A Deep Learning-Based System for Vulnerability Detection(一)
接着上一篇,讨论讨论具体步骤实现方法。步骤1-3分别在下面进行阐述,步骤4,6都是标准的,步骤5类似于步骤1-3。
结合这个图进行讨论详细步骤:
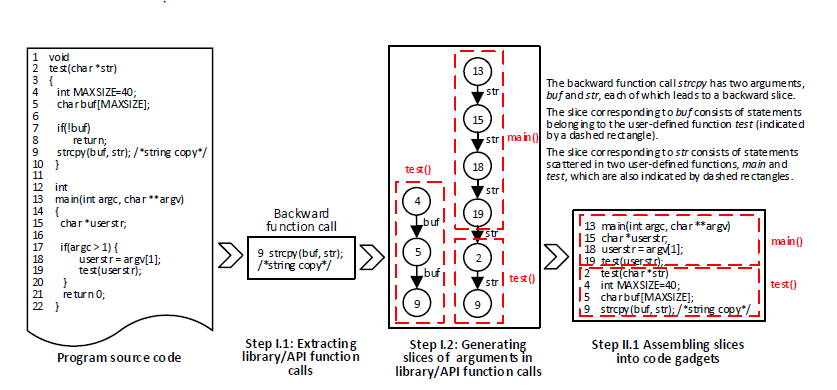
步骤1:提取库/API函数调用和程序片段
1.1将库/API函数调用分为两类:前向调用和后向调用,前向库/API函数调用是直接从外部输入接受一个或者多个输入的函数调用,例如命令行,程序,套接字或文件。后向库/API函数调用是不直接从程序运行的环境接受任何外部输入的函数调用。图中显示了一个后向库/API函数调用strcpy的示例(第9行),它是一个后向库/API函数调用,因为不接受任何外部输入。
向前和向后库/API函数调用之间的区别很重要。对于向前,受输入参数影响的语句是关键的,因为它们可能容易受到不恰当的参数值。对于后向,影响参数值的语句非常关键,因为它们可能使库/API函数调用变得脆弱,这个关键点可以用来指导代码小部件有关向量表示的启发式填充。
1.2提取程序片:该步骤生成与从训练程序中提取的库/API函数调用的参数相对应的程序片。定义两种切片:前向切片和后向切片,其中前向切片对应于受相关参数影响的语句,而后向切片对应于可影响相关参数的语句。利用数据依赖图,来提取这两种切片,基本思路如下:
·对于前向库/API函数调用中的每个参数,将生成一个或者多个前向切片,若是生成多个前向切片情况,有关参数的前向切片会在函数调用后分支。
·对于后向库/API函数调用中的每个参数,将生成一个或者多个后向切片,若是生成多个后向切片情况,有关参数的后向切片会在函数调用前合并。
图中显示了一个包含库函数调用strcpy的示例程序,它有两个参数buf和str。strcpy是一个后向库函数调用,针对每一个参数,生成一个后向切片。对于参数buf,切片包含三条语句,即程序的第4,5,9行,它们属于用户自定义的函数test。对于参数str,切片包含六条语句,即程序的第13,15,18,19,2,9行,前四行属于用户自定义的函数test,后两行属于用户定义的函数main。这两个切片就是链。线性结构通常只能表示一个单独的切片,而每个库函数调用经常生成多个相关的切片,所以切片一般用树或者链来表示。
步骤2:提取代码小部件并给其标记上真实数据
2.1将程序组装成代码小部件:按照下面的步骤将上一步生成的切片组装成代码小部件。
首先,给定一个库/API函数调用和相应的程序片段,我们将语句按照在用户定义函数中出现的顺序,将属于相同用户定义函数的代码段归为单个片段。如果任何语句有重复,则该重复被消除。
在图中所示的示例中,有三个语句(4,5,9)属于用户定义函数test与参数buf对应的程序切片,有两条语句(2,9)属于用户定义函数test与参数str对应的程序切片。因为这两个切片相关于同一个函数test,所以需要将它们组装成一个单独的块。通过在函数内依次出现的先后顺序,形成2->4->5->9->9的顺序,第9行重复,最终获得关于函数test的一块组装语句2->4->5->9。
其次,将属于不同用户定义函数的语句组成一个代码小部件。如果这些用户定义函数的两段语句之间已经存在一个顺序,则保留该顺序;否则,使用随机顺序。
在图中所示的示例中,组装用户定义函数main(13,15,18,19)和属于用户定义函数test(2,4,5,9),获得13->15->18->19->2->4->5->9,这是有关strcpy函数调用的代码小部件。这个代码小部件保存了与参数str对应的程序片中包含的用户定义函数的顺序。
2.2进行真值数据的标记:每个代码小部件需要标记真值,例如"1"代表脆弱的,“0”代表非脆弱的。如果代码小部件对应于训练数据集中已知的漏洞,则标记为"1";否则它标记为“0”。有关处理与特定漏洞数据源相关的程序是,进行真值的标记,这在后面章节讨论(涉及到神经网络部分)。
步骤3:将代码小部件装换成向量
3.1将代码小部件转换为它们的符号表示:其目的是在训练神经网络的程序中捕获一些语义信息。首先,移除非ascii字符和注释,因为它们与漏洞无关。
其次,以一对一的方式将用户定义的变量映射到符号名,比如“VAR1”,“VAR2”,同时注意到当多个变量映射到同一个符号名称上时,即它们出现在不同的代码小部件中。
最后,以一对一的方式将用户定义的函数映射到符号名,比如“FUN1”,“FUN2”,同时注意到当多个函数映射到同一个符号名称上时,即它们出现在不同的代码小部件中。
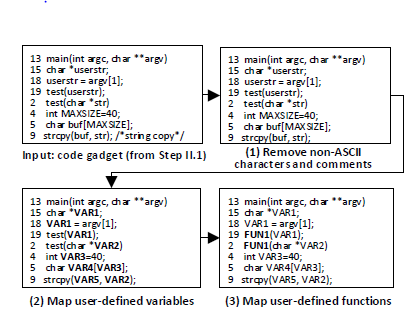
3.2将符号表示编码成向量:每个代码小部件需要通过符号表示编码为向量。为此,我们通过词法分析将符号表示中的代码小部件划分为一系列标记,包括标识符,关键字,运算和符号。
图中一个代码小部件用符号表示: strcpy(VAR5,VAR2); 用了7个标记来表示,这会导致大量的令牌,为了转换这些令牌为向量,使用word2vec工具[14],之所以选择它,是因为它被广泛用来进行文本挖掘[58]。这个工具基于分布式表示的思想,它将令牌映射成整数,然后将其转换为固定长度的向量[43]。
由于代码小部件可能具有不同数量的标记,因此相应的向量可能具有不同的长度。BLSTM以等长向量作为输入,我们需要一个调整。为此,引入一个参数T 的固定长度的向量来对应相关的代码小部件。
·向量比T 短时,有两种情况:如果代码小部件是从后切片或者多种后切片组合生成的,我们就在向前开始的地方填充多个0;否则,在向量结束的地方填充多个0.
·向量比T 长时,有两种情况:如果代码小部件是从后切片或者多种后切片组合生成的,我们就删除向量开始的多余部分;否则,删除向量结束的多余部分。
这确保从后向切片生成的每个代码小部件的最后一条语句是库/API函数调用,二从前向切片生成的每个代码小部件的最开始一条语句是库/API函数调用。因此,每个代码工具表示为T 位向量,向量的长度与BLSTM每一层的隐含节点的数量有关,该参数可以进行调整以提高漏洞检测的准确性(后面章节进行讨论)。
A Deep Learning-Based System for Vulnerability Detection(一)的更多相关文章
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- 论文翻译:2021_Towards model compression for deep learning based speech enhancement
论文地址:面向基于深度学习的语音增强模型压缩 论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年 引用格式:Tan K, Wang D L. Towards model c ...
- 个性探测综述阅读笔记——Recent trends in deep learning based personality detection
目录 abstract 1. introduction 1.1 个性衡量方法 1.2 应用前景 1.3 伦理道德 2. Related works 3. Baseline methods 3.1 文本 ...
- Paper Reading——LEMNA:Explaining Deep Learning based Security Applications
Motivation: The lack of transparency of the deep learning models creates key barriers to establishi ...
- A Deep Learning-Based System for Vulnerability Detection(二)
接着上一篇,这篇研究实验和结果. A.用于评估漏洞检测系统的指标 TP:为正确检测到漏洞的样本数量 FP:为检测到虚假漏洞样本的数量(误报) FN:为未检真实漏洞的样本数量(漏报) TN:未检测到漏洞 ...
- A Deep Learning-Based System for Vulnerability Detection
本篇文献作者提出了一种基于深度学习来检测软件漏洞的方案. 摘要:作者开始基于深度学习的漏洞检测研究,是为了减轻专家手工定义特性的繁琐任务,需要制定一些指导性原则来适用于深度学习去进行漏洞探 ...
- (转) Deep Learning Resources
转自:http://www.jeremydjacksonphd.com/category/deep-learning/ Deep Learning Resources Posted on May 13 ...
随机推荐
- JDK1.8源码(一)——java.util.ArrayList
ArrayList 定义 ArrayList 是一个用数组实现的集合,支持随机访问,元素有序且可以重复. public class ArrayList<E> extends Abstr ...
- python:数据库连接操作入门
模块 import pymssql,pyodbc 模块说明 pymssql和pyodbc模块都是常用的用于SQL Server.MySQL等数据库的连接及操作的模块,当然一些其他的模块也可以进行相应的 ...
- transient和synchronized的使用
transient和synchronized这两个关键字没什么联系,这两天用到了它们,所以总结一下,两个关键字做个伴! transient 持久化时不被存储,当你的对象实现了Serializable接 ...
- 【ASP.NET Core快速入门】(七)WebHost的配置、 IHostEnvironment和 IApplicationLifetime介绍、dotnet watch run 和attach到进程调试
WebHost的配置 我们用vs2017新建一个空网站HelloCore 这里的CreateDefaultBuilde实际上已经在内部替我们做好了默认配置. UseKestrel 使用kestrel ...
- Java递归读取文件路径下所有文件名称并保存为Txt文档
本文用递归的方法实现读取一个路径下面的所有文件并将文件名称保存到Txt文件中,亲测可用. 递归读取文件路径下的所有文件: /** * 递归读取文件路径下的所有文件 * * @param path * ...
- [angularjs] AngularJs 知识回顾
AngularJs 知识回顾 简介 1.通过指令扩展了 HTML,通过表达式绑定数据到 HTML: 2.一个 Js 框架: 3.指令: 通过被称为 指令 的新属性来扩展 HTML, 即为应用添加新功能 ...
- 杭电ACM2009--求数列的和
求数列的和 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...
- [Go] golang互斥锁mutex
1.互斥锁用于在代码上创建一个临界区,保证同一时间只有一个goroutine可以执行这个临界区代码2.Lock()和Unlock()定义临界区 package main import ( " ...
- PHP中使用 fsockopen curl 模拟异步处理
PHP它最大缺点就是无法实现多线程管理,其程序的执行都是从头到尾,按照逻辑一路执行下来,不可能出现分支,这一点是限制php在主流程序语言中往更高级的语言发展的原因之一. 在PHP中我们有的时候其实希望 ...
- C# 实现对PPT插入、编辑、删除表格
现代学习和办公当中,经常会接触到对表格的运用,像各种单据.报表.账户等等.在PPT演示文稿中同样不可避免的应用到各种数据表格.对于在PPT中插入表格,我发现了一个新方法,不过我用到了一款免费的.NET ...