pyppeteer(python版puppeteer)基本使用
一、前言
以前使用selenium的无头浏览器,自从phantomjs2016后慢慢不更新了之后,selenium也开始找下家,这时候谷歌的chrome率先搞出来无头浏览器并开放了各种api,随后firefox也开始做。
现在selenium的测试也都支持这两个浏览器的无头模式了,只需要在引入的时候配置一下就可以了。之所以要采用谷歌chrome官方无头框架puppeteer的python版本pyppeteer,是因为有些网页是可以检测到是否是使用了selenium。并且selenium所谓的保护机制不允许跨域cookies保存以及登录的时候必须先打开网页然后后加载cookies再刷新的方式很不友好。
二、pyppeteer
github地址:https://miyakogi.github.io/pyppeteer/
pyppeteer这个项目是非官方的,是基于谷歌官方puppeteer的python版本。
注意:本来chrome就问题多多,puppeteer也是各种坑,加上pyppeteer是基于前者的改编python版本,也就是产生了只要前两个有一个有bug,那么pyppeteer就会原封不动的继承下来,本来这没什么,但是现在遇到的问题就是pyppeteer这个项目从18年9月份之后就没更新过了,前两者都在不断的更新迭代,而pyppeteer一直不更新,导致很多bug根本没人修复。
遇到的错误:
1)pyppeteer.errors.NetworkError: Protocol error Network.getCookies: Target close
控制访问指定url之后await page.goto(url),会遇到上面的错误,如果这时候使用了sleep之类的延时也会出现这个错误或者类似的time out。
这个问题是puppeteer的bug,但是对方已经修复了,而pyppeteer迟迟没更新,就只能靠自己了,搜了很多人的文章,例如:https://github.com/miyakogi/pyppeteer/issues/171 ,但是我按照这个并没有成功。
也有人增加一个函数,但调用这个参数依然没解决问题。
async def scroll_page(page):
cur_dist = 0
height = await page.evaluate("() => document.body.scrollHeight")
while True:
if cur_dist < height:
await page.evaluate("window.scrollBy(0, 500);")
await asyncio.sleep(0.1)
cur_dist += 500
else:
break
可以把python第三方库websockets版本7.0改为6.0就可以了,亲测可用。
pip uninstall websockets #卸载websockets
pip install websockets==6.0 #指定安装6.0版本
2)chromium浏览器多开页面卡死问题
解决这个问题的方法就是浏览器初始化的时候添加’dumpio’:True。
3)浏览器窗口很大,内容显示很小
上面的问题是需要设置浏览器显示大小,默认就是无法正常显示。可以看到页面左侧右侧都是空白,网站内容并没有完整铺满chrome.
browser = await launch({'headless': False,'dumpio':True, 'autoClose':False,'args': ['--no-sandbox', '--window-size=1366,850']})
await page.setViewport({'width':1366,'height':768})
通过上面设置Windows-size和Viewport大小来实现网页完整显示。
但是对于那种向下无限加载的长网页这种情况如果浏览器是可见状态会显示不全,针对这种情况的解决方法就是复制当前网页新开一个标签页粘贴进去就正常了
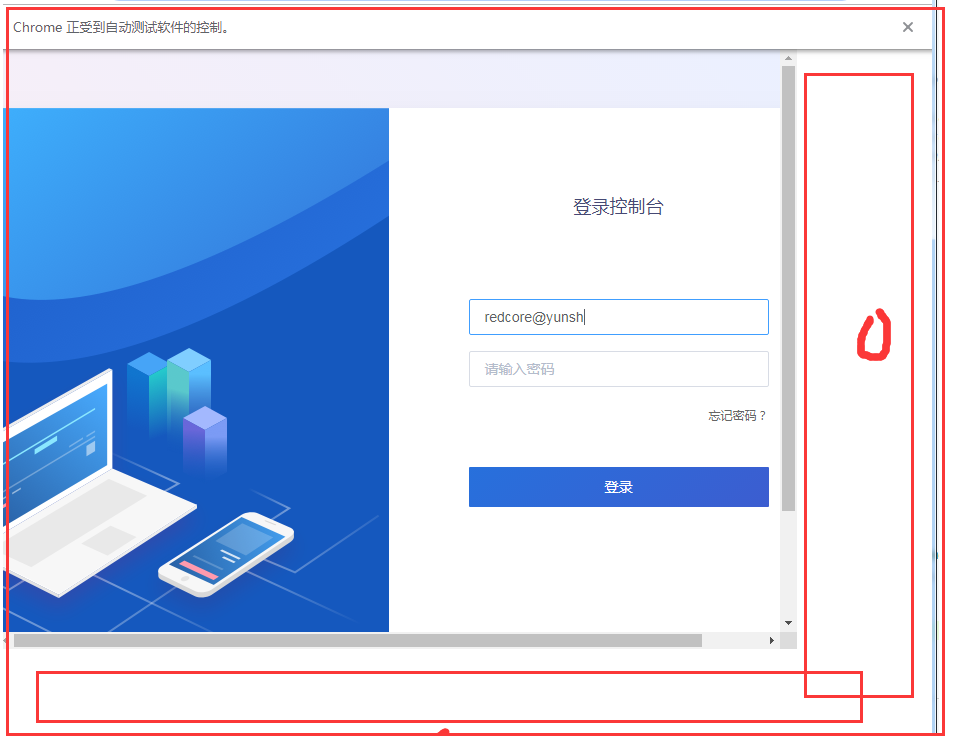
三、实际项目示例
import asyncio
from pyppeteer import launch
import time async def main():exepath = 'C:/Users/tester02/AppData/Local/Google/Chrome/Application/chrome.exe'
browser = await launch({'executablePath': exepath, 'headless': False, 'slowMo': 30})
page = await browser.newPage()
await page.setViewport({'width': 1366, 'height': 768})
await page.goto('http://192.168.2.66')
await page.type("#Login_Name_Input", "test02")
await page.type("#Login_Password_Input", "", )
await page.waitFor(1000)
await page.click("#Login_Login_Btn")
await page.waitFor(3000)
await browser.close() asyncio.get_event_loop().run_until_complete(main())
import asyncio
import time
from pyppeteer import launch async def gmailLogin(username, password, url):
#'headless': False如果想要浏览器隐藏更改False为True
# 127.0.0.1:1080为代理ip和端口,这个根据自己的本地代理进行更改,如果是vps里或者全局模式可以删除掉'--proxy-server=127.0.0.1:1080'
browser = await launch({'headless': False, 'args': ['--no-sandbox', '--proxy-server=127.0.0.1:1080']})
page = await browser.newPage()
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36') await page.goto(url) # 输入Gmail
await page.type('#identifierId', username)
# 点击下一步
await page.click('#identifierNext > content')
page.mouse # 模拟真实点击
time.sleep(10)
# 输入password
await page.type('#password input', password)
# 点击下一步
await page.click('#passwordNext > content > span')
page.mouse # 模拟真实点击
time.sleep(10)
# 点击安全检测页面的DONE
# await page.click('div > content > span')#如果本机之前登录过,并且page.setUserAgent设置为之前登录成功的浏览器user-agent了,
# 就不会出现安全检测页面,这里如果有需要的自己根据需求进行更改,但是还是推荐先用常用浏览器登录成功后再用python程序进行登录。 # 登录成功截图
await page.screenshot({'path': './gmail-login.png', 'quality': 100, 'fullPage': True})
#打开谷歌全家桶跳转,以Youtube为例
await page.goto('https://www.youtube.com')
time.sleep(10) if __name__ == '__main__':
username = '你的gmail包含@gmail.com'
password = r'你的gmail密码'
url = 'https://gmail.com'
loop = asyncio.get_event_loop()
loop.run_until_complete(gmailLogin(username, password, url))
# 代码由三分醉编写,网址www.sanfenzui.com,参考如下文章:
# https://blog.csdn.net/Chen_chong__/article/details/82950968
pyppeteer(python版puppeteer)基本使用的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
- 豆瓣top250(go版以及python版)
最近学习go,就找了一个例子练习[go语言爬虫]go语言爬取豆瓣电影top250,思路大概就是获取网页,然后根据页面元素,用正则表达式匹配电影名称.评分.评论人数.原文有个地方需要修改下patte ...
- python版接口自动化测试框架源码完整版(requests + unittest)
python版接口自动化测试框架:https://gitee.com/UncleYong/my_rf [框架目录结构介绍] bin: 可执行文件,程序入口 conf: 配置文件 core: 核心文件 ...
- 学习笔记24—win10环境下python版libsvm的安装
1.前言 由于毕业设计需要用到libsvm,所以最近专心于配置libsvm,曾经尝试过在matlab中安装,但是没有成功.最终在Python环境中完成安装. 2.LIBSVM介绍 LIBSVM 是台湾 ...
随机推荐
- B. Nirvana Codeforces Round #549 (Div. 2) (递归dfs)
---恢复内容开始--- Kurt reaches nirvana when he finds the product of all the digits of some positive integ ...
- XV Open Cup named after E.V. Pankratiev. GP of Three Capitals
A. Add and Reverse 要么全部都选择$+1$,要么加出高$16$位后翻转位序然后再补充低$16$位. #include<stdio.h> #include<iostr ...
- The Apache HBase™ Reference Guide
以下内容由http://hbase.apache.org/book.html#getting_started节选并改编而来. 运行环境:hadoop-1.0.4,hbase-0.94.22,jdk1. ...
- 基于.net的微服务架构下的开发测试环境运维实践
眼下,做互联网应用,最火的架构是微服务,最热的研发管理就是DevOps, 没有之一.微服务.DevOps已经被大量应用,它们已经像传说中的那样,可以无所不能.特来电云平台,通过近两年多的实践,发现完全 ...
- poj2976 Dropping tests(01分数规划 好题)
https://vjudge.net/problem/POJ-2976 又是一波c++AC,g++WA的题.. 先推导公式:由题意得 Σa[i]/Σb[i]<=x,二分求最大x.化简为Σ(a[i ...
- __x__(48)0910第六天__CSS Hack
CSS Hack: 不到万不得已,不要使用.不易于维护. 有一些情况,需要一段特殊代码在遇到特殊浏览器环境才执行,而在其他条件下,不执行. 此时,CSS Hack 就能实现. CSS Hack 实际上 ...
- JS-原型的某些概念
prototype:构造函数拥有一个对象,称为构造函数的原型属性,可以通过 构造函数prototype进行访问. __proto__: 构造函数所创造出的实例对象,可通过该属性访问原型对象. cons ...
- 获取node异步执行结果的方式
拿数据库操作举例: var connection = mysql.createConnection(); connection.query(sql,function(err,rows){xxx} ); ...
- qmake: could not exec '/usr/lib/x86_64-linux-gnu/qt4/bin/qmake': No such file or directory
执行 qmake -v 出现错误:qmake: could not exec ‘/usr/lib/x86_64-linux-gnu/qt4/bin/qmake’: No such file or di ...
- robotframework RF使用中需要安装的工具和库
确保 Python 3.6.2 安装成功 安装 如下 RF使用中需要的工具和库 1. RF 在两个Python中安装 robotframework执行命令 pip install robotframe ...