Hadoop Yarn框架详细解析
在说Hadoop Yarn之前,我们先来看看Yarn是怎样出现的。在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTracker等工作。这自然就会产生一个问题,那就是JobTracker负载太多,有点“忙不过来”。于是Hadoop在1.0到2.0的升级过程中,便将JobTracker的资源调度工作独立了出来,而这一改动,直接让Hadoop成为大数据中最稳固的那一块基石。,而这个独立出来的资源管理框架,就是Hadoop Yarn框架 。
一. Hadoop Yarn是什么
在详细介绍Yarn之前,我们先简单聊聊Yarn,Yarn的全称是Yet Another Resource Negotiator,意思是“另一种资源调度器”,这种命名和“有间客栈”这种可谓是异曲同工之妙。这里多说一句,以前Java有一个项目编译工具,叫做Ant,他的命名也是类似的,叫做“Another Neat Tool”的缩写,翻译过来是”另一种整理工具“。
既然都叫做资源调度器了,那么自然,它的功能也是负责资源管理和调度的,接下来,我们就深入到Yarn框架内部一探究竟吧。
二. Hadoop Yarn主要架构
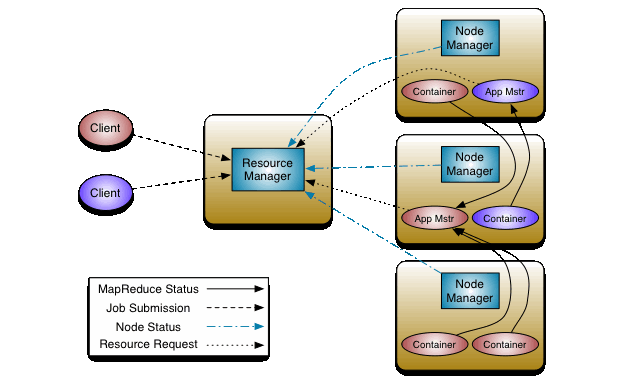
这张图可以说是Yarn的全景图,我们主要围绕上面这张图展开,介绍图中的每一个细节部分。首先,我们会介绍里面的Container的概念以及相关知识内容,然后会介绍图中一个个组件,最后看看提交一个程序的流程。
2.1 Container
容器(Container)这个东西是Yarn对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn对资源的管理也是用到了这种思想。
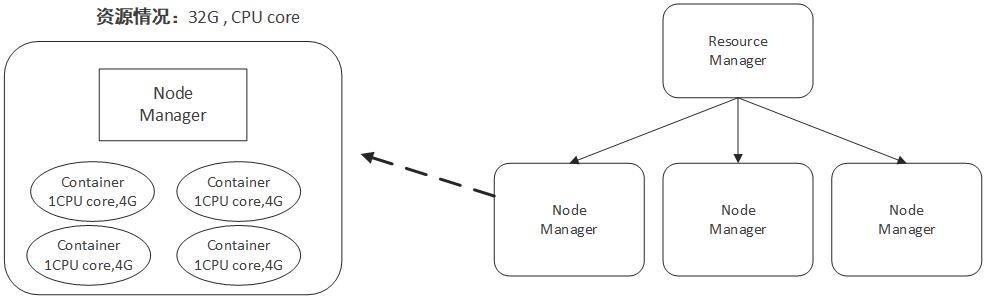
如上所示,Yarn将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由NodeManager启动和管理,并被它所监控。
- 容器被ResourceManager进行调度。
其中NodeManager和ResourceManager这两个组件会在下面讲到。
2.2 Yarn的三个主要组件
再看最上面的图,我们能直观发现的两个主要的组件是ResourceManager和NodeManager,但其实还有一个ApplicationMaster在图中没有直观显示(其实就是图中的App Mstr,图里用了简写)。三个组件构成了Yarn的全景,这三个组件的主要工作是什么,Yarn 框架又是如何让他们相互配合的呢,我们分别来看这三个组件。
ResourceManager
我们先来说说上图中最中央的那个ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,在运行过程中,整个系统有且只有一个RM,系统的资源正是由RM来负责调度管理的。RM包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager),我们分别来看看它们的主要工作。
定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当Client提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理Client用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
OK,明白了资源管理器ResourceManager,那么应用程序如何申请资源,用完如何释放?这就是ApplicationMaster的责任了。
ApplicationMaster
每当Client(用户)提交一个Application(应用程序)时候,就会新建一个ApplicationMaster。由这个ApplicationMaster去与ResourceManager申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
那么最后,资源有了,应用程序也有了,那么该怎么管理应用程序在每个节点上的计算呢?别急,我们还有一个NodeManager。
NodeManager
相比起上面两个组件的掌控全局,NodeManager就显得比较细微了。NodeManager是ResourceManager在每台机器的上代理,主要工作是负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),并且它会定期向ResourceManager/Scheduler提供这些资源使用报告,再由ResourceManager决定对节点的资源进行何种操作(分配,回收等)。
三. 提交一个Application到Yarn的流程
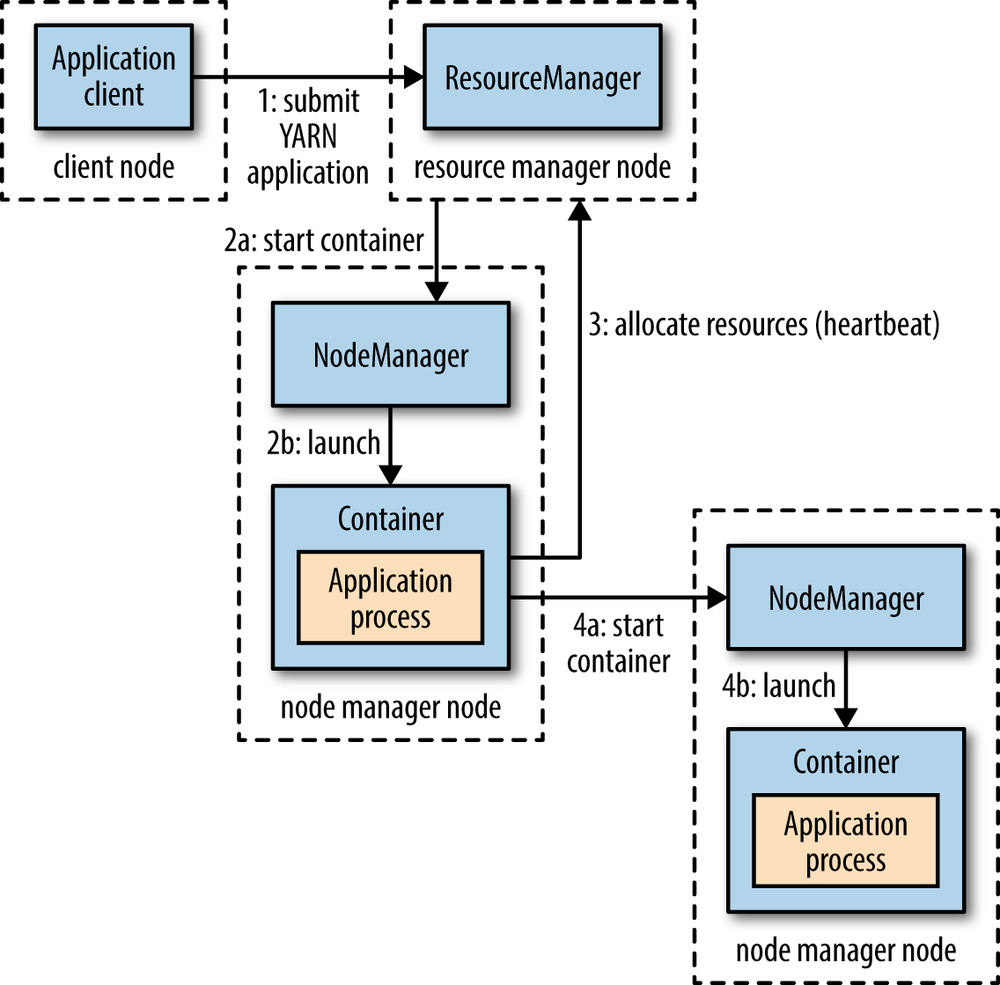
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
Client向Yarn提交Application,这里我们假设是一个MapReduce作业。
ResourceManager向NodeManager通信,为该Application分配第一个容器。并在这个容器中运行这个应用程序对应的ApplicationMaster。
ApplicationMaster启动以后,对作业(也就是Application)进行拆分,拆分task出来,这些task可以运行在一个或多个容器中。然后向ResourceManager申请要运行程序的容器,并定时向ResourceManager发送心跳。
申请到容器后,ApplicationMaster会去和容器对应的NodeManager通信,而后将作业分发到对应的NodeManager中的容器去运行,这里会将拆分后的MapReduce进行分发,对应容器中运行的可能是Map任务,也可能是Reduce任务。
容器中运行的任务会向ApplicationMaster发送心跳,汇报自身情况。当程序运行完成后,ApplicationMaster再向ResourceManager注销并释放容器资源。
以上就是一个作业的大体运行流程。
为什么会有Hadoop Yarn框架的出现?
上面说了这么多,最后我们来聊聊为什么会有Yarn吧。
直接的原因呢,就是因为Hadoop1.0中架构的缺陷,在MapReduce中,jobTracker担负起了太多的责任了,接收任务是它,资源调度是它,监控TaskTracker运行情况还是它。这样实现的好处是比较简单,但相对的,就容易出现一些问题,比如常见的单点故障问题。
要解决这些问题,只能将jobTracker进行拆分,将其中部分功能拆解出来。彼时业内已经有了一部分的资源管理框架,比如mesos,于是照着这个思路,就开发出了Yarn。这里多说个冷知识,其实Spark早期是为了推广mesos而产生的,这也是它名字的由来,不过后来反正是Spark火起来了。。。
闲话不多说,其实Hadoop能有今天这个地位,Yarn可以说是功不可没。因为有了Yarn,更多计算框架可以接入到Hdfs中,而不单单是MapReduce,到现在我们都知道,MapReduce早已经被Spark等计算框架赶超,而Hdfs却依然屹立不倒。究其原因,正式因为Yarn的包容,使得其他计算框架能专注于计算性能的提升。Hdfs可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,Yarn功不可没。
推荐阅读 :
从分治算法到 MapReduce
一个故事告诉你什么才是好的程序员
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
Hadoop Yarn框架详细解析的更多相关文章
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
- Hadoop MapReduceV2(Yarn) 框架简介
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ 对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详 ...
- Hadoop学习之YARN框架
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/,非常感谢分享! 对于业界的大数据存储及分布式处理系统来说,H ...
- Hadoop Yarn框架原理解析
在说Hadoop Yarn的原理之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTrac ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
- hadoop备战:yarn框架的搭建(mapreduce2)
昨天没有写好了没有更新,今天一起更新,yarn框架也是刚搭建好的. 我这里把hadoop放在了我的个人用户hadoop下了,你也能够尝试把它放在/usr/local,考虑的问题就相对多点. 主要的软硬 ...
- hadoop备战:yarn框架的简单介绍(mapreduce2)
新 Hadoop Yarn 框架原理及运作机制 重构根本的思想是将 JobTracker 两个基本的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控.新的资源管理器全局管理全部应用程序计 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- Hadoop YARN学习之Hadoop框架演进历史简述
Hadoop YARN学习之Hadoop框架演进历史简述(1) 1. Hadoop在其发展的过程中经历了多个阶段: 阶段0:Ad Hoc集群时代 标志着Hadoop的起源,集群以Ad Hoc.单用户方 ...
随机推荐
- [Swift]LeetCode383. 赎金信 | Ransom Note
Given an arbitrary ransom note string and another string containing letters from all the magazines, ...
- [Swift]LeetCode507. 完美数 | Perfect Number
We define the Perfect Number is a positive integer that is equal to the sum of all its positive divi ...
- [Swift]LeetCode843. 猜猜这个单词 | Guess the Word
This problem is an interactive problem new to the LeetCode platform. We are given a word list of uni ...
- 安装部署jumpserver3.0
1.安装依赖包yum -y install git readline-devel automake autoconf2.下载 jumpservergit clone https://github.co ...
- jupyter-notebook后home页面空白问题
jupyter-notebook后home页面空白问题 解决方案1 更换默认的浏览器,选择谷歌浏览器,很多360打不开的页面,更换谷歌后都能有效解决,并且确保是最新版本的google浏览器. 解决 ...
- IntelliJ IDEA 导入新项目
在现有的idea中close project 关闭当前项目, 然后import project
- centos7下误执行chmod -R 777 /后的权限修复方法
今天由于权限问题zz一般把/usr/bin和/usr/lib两个目录用chmod -R 777执行了一遍,结果各种问题出现,su root就报su:鉴定故障的错误.然后上网找教程很多都要求在root权 ...
- 使用mongoskin操作MongoDB
mongoskin是一个操作MongoDB的模型工具 相当于数据库类 与之相当的还有mongoose比较出名 安装模块(特地加了版本,这里被坑过,在Ubuntu中开发的好好的,部署到线上centos中 ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- Spring基础系列-参数校验
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/9953744.html Spring中使用参数校验 概述 JSR 303中提出了Bea ...