不同组的id列表的汇总对比
需求:
三个不同的dfs中存在不同的多个节点id,现在需要求出不同的dfs之间的节点对应关系,比如,哪些节点在某一个dfs,但是不在另一个dfs中
思路:
一、 如果是单纯计算dfs中节点数量,则可以使用scala,代码如下:
1 准备原始数据
将原始数据存放在文本文件dfs_id中(本文通过subline),格式如下:
2415,2416,2417,2418,2419,2421,2422,2423,2424,2425,2426,2427,2428,2429,2430,2431,2432,2433,2434,2435,2436,2437,2438,2439,2440,2441,2442,2443,2444,2445,2446,2447,2448,2449,2450,2541,2542,2544,2724,3124,3126,2605,2606,3133,3194,3272,3271,3273,3274,3302,3313,3314,3652,3654,3657,3944
2 计算代码
1. 在【spark】/bin目录下启动spark:
spark-shell --master=local 2. 读取源数据文件,创建rdd
scala> var rdd = sc.textFile("/Users/wooluwalker/Desktop/dfs_id")
rdd: org.apache.spark.rdd.RDD[String] = /Users/wooluwalker/Desktop/dfs_id MapPartitionsRDD[2] at textFile at <console>:24
3. 计算id个数
scala> rdd.flatMap(x=>x.split(',')).count()
res3: Long = 56
3 上述代码只用于个数的计算,不能用于不同dfs之间的id对比,为了是实现这个功能,推荐使用hive
二、 使用hive将不同dfs的id汇总到一张表中
1 创建表 tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split
结构相同,如下:
line string 2 上传对应的数据到不同的表中
load data local inpath '/Users/wooluwalker/Desktop/dfs_3_taskid' into table tb_dfsid_3_confluence_task_id_split; load data local inpath '/Users/wooluwalker/Desktop/dfs_137_taskid' into table tb_dfsid_137_confluence_task_id_split; 3 将tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split一横行的数据拆分成一纵列, 放到tb_dfsid_137_confluence_task_id_split_vertical,tb_dfsid_3_confluence_task_id_split_vertical: create table if not exists tb_dfsid_137_confluence_task_id_split_vertical
as
select * from (
select explode(split(line,",")) as dfsid_137 from tb_dfsid_137_confluence_task_id_split
) tmp; create table if not exists tb_dfsid_3_confluence_task_id_split_vertical
as
select * from (
select explode(split(line,",")) as dfsid_137 from tb_dfsid_3_confluence_task_id_split
) tmp; 4 创建表tb_dfsid_3_137_confluence_task_id_compare,汇总对比dfs_3和dfs_137下的节点 create table if not exists tb_dfsid_3_137_confluence_task_id_compare
select dfsid3, dfsid137
from
tb_dfsid_3_confluence_task_id_split_vertical id3
full outer join
tb_dfsid_137_confluence_task_id_split_vertical id137
on id3.dfsid3 = id137.dfsid137;
dfs_3 与dfs_137的节点对比如下(部分):
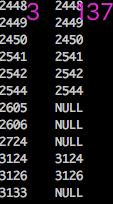
同样也可得到 dfs_3 与dfs_137 dfs_137之间的对比:
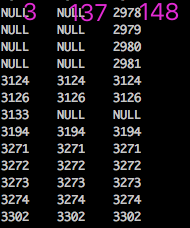
注:
- 子查询必须有select表的别名!!!!
- 子查询中必须指明字段的别名(as dfsid_137),否则据此创建出来的表 tb_dfsid_137_confluence_task_id_split_vertical 列名为col,不利于后续计算
如下为原始代码: 创建表 tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split
结构相同,如下:
line string 2 上传对应的数据到不同的表中
load data local inpath '/Users/wooluwalker/Desktop/dfs_3_taskid' into table tb_dfsid_3_confluence_task_id_split; load data local inpath '/Users/wooluwalker/Desktop/dfs_137_taskid' into table tb_dfsid_137_confluence_task_id_split; 3 将tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split一横行的数据拆分成一纵列,放到tb_dfsid_137_confluence_task_id_split_vertical,tb_dfsid_3_confluence_task_id_split_vertical create table if not exists tb_dfsid_137_confluence_task_id_split_vertical
as
select * from
(
select explode(split(line,",")) from tb_dfsid_137_confluence_task_id_split
) tmp; create table if not exists tb_dfsid_3_confluence_task_id_split_vertical
as
select * from
(
select explode(split(line,",")) from tb_dfsid_3_confluence_task_id_split
) tmp; 4 创建表tb_dfsid_3_137_confluence_task_id_compare,汇总对比dfs_3和dfs_137下的节点
create table if not exists tb_dfsid_3_137_confluence_task_id_compare
select dfsid3, dfsid137
from
tb_dfsid_3_confluence_task_id_split_vertical id3
full outer join
tb_dfsid_137_confluence_task_id_split_vertical id137
on id3.dfsid3 = id137.dfsid137; truncate table tb_dfsid_148_confluence_task_id_split; load data local inpath '/Users/wooluwalker/Desktop/dfs148_taskid' into table tb_dfsid_148_confluence_task_id_split; truncate table tb_dfsid_148_confluence_task_id_split_vertical; insert into tb_dfsid_148_confluence_task_id_split_vertical
select * from
(
select explode(split(line,",")) from tb_dfsid_148_confluence_task_id_split
) tmp; select count(1) from tb_dfsid_148_confluence_task_id_split_vertical; drop table tb_dfsid_3_137_148_confluence_task_id_compare; create table if not exists tb_dfsid_3_137_148_confluence_task_id_compare(dfsid3 string,dfsid137 string,dfsid148 string); insert into tb_dfsid_3_137_148_confluence_task_id_compare
select dfsid3, dfsid137,dfsid148
from
tb_dfsid_3_137_confluence_task_id_compare id3_137
full outer join
tb_dfsid_148_confluence_task_id_split_vertical id148
on id3_137.dfsid3 = id148.dfsid148; select * from tb_dfsid_3_137_148_confluence_task_id_compare;
--输出59个
select count(distinct dfsid148) from tb_dfsid_3_137_148_confluence_task_id_compare; select explode(split(line,",")) from tb_dfsid_148_confluence_task_id_split; select count(*) from (select explode(split(line,",")) from tb_dfsid_148_confluence_task_id_split) as tmp; select size(split(line,',')) from tb_dfsid_148_confluence_task_id_split; select size(split('1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8',',')); select size(split('2447,2445,3124,3944,2444,2442,2440,3271,3126,3652,3654,3302,3629,2415,2979,2439,2429,2980,2981,2433,2978,2427,2977,2438,2426,2969,2976,2431,2973,2430,2972,2425,2970,2542,2450,3657,2544,2424,2437,2423,2422,2419,2428,3314,2449,2418,2421,2448,3313,2417,3194,2416,2432,2446,2443,2441,3273,3274,3272',',')); select explode(split('2447,2445,3124,3944,2444,2442,2440,3271,3126,3652,3654,3302,3629,2415,2979,2439,2429,2980,2981,2433,2978,2427,2977,2438,2426,2969,2976,2431,2973,2430,2972,2425,2970,2542,2450,3657,2544,2424,2437,2423,2422,2419,2428,3314,2449,2418,2421,2448,3313,2417,3194,2416,2432,2446,2443,2441,3273,3274,3272',",")); --select 出来的“表”的列明为col
select explode(split('2447,2445,3124,3944,2444,2442,2440,3271,3126,3652,3654,3302,3629,2415,2979,2439,2429,2980,2981,2433,2978,2427,2977,2438,2426,2969,2976,2431,2973,2430,2972,2425,2970,2542,2450,3657,2544,2424,2437,2423,2422,2419,2428,3314,2449,2418,2421,2448,3313,2417,3194,2416,2432,2446,2443,2441,3273,3274,3272',",")) order by col; --查看148 task的个数:59个
select count(*) from (select explode(split('2447,2445,3124,3944,2444,2442,2440,3271,3126,3652,3654,3302,3629,2415,2979,2439,2429,2980,2981,2433,2978,2427,2977,2438,2426,2969,2976,2431,2973,2430,2972,2425,2970,2542,2450,3657,2544,2424,2437,2423,2422,2419,2428,3314,2449,2418,2421,2448,3313,2417,3194,2416,2432,2446,2443,2441,3273,3274,3272',",")))tmp; --输出 59 去重
select count(distinct col) from (select explode(split('2447,2445,3124,3944,2444,2442,2440,3271,3126,3652,3654,3302,3629,2415,2979,2439,2429,2980,2981,2433,2978,2427,2977,2438,2426,2969,2976,2431,2973,2430,2972,2425,2970,2542,2450,3657,2544,2424,2437,2423,2422,2419,2428,3314,2449,2418,2421,2448,3313,2417,3194,2416,2432,2446,2443,2441,3273,3274,3272',","))) tmp; --tb_dfsid_148_confluence_task_id_split_vertical 只有51个task
select count(1) from tb_dfsid_148_confluence_task_id_split_vertical;
不同组的id列表的汇总对比的更多相关文章
- python中字符串和列表只是汇总
字符串知识汇总 字符串是描述变量的重要信息,其中的应用也是很多,很重要的一点就是StringBuilder.今天我们会为大家介绍一下常用的StringBuilder 1 strip lstrip rs ...
- JS 获取某个容器控件中id包含制定字符串的控件id列表
//获取某容器控件中id包含某字符串的控件id列表 //参数:容器控件.要查找的控件的id关键字 function GetIdListBySubKey(container,subIdKey) { va ...
- 气象城市ID列表
气象城市ID列表 数据来源: http://cj.weather.com.cn/support/Detail.aspx?id=51837fba1b35fe0f8411b6df 记录了2574个地区,2 ...
- C#开发BIMFACE系列16 服务端API之获取模型数据1:查询满足条件的构件ID列表
系列目录 [已更新最新开发文章,点击查看详细] 源文件/模型转换完成之后,可以获取模型的具体数据.本篇介绍根据文件ID查询满足条件的构件ID列表. 请求地址:GET https://api.b ...
- 倒排列表压缩算法汇总——分区Elias-Fano编码貌似是最牛叉的啊!
来看看倒排索引压缩.压缩是拿CPU换IO的最重要手段之一,不论索引是放在硬盘还是内存中.索引压缩的算法有几十种,跟文本压缩不同,索引压缩算法不仅仅需要考虑压缩率,更要考虑压缩和解压性能,否则会解压太慢 ...
- HTTP访问的两种方式(HttpClient+HttpURLConnection)整合汇总对比(转)
在Android上http 操作类有两种,分别是HttpClient和HttpURLConnection,其中两个类的详细介绍可以问度娘. HttpClient: HttpClient是Apache ...
- sphinx 源码阅读之分词,压缩索引,倒排——单词对应的文档ID列表本质和lucene无异 也是外部排序再压缩 解压的时候需要全部扫描doc_ids列表偏移量相加获得最终的文档ID
转自:http://github.tiankonguse.com/blog/2014/12/03/sphinx-token-inverted-sort.html 外部排序 现在我们的背景是有16个已经 ...
- jQuery ID与Class性能对比之一
最近一直在做网站的优化方面的工作,在实际优化的过程中逐渐发现yahoo的34条只能作为一个大的方向,除此之外还有很多地方值得前端工程师关注的.结合最近的优化体会及实地测试,现发出来一部分供大家批评指正 ...
- [python01] python列表,元组对比Erlang的区别总结
数据结构是通过某种方式组织在一起的数据元素的集合,这些数据元素可以是数字,字符,甚至可以是其他的数据结构. python最基本的数据结构是sequence(序列):6种内建的序列:列表,元组,字符串, ...
随机推荐
- spring为什么推荐使用构造器注入
一.前言 项目中遇到一个问题:项目启动完成前,在A类中注入B类,并调用B类的某个方法. 那么调用B类的这个方法写在哪里呢,我选择写到构造器里,但是构造器先于Spring注入执行,那么执行构造器时, ...
- JS 判断两个时间的大小(可自由选择精确度:天,小时,分钟,秒)
//可自由选择精确度 如:签到时间:2018-11-07 11:00:00 签退时间:2018-11-07 10:59:59 //判断时间先后 //统一格式 var a = $("#fdtm ...
- sass学习笔记(一)接上个 持续学习中..(还发现个讲解的bug) sass至少我现在学的版本支持局部变量了
6.全局变量 sass暂时没有局部变量 局部定义变量会覆盖全局变量 新出!global 不过要sass 3.4版本以后 (这句呢,,我觉得是错的 开始写的时候没测试 现在发现我觉得他是有 ...
- MyBatis-day2
Properties 属性: 如果属性在不只一个地方进行了配置,那么 MyBatis 将按照下面的顺序来加载: 在 properties 元素体内指定的属性首先被读取. 然后根据 properties ...
- Ubuntu下安装git
1 安装 官网上提供的命令是: $ sudo add-apt-repository ppa:git-core/ppa 中间暂停时,按回车键Enter继续安装. $ sudo apt-get updat ...
- lvs用户空间命令ipvsadm
ipvs工作在内核空间,而ipvsadm工作在用户空间,是负责管理集群服务编写规则的命令行工具 ipvsadm需要手动安装. $ yum -y install ipvsadm ipvsadm管理命令 ...
- python模块之_正则 re_configparser_logging_hashlib
正则表达式的内容放在最下面了 configparser 模块: #!/usr/bin/env python # coding:utf-8 import configparser # 专门用于操作配置文 ...
- linux实时时钟相关函数
time 功能:获取1970年1月1日00:00:00到现在的秒数 原型:time_t time(time_t *t); 参数: t:获取到的秒数 返回:获取到的秒数 说明:在time.h中定义了ti ...
- PHP协程入门详解
概念 咱们知道多进程和多线程是实现并发的有效方式.但多进程的上下文切换资源开销太大:多线程开销相比要小很多,也是现在主流的做法,但其的控制权在内核,从而使用户(程序员)失去了对代码的控制,而且线程的上 ...
- vue-router 学习
Vue.js的一大特色就是构建单页面应用十分方便,既然要方便构建单页面应用那么自然少不了路由,vue-router就是vue官方提供的一个路由框架.总体来说,vue-router设计得简单好用,下面就 ...