Spark基本架构
Spark基本架构图如下:
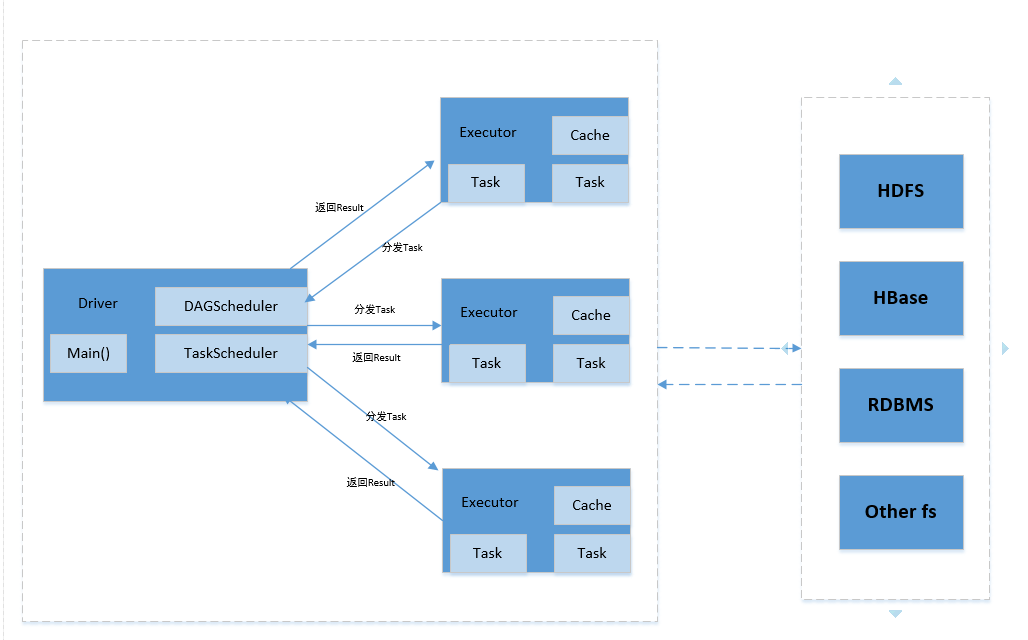
Client:客户端进程,负责提交作业。
Driver:一个Spark作业有一个spark context,一个Spark Context对应一个Driver进程,作业的main函数运行在Driver中。Driver主要负责Spark作业的解析,以及通过DAGSchduler划分stage,将Stage转化成TaskSet提交给TaskScheduler任务调度器,进而调度Task到Executor上执行。
Executor:负责执行Driver分发的Task任务。集群中一个节点可以启动多个Executor,每个Executor可以执行多个Task任务。
Cache:Spark提供了对RDD不同级别的缓存策略,分别可以缓存到内存、磁盘、外部分布式内存存储系统如Tachyon等。
Applicatio:提交的一个作业就是一个Appliation。一个Application只有一个Spark Context。
Job:RDD执行一次Action操作应付生成一个Job。
Task:Spark运行的基本单位,负责 处理RDD的计算逻辑。
Stage:DAGScheduler将Job划分为多个Stage,Stage的划分界限为Shuffle的产生,Suffle标志着上一个Stage的结束和下一个Stage的开始。
TaskSet:划分的Stage会转换成一组相关联的任务集。
RDD(Resilient Distributed Dataset):弹性分布式数据集,可以理解为一种只读的分布式多分区的数组,Spark计算操作都是基于RDD进行的,下面会有详细介绍。
DAG(Directed Acyclic Graph):有向无环图。Spark实现了DAG的计算模型,DAG计算模型是指将一个计算任务按照计算规则分解为若干子任务,这些子任务之间根据逻辑关系构建成有向无环图。
Spark基本架构的更多相关文章
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark Streaming 架构
图 1 Spark Streaming 架构图 组件介绍: Network Input Tracker : 通 过 接 收 器 接 收 流 数 据, 并 将 流 数 据 映 射 为 输 入DSt ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- Spark运行架构
http://blog.csdn.net/pipisorry/article/details/52366288 1. Spark运行架构 1.1 术语定义 lApplication:Spark App ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- Spark学习(一)——Spark运行架构
基本概念 在具体讲解Spark运行架构之前,需要先了解几个重要的概念: RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供 ...
- Spark运行架构详解
原文引自:http://www.cnblogs.com/shishanyuan/p/4721326.html 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appl ...
随机推荐
- volatile关键字作用
1.阻止编译器对代码进行优化.即读取某个变量值时,不从寄存器中读取而是从变量里读. 2.编译器的优化 在本次线程内,当读取一个变量时,为提高存取速度,编译器优化时有时会先把变量读取到一个寄存器中:以后 ...
- bzoj 3597 [Scoi2014] 方伯伯运椰子 - 费用流 - 二分答案
题目传送门 传送门 题目大意 给定一个费用流,每条边有一个初始流量$c_i$和单位流量费用$d_i$,增加一条边的1单位的流量需要花费$b_i$的代价而减少一条边的1单位的流量需要花费$a_i$的代价 ...
- 安全检查,Windows更新出现8024402F错误如何解决
背景,每个月都要进行例行检查,需要更新windows补丁包,病毒库等操作,谁知今天windows报错了: windows 代码8024402f 错误,原因是更新日志和缓冲出了问题. 解决步骤 : 1. ...
- Git设置文件或目录忽略跟踪的三种方式
1. 共享的忽略设置方式 本地仓库根目录,创建.gitignore文件,并编辑正则匹配需要忽略的文件或目录. .gitignore文件需要上传到仓库,同时会影响到他人,共享忽略设置 注意: .giti ...
- 【转】java线上程序排错经验2 - 线程堆栈分析
前言 在线上的程序中,我们可能经常会碰到程序卡死或者执行很慢的情况,这时候我们希望知道是代码哪里的问题,我们或许迫切希望得到代码运行到哪里了,是哪一步很慢,是否是进入了死循环,或者是否哪一段代码有问题 ...
- ip xfrm命令是做什么的?
答: 设置xfrm.xfrm(transform configuration)是一个IP框架,用来转换数据包的格式,也就是使用算法来加密数据包,该框架用作IPsec协议的一部分 ip xfrm sta ...
- Redis 单机版
Redis 支持单机版和集群,下面的步骤是单机版安装步骤 1. # yum install -y gcc-c++ 1.1 由于是c语言编写,所以需要安装支持组件 2. 把压缩包上传到linux服务器上 ...
- cuda cudnn tensorflow-gpu安装
Ububtu18.04下载cuda9.0 下载好后得到: CUDA 9.0仅支持GCC 6.0及以下版本,而Ubuntu 18.04预装GCC版本为7.3,需要安装gcc-6与g++-6 查看当前版本 ...
- python程序—名片管理系统
创建一个名片管理系统,实现增.删.改.查.四项功能 listcard = [] while True: print('**********欢迎来到名片管理系统**********') print(' ...
- nrf52832板子焊接后总结的经验
将之前打的nrf52832的板子拿到手了,经过一番焊接和调试后,发现了一些问题,因为是第一次画板焊接调试,很多地方做的不好,现在将自己的一些经验总结如下: 1 在制板之前,丝印层有必要好好的检查,建议 ...