kafka传数据到Flink存储到mysql之Flink使用SQL语句聚合数据流(设置时间窗口,EventTime)
网上没什么资料,就分享下:)
简单模式:kafka传数据到Flink存储到mysql 可以参考网站:
利用Flink stream从kafka中写数据到mysql
maven依赖情况:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.xxr</groupId>
<artifactId>flink</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.4.1</flink.version>
</properties>
<build>
<pluginManagement>
<plugins>
<!-- 设置java版本为1.8 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-extdirs</arg>
<arg>${project.basedir}/src/lib</arg>
</compilerArgs>
</configuration>
</plugin>
<!-- maven-assembly方式打包成jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.5</version>
<configuration>
<archive>
<manifest>
<mainClass>com.xxr.flink.stream_sql</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.8.0-beta1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.8.0-beta1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_2.11</artifactId>
<version>1.0.2</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-runtime -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime_2.11</artifactId>
<version>${flink.version}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
</dependencies>
</project>
配置文件及sql语句,时间窗口是1分钟:
public class JDBCTestBase {
//每过一分钟计算一分钟内的num最大值,以rowtime作为时间基准
public static final String SQL_MAX = "SELECT MAX(num) ,TUMBLE_END(rowtime, INTERVAL '1' minute) as wEnd FROM wiki_table group by TUMBLE(rowtime, interval '1' minute)";
public static final String SQL_AVG = "SELECT AVG(num) ,TUMBLE_END(rowtime, INTERVAL '1' minute) as wEnd FROM wiki_table group by TUMBLE(rowtime, interval '1' minute)";
public static final String SQL_MIN = "SELECT MIN(num) ,TUMBLE_END(rowtime, INTERVAL '1' minute) as wEnd FROM wiki_table group by TUMBLE(rowtime, interval '1' minute)";
public static final String kafka_group = "test-consumer-group";
public static final String kafka_zookper = "localhost:2181";
public static final String kafka_hosts = "localhost:9092";
public static final String kafka_topic = "wiki-result";
public static final String DRIVER_CLASS = "com.mysql.jdbc.Driver";
public static final String DB_URL = "jdbc:mysql://localhost:3306/db?user=user&password=password";
}
MySQL建表:
CREATE TABLE wiki (
Id int(11) NOT NULL AUTO_INCREMENT,
avg double DEFAULT NULL,
time timestamp NULL DEFAULT NULL,
PRIMARY KEY (Id)
)
发送数据到kafka,用的是flink example的wikiproducer:
Monitoring the Wikipedia Edit Stream
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer08;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.common.functions.MapFunction; public class WikipediaAnalysis {
public static void main(String[] args) throws Exception { StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource()); KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
}); DataStream<Tuple3<String, Long,Long>> result = keyedEdits
.timeWindow(Time.seconds(10))
.fold(new Tuple3<>("", 0L,0L), new FoldFunction<WikipediaEditEvent, Tuple3<String, Long,Long>>() {
@Override
public Tuple3<String, Long,Long> fold(Tuple3<String, Long,Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser().trim();
acc.f1 += event.getByteDiff();
acc.f2 = System.currentTimeMillis();
return acc;
}
}); result
.map(new MapFunction<Tuple3<String,Long,Long>, String>() {
@Override
public String map(Tuple3<String, Long,Long> tuple) {
return tuple.toString();
}
})
.addSink(new FlinkKafkaProducer08<>("localhost:9092", "wiki-result", new SimpleStringSchema()));
result.print();
see.execute();
}
}
重写RichSinkFunction,用于写入到mysql中:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Timestamp; import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import kafka.common.Config; public class WikiSQLSink extends RichSinkFunction<Tuple3<String,Long, Long>> { private static final long serialVersionUID = 1L;
private Connection connection;
private PreparedStatement preparedStatement;
String drivername = JDBCTestBase.DRIVER_CLASS;
String dburl = JDBCTestBase.DB_URL; @Override
public void invoke(Tuple3<String,Long, Long> value) throws Exception {
Class.forName(drivername);
connection = DriverManager.getConnection(dburl);
String sql = "INSERT into wiki(name,avg,time) values(?,?,?)";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, value.f0);
preparedStatement.setLong(2, value.f1);
preparedStatement.setLong(3, value.f2);
//preparedStatement.setTimestamp(4, new Timestamp(System.currentTimeMillis()));
preparedStatement.executeUpdate();
if (preparedStatement != null) {
preparedStatement.close();
}
if (connection != null) {
connection.close();
} } }
用Flink中流计算类,用的是EventTime,用sql语句对数据进行聚合,写入数据到mysql中去,sql的语法用的是是另一个开源框架Apache Cassandra:
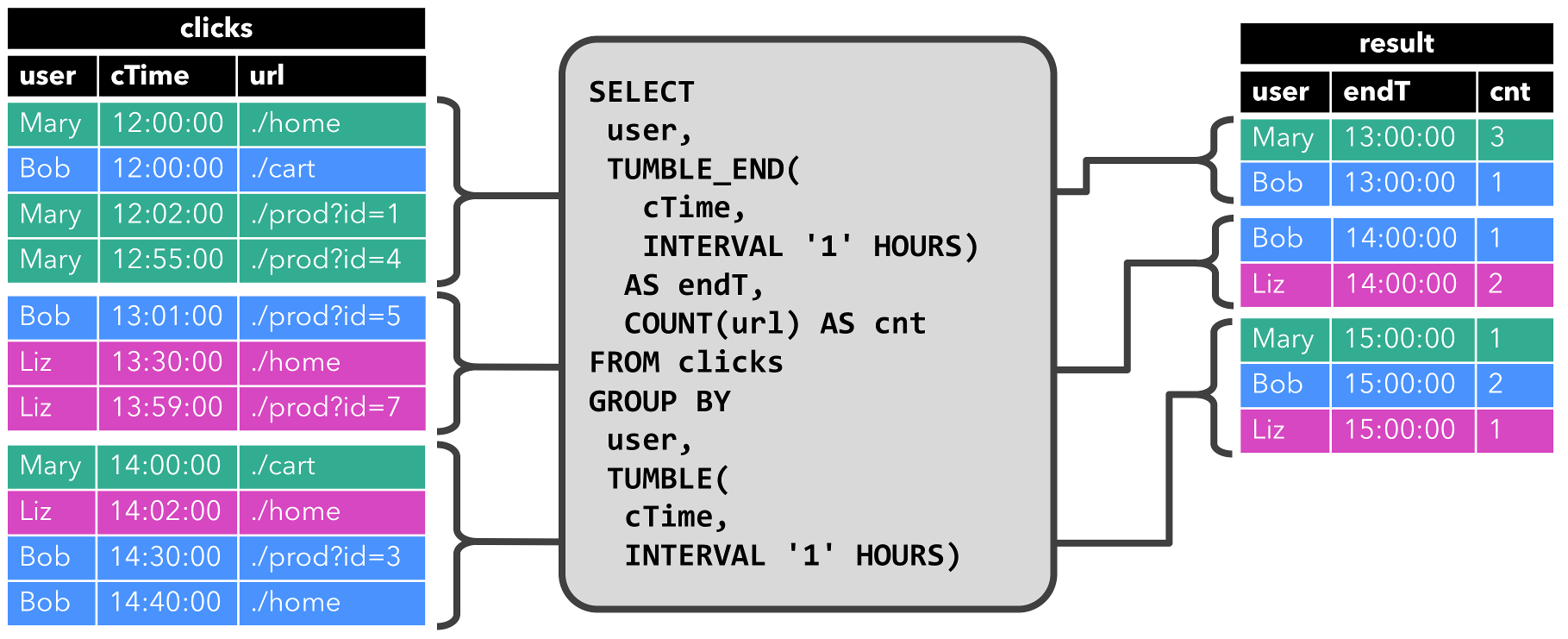
图片说明:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/streaming.html#time-attributes
package com.xxr.flink; import java.sql.Timestamp;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.TimeUnit; import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSink;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.core.fs.FileSystem.WriteMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.TimestampAssigner;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.WindowedTable;
import org.apache.flink.table.api.java.StreamTableEnvironment;
//时间参数网址
//https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/streaming.html#event-time
//Concepts & Common API
//https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/common.html#register-a-table
//SQL语法
//https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/sql.html
public class stream_sql {
public static void main(String[] args) throws Exception { Properties pro = new Properties();
pro.put("bootstrap.servers", JDBCTestBase.kafka_hosts);
pro.put("zookeeper.connect", JDBCTestBase.kafka_zookper);
pro.put("group.id", JDBCTestBase.kafka_group);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);
// env.getConfig().disableSysoutLogging(); //设置此可以屏蔽掉日记打印情况
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.enableCheckpointing(5000); DataStream<String> sourceStream = env
.addSource(new FlinkKafkaConsumer08<String>(JDBCTestBase.kafka_topic, new SimpleStringSchema(), pro)); DataStream<Tuple3<Long, String, Long>> sourceStreamTra = sourceStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return StringUtils.isNotBlank(value);
}
}).map(new MapFunction<String, Tuple3<Long, String, Long>>() {
@Override
public Tuple3<Long, String, Long> map(String value) throws Exception {
String temp = value.replaceAll("(\\(|\\))", "");
String[] args = temp.split(",");
try {
return new Tuple3<Long, String, Long>(Long.valueOf(args[2]), args[0].trim(), Long.valueOf(args[1])); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
return new Tuple3<Long, String, Long>(System.currentTimeMillis(), args[0].trim(),0L); }
}
});
//設置将哪个字段用于eventTime
DataStream<Tuple3<Long, String, Long>> withTimestampsAndWatermarks = sourceStreamTra
.assignTimestampsAndWatermarks(new FirstTandW());
//内置参数rowtime.rowtime就是EventTime protime是ProcessingTime
tableEnv.registerDataStream("wiki_table", withTimestampsAndWatermarks, "etime,name, num,rowtime.rowtime");
withTimestampsAndWatermarks.print();
// define sink for room data and execute query
JDBCAppendTableSink sink = JDBCAppendTableSink.builder().setDrivername(JDBCTestBase.DRIVER_CLASS)
.setDBUrl(JDBCTestBase.DB_URL).setQuery("INSERT INTO wiki (avg,time) VALUES (?,?)")
.setParameterTypes(Types.LONG, Types.SQL_TIMESTAMP).build();
//执行查询
Table result = tableEnv.sqlQuery(JDBCTestBase.SQL_MIN);
//写入csv
// result.writeToSink(new CsvTableSink("D:/a.csv", // output path
// "|", // optional: delimit files by '|'
// 1, // optional: write to a single file
// WriteMode.OVERWRITE)); // optional: override existing files
//写入数据库
result.writeToSink(sink); env.execute(); }
}
重写AssignerWithPeriodicWatermarks设置watermark,处理时间是EventTime的话必须要有这个方法,ProcessingTime 可忽略
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark; public class FirstTandW implements AssignerWithPeriodicWatermarks<Tuple3<Long,String, Long>> { private final long maxOutOfOrderness = 3500; // 3.5 seconds private long currentMaxTimestamp;
@Override
public long extractTimestamp(Tuple3<Long,String, Long> element, long previousElementTimestamp) {
// TODO Auto-generated method stub
long timestamp = element.f0;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
} @Override
public Watermark getCurrentWatermark() {
// TODO Auto-generated method stub
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
} }
maven assembly打包成jar,放flink运行就行了,不会打包看我博客
基础知识
Flink 的Window 操作
Flink流计算编程--在WindowedStream中体会EventTime与ProcessingTime
Flink文档写的很好。。刚开始做没仔细看,坑不少
git:https://github.com/xxrznj/flink-kafka-sql
kafka传数据到Flink存储到mysql之Flink使用SQL语句聚合数据流(设置时间窗口,EventTime)的更多相关文章
- 如何用VS EF连接 Mysql,以及执行SQL语句 和存储过程?
VS2013, MySQL5.7.18 , MySQL5.7.14 执行SQL语句: ztp_user z = new ztp_user(); object[] obj = new object[] ...
- 【转】MySQL用户管理及SQL语句详解
[转]MySQL用户管理及SQL语句详解 1.1 MySQL用户管理 1.1.1 用户的定义 用户名+主机域 mysql> select user,host,password from mysq ...
- 浅谈mysql配置优化和sql语句优化【转】
做优化,我在这里引用淘宝系统分析师蒋江伟的一句话:只有勇于承担,才能让人有勇气,有承担自己的错误的勇气.有承担错误的勇气,就有去做事得勇气.无论做什么事,只要是对的,就要去做,勇敢去做.出了错误,承担 ...
- MySQL数据库(一)—— 数据库介绍、MySQL安装、基础SQL语句
数据库介绍.MySQL安装.基础SQL语句 一.数据库介绍 1.什么是数据库 数据库即存储数据的仓库 2.为什么要用数据库 (1)用文件存储是和硬盘打交道,是IO操作,所以有效率问题 (2)管理不方便 ...
- 如何记录MySQL执行过的SQL语句
很多时候,我们需要知道 MySQL 执行过哪些 SQL 语句,比如 MySQL 被注入后,需要知道造成什么伤害等等.只要有 SQL 语句的记录,就能知道情况并作出对策.服务器是可以开启 MySQL 的 ...
- mysql里面如何用sql语句让字符串转换为数字
sql语句将字符串转换为数字默认去掉单引号中的空格,遇到空格作为字符串截止, SELECT '123 and 1=1' +0 结果为123 MySQL里面如何用sql语句让字符串的‘123’转换为数字 ...
- mysql进阶(十九)SQL语句如何精准查找某一时间段的数据
SQL语句如何精准查找某一时间段的数据 在项目开发过程中,自己需要查询出一定时间段内的交易.故需要在sql查询语句中加入日期时间要素,sql语句如何实现? SELECT * FROM lmapp.lm ...
- MySQL用户管理及SQL语句详解
1.1 MySQL用户管理 1.1.1 用户的定义 用户名+主机域 mysql> select user,host,password from mysql.user; +--------+--- ...
- mysql优化:explain分析sql语句执行效率
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优 ...
随机推荐
- Struts2(六)result
一.result简述 result:输出结果:第个Action返回一个字符串,Struts2根据这个值来决定响应结果 name属性:result的逻辑名.和Actin里的返回值匹配,默认"s ...
- poj 1286 Necklace of Beads & poj 2409 Let it Bead(初涉polya定理)
http://poj.org/problem?id=1286 题意:有红.绿.蓝三种颜色的n个珠子.要把它们构成一个项链,问有多少种不同的方法.旋转和翻转后同样的属于同一种方法. polya计数. 搜 ...
- cocos2d 重写顶点着色语言
bool CCShaderSprite::initWithFile( const char *pszFilename ) { bool ret=false; do { ret=CCSpri ...
- 了解NoSQL
近期总是提到NoSQL这个词汇.起初仅仅知道,应该是一种数据库而已,仅仅是这样的数据库眼下符合当前互联网的需求,应用比較广泛.逐渐发现,当前的各个公司在招聘信息中会有掌握NoSQL的优先等要求. ...
- Android Bitmap与String互转(转)
/** * 图片转成string * * @param bitmap * @return */ public static String convertIconToString(Bitmap bitm ...
- Eclipse 如何创建Web项目
Eclipse 如何创建Web项目 CreateTime--2018年3月8日16:43:33 Author:Marydon 第一步: 右键-->New-->Dynamic Web P ...
- 〖Linux〗Ubuntu13.10中使用虚拟机对MTK手机进行线刷
最近一个同学把一台MTK手机刷坏了,在我的笔记本电脑上没有WindowsXp操作系统: 而在MTK线刷过程中,最好的刷机系统便是WindowsXP3,于是有了想在Linux中直接开启XP虚拟机来刷机的 ...
- 安装 nvm 遇到的坑
本篇文章由:http://xinpure.com/encountered-nvm-installation-pits/ 说两句 以前开发都是用最新的 Node 版本,不过难免会有旧项目需要使用低版本做 ...
- 老毛桃pe装机工具备份系统
电脑故障可以说是难以避免的,误操作或者修改了哪个设置系统就莫名其妙崩溃了.这在日常使用当中并不鲜见,许多用户就会寻求备份系统方法.有没有好的一键备份系统教程可以参考呢?在本篇教程中,就容我跟大家讲讲怎 ...
- 【php】基础学习4
这部分主要包括php面向对象的程序设计,具体如下: <html xmlns=http://www.w3.org/1999/xhtml> <head> <meta http ...