 method='pad' 用前一个非缺失值去填充NaN
#
# s=q.fillna(method='backfill') #用下一个非缺失值填充NaN
# s=q.isnull() #判断各个数据是否缺失值NaN q.iloc[3,0]=np.NaN
q.iloc[3,2]=np.NaN
q.iloc[1,2]=np.NaN
q.iloc[2,1]=np.NaN
q.iloc[2,3]=np.NaN
q.iloc[3,1]=np.NaN
s=q.fillna(method='backfill',limit=1,axis=1)
#limit=1 限制每列或每行连续NaN的修改次数
#axis=1 limit按行方向计算;axis=0 limit按列方向计算 s=q.isnull() #判断每个元素是否为缺省值NaN
e=np.any(s) == True #s数据表中只要有一个数据是True就返回True
e=np.all(s) == True #s数据表中所有数据都是True就返回True print(q)
print(s)
print(e)
import pandas as pd
import numpy as np # q=pd.read_csv(r'D:/ss/成绩1.csv') #读取CSV(逗号分割)文件到数据表
# q.to_pickle(r'D:/ss/成绩1.pickle') #把数据表存储为pickle文件
q=pd.DataFrame([[4,3,1,2],[20,40,30,10],[100,300,400,200]],columns=list('ABCD')) #创建数据表
q1=pd.DataFrame([[45,35,15,25],[205,405,305,105],[1005,3005,4005,2005]],columns=list('ABCD'))
q2=pd.DataFrame([[41,31,11,21],[201,401,301,101],[1001,3001,4001,2001]],columns=list('ABCD'))
q3=pd.DataFrame([[44,34,14,24],[204,404,304,104],[1004,3004,4004,2004]],index=[1,2,3],columns=list('ABCE'))
# s=pd.concat([q,q1,q2],axis=0,ignore_index=True) #数据表合并
#axis=0 纵向合并
#ignore_index=True 新数据表的索引重新排列 # s=pd.concat([q,q3],axis=0,ignore_index=True,join='inner') #数据表合并
#join='outer' 各表中不同的列名或行名 都合并
#join='inner' 只取各表相同的列名或行名 # s=pd.concat([q,q3],axis=1,ignore_index=True,join_axes=[q.index]) #数据表合并
#join_axes=[q.index] 横向合并时只取q的行 #s=pd.concat([q,q3],axis=0,ignore_index=True,join_axes=[q.columns]) #数据表合并
#join_axes=[q.columns] 纵向合并时只取q的列 s=q.append(q1,ignore_index=True) #在q表后面追加q1表
#不修改q1表 left=pd.DataFrame({'key':['k0','k1','k2','k3'],
'key1':['k0','kk1','k2','kk3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right=pd.DataFrame({'key':['k0','k1','k2','k3'],
'key1':['k0','kk6','k2','kk7'],
'B':['BB0','BB1','BB2','BB3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']
}) #s=pd.merge(left,right,on=['key','key1'],how='right') #合并数据表,多个连接键合并
#两个数据表的行数要相等
#on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次
#非连接键都会出现,有同名的会自动改名
#多个连接键合并:how='inner' 只会合并连接键相同的行,默认;
#how='outer' 都合并进来
#how='right' 只合并右对象的连接键
#how='left' 只合并左对象的连接键
#indicator=True 显示出此行在哪个表格中出现 s=pd.merge(left,right,on='key',right_index=True) #合并数据表 print(s)
pandas数据表的更多相关文章
- pandas 数据表中的字符与日期数据的处理
前面我们有学习过有关字符串的处理和正在表达式,但那都是基于单个字符串或字符串列表的操作.下面将学习如何基于数据框操作字符型变量. 同时介绍一下如何从日期型变量中取出年份,月份,星期几等,如何计算两个日 ...
- 使用Pandas将多个数据表合一
使用Pandas将多个数据表合一 将多张数据表合为一张表,便于统计分析,进行这一操作的前提为这多张数据表互相之间有关联信息,或者有相同的列. import pandas as pd unames = ...
- 小白学 Python 数据分析(13):Pandas (十二)数据表拼接
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- pandas:字段值插入数据表第一行的解决办法
1. 问题描述 在对课程表进行数据抽取时,由于课表结构的原因,需要在原始表字段名作为第一行数据,并对原始字段名进行替换. 原始数据如下所示: 2. 解决办法 经思考,此问题可抽象为:在不影响原始数据的 ...
- Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容 ...
- 【Python 数据分析】pandas数据导入
导入CSV文件数据 环境 C:\Users\Thinkpad\Desktop\Data\信息表.csv 语法 pd.read_csv(filename):从CSV文件导入数据 实现代码 import ...
- Pandas:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- Pandas 数据筛选,去重结合group by
Pandas 数据筛选,去重结合group by 需求 今小伙伴有一个Excel表, 是部门里的小伙9月份打卡记录, 关键字段如下: 姓名, 工号, 日期, 打卡方式, 时间, 详细位置, IP地址. ...
随机推荐
- error eslint@5.12.0: The engine "node" is incompatible with this module.
初始化 react项目时报错: error eslint@5.12.0: The engine "node" is incompatible with this module. E ...
- resharper license server
2018-5-14更新 http://jetbrains-a.pw good 2018-4-17 更新 http://jetbrains.tools bad 144.202.4.96 good 201 ...
- C# 语言习惯
目录 一.使用属性而不是可访问的数据成员 二.使用运行时常量(readonly)而不是编译时常量(const) 三.推荐使用 is 或 as 操作符而不是强制类型转换 四.使用 Conditional ...
- Django-website 程序案例系列-15 singnal分析
在django框架中singnal的应用相当于在你执行某些重要函数语句时在这条语句的前后放置两个预留的钩子,这两个钩子就是singnal,这个钩子也可以理解成两个触发器,当出现执行语句前后是触发执行某 ...
- BZOJ3510 首都(LCT)
即动态维护树的重心.考虑合并后的新重心一定在两棵树的重心的连线上.于是对每个点维护其子树大小,合并时在这条链的splay上二分即可.至于如何维护子树大小,见https://blog.csdn.net/ ...
- spring boot 系列之一:spring boot 入门
最近在学习spring boot,感觉确实很好用,开发环境搭建和部署确实省去了很多不必须要的重复劳动. 接下来就让我们一起来复习下. 一.什么是spring boot ? spring boot是干嘛 ...
- MT【213】二次曲线系方程
(2013北大夏令营)函数$y=x^2+ax+b$与坐标轴交于三个不同的点$A,B,C$,已知$\Delta ABC$的外心$P$在$y=x$上,求$a+b$的值. 解:由二次曲线系知识知三角形的外接 ...
- 【BZOJ4000】【LOJ2104】【TJOI2015】棋盘 (状压dp + 矩阵快速幂)
Description 有一个\(~n~\)行\(~m~\)列的棋盘,棋盘上可以放很多棋子,每个棋子的攻击范围有\(~3~\)行\(~p~\)列.用一个\(~3 \times p~\)的矩阵给出了 ...
- [luogu1373]小a和uim之大逃离【动态规划】
传送门:https://www.luogu.org/problemnew/show/P1373 定义状态是:\(f[i][j][h][0..1]\)表示在\([i,j]\)两个人相差为h,让某一个人走 ...
- [luogu3978][bzoj4001][TJOI2005]概率论【基尔霍夫矩阵+卡特兰数】
题目描述 为了提高智商,ZJY开始学习概率论.有一天,她想到了这样一个问题:对于一棵随机生成的n个结点的有根二叉树(所有互相不同构的形态等概率出现),它的叶子节点数的期望是多少呢? 判断两棵树是否同构 ...