爬格子问题(经典强化学习问题) Sarsa 与 Q-Learning 的区别
SARSA v.s. Q-learning
爬格子问题,是典型的经典强化学习问题。
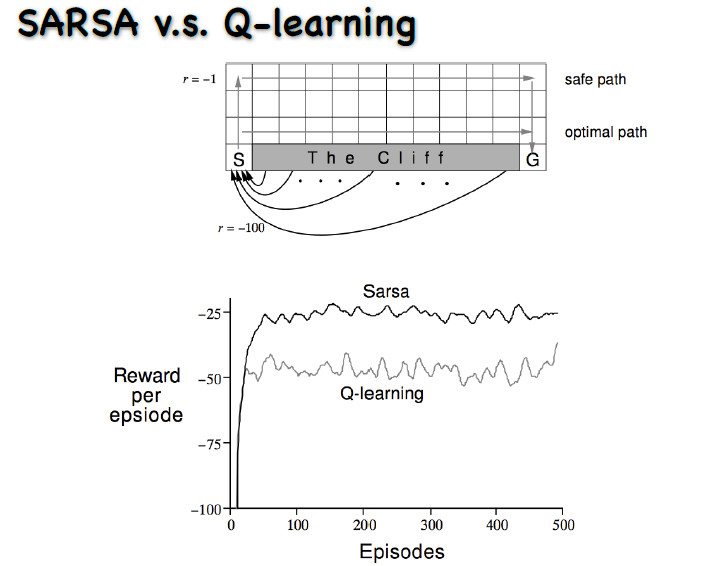
动作是上下左右的走,每走一步就会有一个-1的奖赏。从初始状态走到最终的状态,要走最短的路才能使奖赏最大。图中有一个悬崖,一旦走到悬崖奖赏会极小,而且还要再退回这个初始状态。
个人编写代码如下:
#encoding:UTF-8
#!/usr/bin/env python3 import math
import random
import matplotlib.pyplot as plt #动作的选择为上,下,左, 右
actions=["up", "down", "left", "right"] #坐标x的范围
x_scope=4 #坐标y的范围
y_scope=12 #greedy策略的探索因子(初始值)
epsilon_start=0.4
epsilon_final=0.01 #累积奖赏的折扣因子
discount_factor=0.99 #TD error的学习率
learning_rate=0.1 #动作值的字典
q_value=dict() #回合数
episodes=500 def calc_epsilon(t, epsilon_start=epsilon_start,
epsilon_final=epsilon_final, epsilon_decay=episodes):
if t<500:
epsilon = epsilon_final + (epsilon_start - epsilon_final) \
* math.exp(-1. * t / epsilon_decay)
else:
epsilon=0.0
return epsilon #动作值字典初始化
def q_value_init():
q_value.clear()
for i in range(x_scope):
for j in range(y_scope):
#状态坐标
state=(i, j)
for action in actions:
q_value[(state, action)]=0 #当前状态选择动作后的下一状态及其奖励
def state_reward_transition(state, action):
next_x, next_y=state
if action=="up":
next_x=state[0]-1
elif action=="down":
next_x=state[0]+1
elif action=="left":
next_y=state[1]-1
else:
next_y=state[1]+1 if next_x<0 or next_x>(x_scope-1) or next_y<0 or next_y>(y_scope-1):
next_state=state
reward=-1
return next_state, reward if next_x==0 and 0<next_y<(y_scope-1):
next_state=(0, 0)
reward=-100
return next_state, reward next_state=(next_x, next_y)
reward=-1
return next_state, reward #最大动作值选择法
def max_action(state):
q_value_list=[]
for action in actions:
q_value_list.append((q_value[(state, action)], action))
random.shuffle(q_value_list) action=max(q_value_list)[-1]
return action #greedy策略动作选择法
def greedy_action(state):
q_value_list=[]
for action in actions:
q_value_list.append((q_value[(state, action)], action))
random.shuffle(q_value_list) if random.random()>epsilon:
action=max(q_value_list)[-1]
else:
action=random.choice(q_value_list)[-1]
return action #sarsa策略
def sarsa(state):
#选择当前状态的动作
action=greedy_action(state)
next_state, reward=state_reward_transition(state, action) #选择下一状态的动作
next_action=greedy_action(next_state) #对当前动作值的估计
estimate=reward+discount_factor*q_value[(next_state, next_action)] #TD error
error=estimate-q_value[(state, action)] #学习到的新当前动作值
q_value[(state, action)]+=learning_rate*error
return next_state, reward def q_learning(state):
#选择当前状态的动作
action=greedy_action(state)
next_state, reward=state_reward_transition(state, action) #选择下一状态的动作
next_action=max_action(next_state) #对当前动作值的估计
estimate=reward+discount_factor*q_value[(next_state, next_action)]
#TD error
error=estimate-q_value[(state, action)]
#学习到的新当前动作值
q_value[(state, action)]+=learning_rate*error
return next_state, reward if __name__=="__main__":
reward_list_1=[]
q_value_init()
for episode in range(episodes+100):
reward_sum=0
state=(0, 0)
epsilon=calc_epsilon(episode)
while state!=(x_scope-1, y_scope-1):
state, reward=sarsa(state)
reward_sum+=reward
reward_list_1.append(reward_sum) for i in range(x_scope):
for j in range(y_scope):
print("-"*20)
for action in actions:
print( "("+str(i)+", "+str(j)+") : "+action+" "+str(q_value[((i, j), action)])) plt.subplot(211)
plt.plot(reward_list_1, label="sarsa")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("sarsa") reward_list_2=[]
q_value_init()
for episode in range(episodes+100):
reward_sum=0
state=(0, 0)
epsilon=calc_epsilon(episode)
while state!=(x_scope-1, y_scope-1):
state, reward=q_learning(state)
reward_sum+=reward
reward_list_2.append(reward_sum) for i in range(x_scope):
for j in range(y_scope):
print("-"*20)
for action in actions:
print( "("+str(i)+", "+str(j)+") : "+action+" "+str(q_value[((i, j), action)])) plt.subplot(212)
plt.plot(reward_list_2, label="q-learning")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("q-learning")
plt.show() plt.plot(reward_list_1, label="sarsa")
plt.plot(reward_list_2, label="q-learning")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("SARSA & Q-LEARNING")
plt.show()

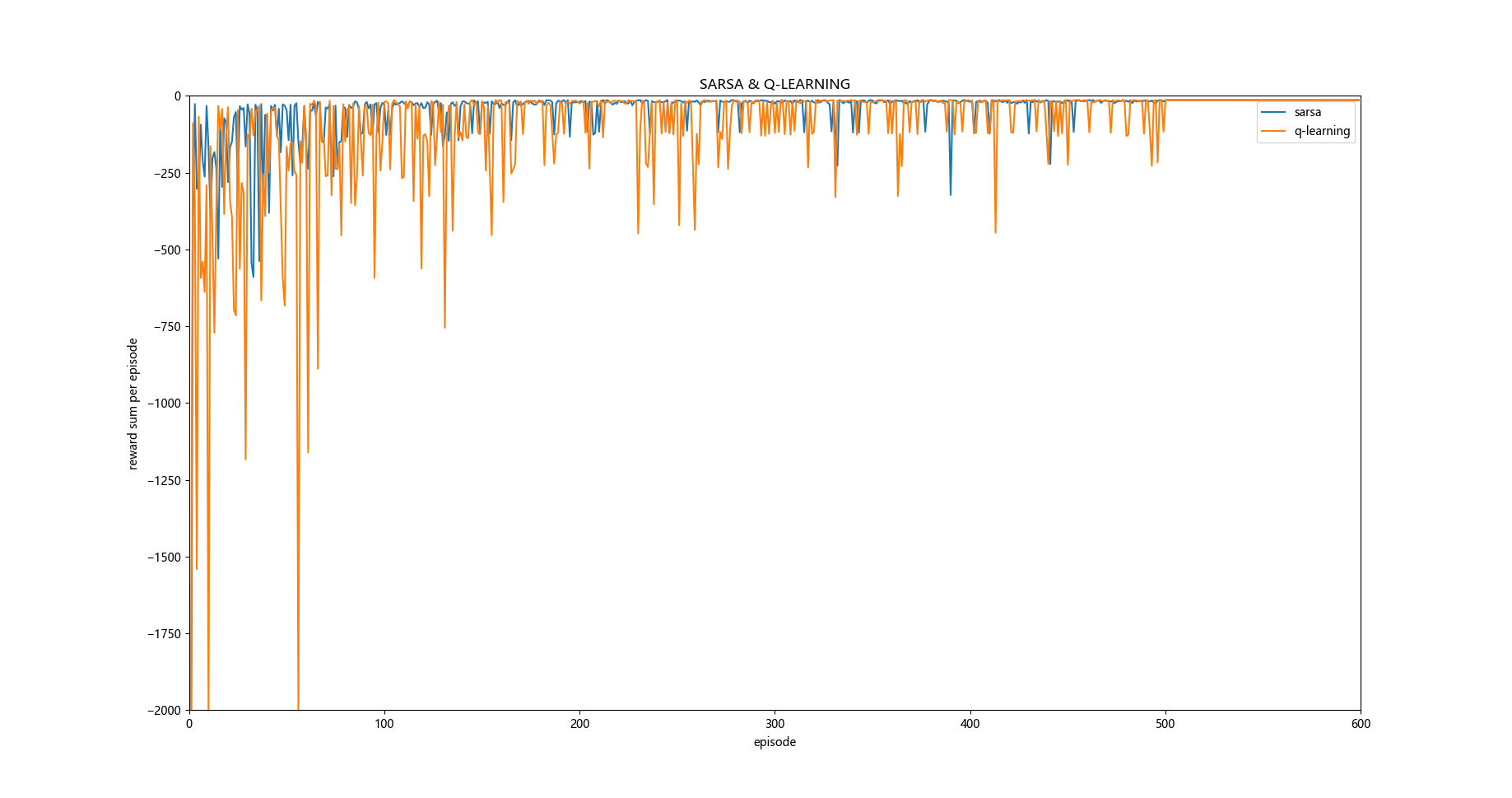
从自我编写的代码运行的程序效果和原题目给出的效果图来看还是有些差距的,个人感觉这个应该是超参数设置的问题。
如:学习率, greedy策略的epsilon设置等。
不过有一点是相似的,那就是q-learning学习的过程中奖励值一般要小于sarsa学习方法。
对于为什么在这个问题中 q-learning的学习过程中奖励值的累积和要普遍小于sarsa方法,个人观点是按照原题目给出的效果图分析是因为sarsa对策略的探索更加高效, 更有可能走optimal path, 而q-learning 对下一状态q值的探索是直接用最大值来估计的,所以更有可能走safe path路线。
=================================================================
如果这个问题中没有悬崖的话,那么运行结果如何呢?
代码如下:
#encoding:UTF-8
#!/usr/bin/env python3 import math
import random
import matplotlib.pyplot as plt #动作的选择为上,下,左, 右
actions=["up", "down", "left", "right"] #坐标x的范围
x_scope=4 #坐标y的范围
y_scope=12 #greedy策略的探索因子(初始值)
epsilon_start=0.4
epsilon_final=0.01 #累积奖赏的折扣因子
discount_factor=0.99 #TD error的学习率
learning_rate=0.1 #动作值的字典
q_value=dict() #回合数
episodes=500 def calc_epsilon(t, epsilon_start=epsilon_start,
epsilon_final=epsilon_final, epsilon_decay=episodes):
if t<500:
epsilon = epsilon_final + (epsilon_start - epsilon_final) \
* math.exp(-1. * t / epsilon_decay)
else:
epsilon=0.0
return epsilon #动作值字典初始化
def q_value_init():
q_value.clear()
for i in range(x_scope):
for j in range(y_scope):
#状态坐标
state=(i, j)
for action in actions:
q_value[(state, action)]=0 #当前状态选择动作后的下一状态及其奖励
def state_reward_transition(state, action):
next_x, next_y=state
if action=="up":
next_x=state[0]-1
elif action=="down":
next_x=state[0]+1
elif action=="left":
next_y=state[1]-1
else:
next_y=state[1]+1 if next_x<0 or next_x>(x_scope-1) or next_y<0 or next_y>(y_scope-1):
next_state=state
reward=-1
return next_state, reward """
if next_x==0 and 0<next_y<(y_scope-1):
next_state=(0, 0)
reward=-100
return next_state, reward
""" next_state=(next_x, next_y)
reward=-1
return next_state, reward #最大动作值选择法
def max_action(state):
q_value_list=[]
for action in actions:
q_value_list.append((q_value[(state, action)], action))
random.shuffle(q_value_list) action=max(q_value_list)[-1]
return action #greedy策略动作选择法
def greedy_action(state):
q_value_list=[]
for action in actions:
q_value_list.append((q_value[(state, action)], action))
random.shuffle(q_value_list) if random.random()>epsilon:
action=max(q_value_list)[-1]
else:
action=random.choice(q_value_list)[-1]
return action #sarsa策略
def sarsa(state):
#选择当前状态的动作
action=greedy_action(state)
next_state, reward=state_reward_transition(state, action) #选择下一状态的动作
next_action=greedy_action(next_state) #对当前动作值的估计
estimate=reward+discount_factor*q_value[(next_state, next_action)] #TD error
error=estimate-q_value[(state, action)] #学习到的新当前动作值
q_value[(state, action)]+=learning_rate*error
return next_state, reward def q_learning(state):
#选择当前状态的动作
action=greedy_action(state)
next_state, reward=state_reward_transition(state, action) #选择下一状态的动作
next_action=max_action(next_state) #对当前动作值的估计
estimate=reward+discount_factor*q_value[(next_state, next_action)]
#TD error
error=estimate-q_value[(state, action)]
#学习到的新当前动作值
q_value[(state, action)]+=learning_rate*error
return next_state, reward if __name__=="__main__":
reward_list_1=[]
q_value_init()
for episode in range(episodes+100):
reward_sum=0
state=(0, 0)
epsilon=calc_epsilon(episode)
while state!=(x_scope-1, y_scope-1):
state, reward=sarsa(state)
reward_sum+=reward
reward_list_1.append(reward_sum) for i in range(x_scope):
for j in range(y_scope):
print("-"*20)
for action in actions:
print( "("+str(i)+", "+str(j)+") : "+action+" "+str(q_value[((i, j), action)])) plt.subplot(211)
plt.plot(reward_list_1, label="sarsa")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("sarsa") reward_list_2=[]
q_value_init()
for episode in range(episodes+100):
reward_sum=0
state=(0, 0)
epsilon=calc_epsilon(episode)
while state!=(x_scope-1, y_scope-1):
state, reward=q_learning(state)
reward_sum+=reward
reward_list_2.append(reward_sum) for i in range(x_scope):
for j in range(y_scope):
print("-"*20)
for action in actions:
print( "("+str(i)+", "+str(j)+") : "+action+" "+str(q_value[((i, j), action)])) plt.subplot(212)
plt.plot(reward_list_2, label="q-learning")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("q-learning")
plt.show() plt.plot(reward_list_1, label="sarsa")
plt.plot(reward_list_2, label="q-learning")
plt.legend(loc = 0)
plt.xlabel('episode')
plt.ylabel('reward sum per episode')
plt.xlim(0,600)
plt.ylim(-2000, 0)
plt.title("SARSA & Q-LEARNING")
plt.show()
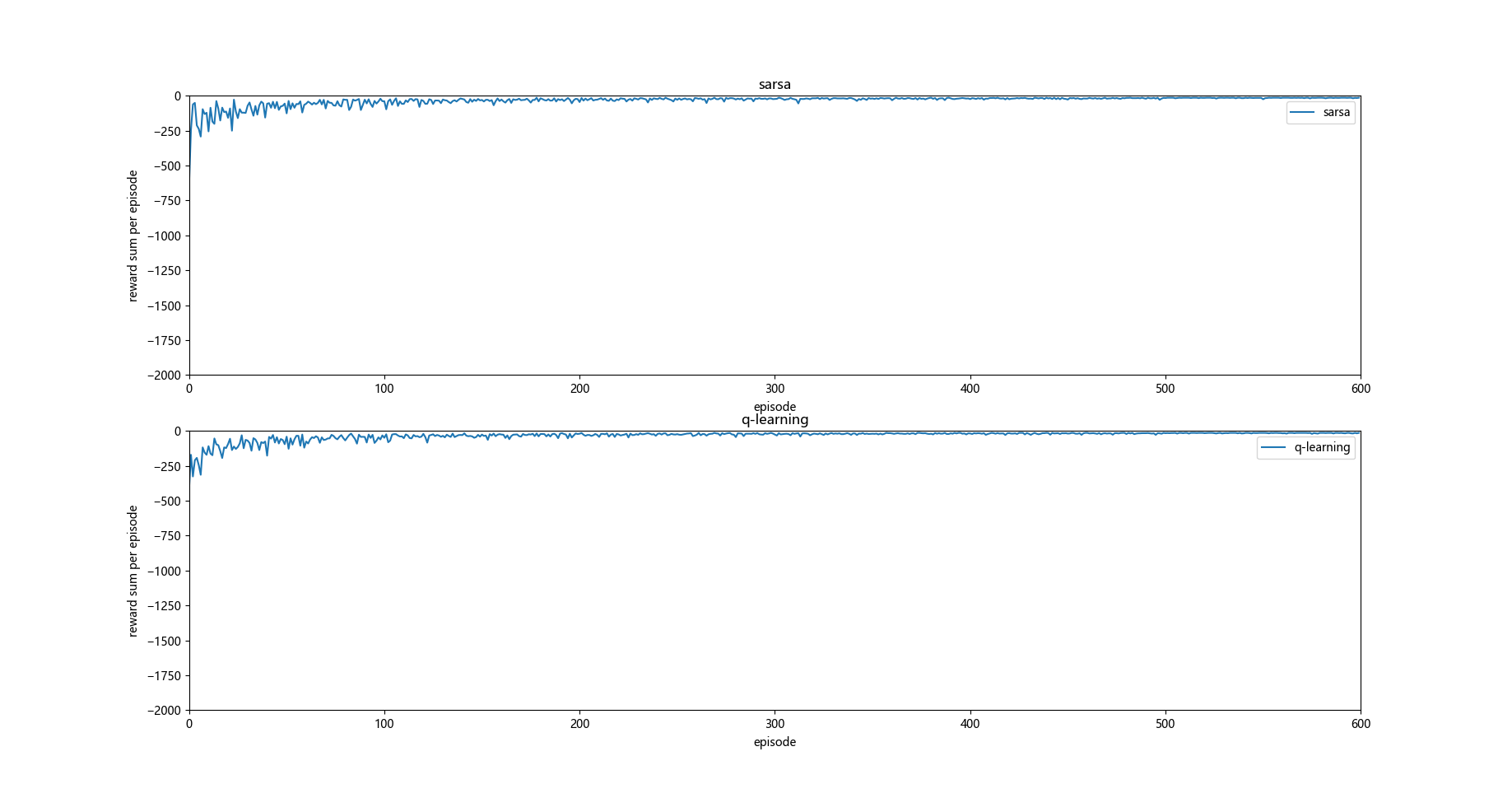

这时候发现如果没有悬崖的话 q-learning 和 sarsa 运行的效果大致相同。
个人观点:
如果按照原题目给出的效果图分析 q_learning 学习对惩罚项敏感,探索效率低于sarsa, 因为q_learning中对下一状态的q值采用max方法来估计,所以在算法运行过程中会尽量远离初步判断不好的选择,即选择safe path, 某种角度上来说也是其探索效率小于sarsa的一个结果。

按照原题目效果图分析并结合上图所示, S0状态是初始状态,在q_learning 算法初始时容易得出S1状态时right动作的q值较低的结论,原因是S2状态时up操作的q值较低,S3状态时q值较高,所以q_learning更倾向于在S1状态选择down操作。
但是依照个人所做实验的效果图分析,则和上面的分析不太一样:
那就是 q_learning更偏向于探索optimal path, 而sarsa更倾向于探索safe path, 因为正是因为q_learning 探索optimal path才会有多次掉入悬崖的情况,而sarsa掉入悬崖次数较少则说明其更倾向于探索safe path 。
爬格子问题(经典强化学习问题) Sarsa 与 Q-Learning 的区别的更多相关文章
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习之Sarsa (时间差分学习)
上篇文章讲到Q-learning, Sarsa与Q-learning的在决策上是完全相同的,不同之处在于学习的方式上 这次我们用openai gym的Taxi来做演示 Taxi是一个出租车的游戏,把顾 ...
- 深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
RL的方案 两个主要对象:Agent和Environment Agent观察Environment,做出Action,这个Action会对Environment造成一定影响和改变,继而Agent会从新 ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 强化学习(Reinfment Learning) 简介
本文内容来自以下两个链接: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ https: ...
随机推荐
- Echarts 简单报表系列二:折线图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Qt中漂亮的几款QSS
/* === Shared === */QStackedWidget, QLabel, QPushButton, QRadioButton, QCheckBox, QGroupBox, QStatus ...
- js正则表达式 replace替换url的参数
/* 定义替换对象键值 */var setReferArgs = function(){ var referArgs = new Object(); referArgs['#userID\ ...
- Windows设置.txt文件默认打开程序
一.配置某个程序默认打开哪些类型的文件(以firefox为例) 依次打开”控制面板\程序\默认程序“,点击”设置默认程序“ 在右侧列表找到firefox,选中 以firefox为例,”将此程序设置为默 ...
- Qt样式表都有哪些属性可以设置
我们可以在Qt助手中输入Qt Style Sheets Reference然后选择List of Pseudo-States 项查看Qt控件支持的所有状态. 附几个参考学习的博客: https://b ...
- python+ajaxFileUpload 无刷新上传文件
需要准备文件 http://pan.baidu.com/s/1bp4N3nL qqi0 html <script src="{% static 'js/jquery.js' %}& ...
- facebook视频上传python 返回错误code:100,'type':OAuthException
首先重新获取访问口令token: https://developers.facebook.com/tools/debug/accesstoken/?q=EAAYDuzyd3eYBAK9lZCErZBl ...
- Win10系列:VC++绘制几何图形3
在绘制三角形之前,首先需要创建一个三角形,打开D2DBasicAnimation.h头文件,在D2DBasicAnimation类中添加如下的代码: private: //声明成员变量obje ...
- Android Studio2.1版本后使用虚拟机碰见的问题总结以及其他问题
一.androidstudio的sdk配置问题 如果点击Start a new Android Studio project是没有反应的,并且在Configure下面的SDK Manager是灰色的, ...
- Uva 12124 Uva Live 3971 - Assemble 二分, 判断器, g++不用map.size() 难度:0
题目 https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_pr ...