elasticsearch(一) 之 elasticsearch初识
目录
一 、elasticsearch
elasticsearch 是一个开源的具有高度扩展性的全文搜索和分析引擎。它可以快速帮助我们存储和搜索、分析大量数据。
在运维方面,我们常用它来存储和分析日志数据,通过filebeat +(redis)+ELK 搭建一个可视化的实时日志分析搜索平台。让业务人员,开发人员可以该平台查看数据。
elasticsearch 是一个接近实时的搜索平台,从index文档到可搜索文档只有少量的延迟(通常是一秒)
ELK架构图
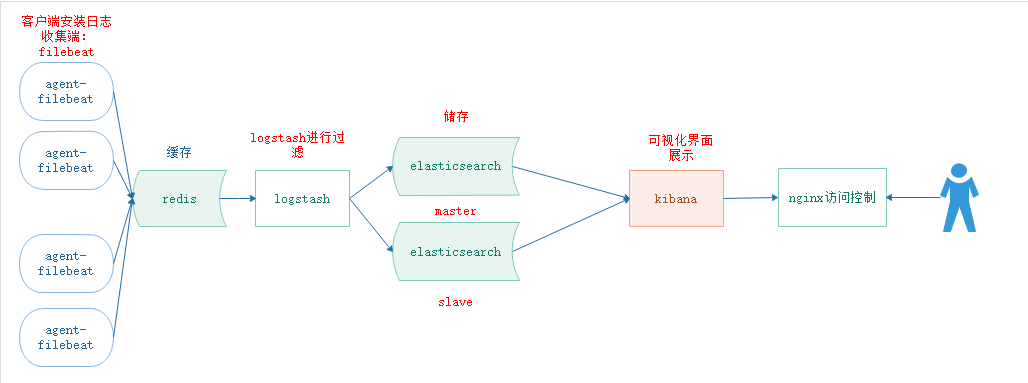
二 、 elasticsearch 名词解释
集群(cluster)
一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。集群具有唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
确保不要在不同的环境中重用相同的群集名称,否则最终会导致节点加入错误的群集。您可以使用logging-dev,logging-stage以及logging-prod 用于开发,登台和生产集群。
请注意,如果集群中只有一个节点,那么它是完全正常的。此外,您还可以拥有多个独立的集群,每个集群都有自己唯一的集群名称。
节点(node)
节点是作为集群一部分的单个服务器,存储数据并参与集群的索引和搜索功能。就像集群一样,节点由名称标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符(UUID)。如果不使用默认值,可以定义所需的任何节点名称。此名称对于管理目的非常重要,您可以在其中识别网络中哪些服务器与Elasticsearch集群中的哪些节点相对应。
可以将节点配置为按集群名称加入特定集群。默认情况下,每个节点都设置为加入一个名为elasticsearch的集群,这意味着如果您在网络上启动了许多节点并且假设它们可以相互发现 - 它们将自动形成并加入一个名为的集群elasticsearch。
在单个集群中,您可以拥有任意数量的节点。此外,如果您的网络上当前没有其他Elasticsearch节点正在运行,则默认情况下启动单个节点将形成一个名为的新单节点集群elasticsearch。
索引(index)
索引是具有某些类似特征的文档集合。例如,您可以拥有客户数据的索引,产品目录的索引以及订单数据的一个索引。索引由名称标识(必须全部小写),此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。
在单个群集中,您可以根据需要定义任意数量的索引。在实际的情况中,我们通常会按照天数创建索引,每天一个索引。
type(类型)
这个类型在6.0.0中被删除
Document(文档)
文档是可以编制索引的基本信息单元。一个索引是由一个或者或者多个文档构成的,例如,您可以为单个客户提供文档,为单个产品提供另一个文档,为单个订单提供另一个文档。该文档以JSON(JavaScript Object Notation)表示,JSON是一种普遍存在的互联网数据格式。
在索引/类型中,您可以根据需要存储任意数量的文档。请注意,尽管文档实际上驻留在索引中,但实际上必须将文档编入索引/分配给索引中的类型。
(就是我们查出来的每一条结果)
shards(分片)Replicas(副本)
索引可能存储大量可能超过单个节点的硬件限制的数据。例如,占用1TB磁盘空间的十亿个文档的单个索引可能不适合单个节点的磁盘,或者可能太慢而无法单独从单个节点提供搜索请求。
为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
分片很重要,主要有两个原因:
它允许您水平拆分/缩放内容量
它允许您跨分片(可能在多个节点上)分布和并行化操作,从而提高性能/吞吐量
分片的分布方式以及如何将其文档聚合回搜索请求的机制完全由Elasticsearch管理,对用户而言是透明的。在可能发生故障的网络/云环境中,非常有用,强烈建议使用故障转移机制,以防分片/节点以某种方式脱机或因任何原因消失。为此,Elasticsearch允许您将索引的分片的创建Replicas(副本)
Replicas很重要,主要有两个原因:
它在分片/节点发生故障时提供高可用性。因此,请务必注意,副本分片永远不会在与从中复制的原始/主分片相同的节点上分配。
它允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,每个索引可以拆分为多个分片。索引也可以副本为零(表示没有副本)或更多次。复制后,每个索引都将具有主分片(从中复制的原始分片)和副本分片(主分片的副本)。可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您还可以随时动态更改副本数。您可以使用_shrink和_splitAPI 更改现有索引的分片数,但这不是一项简单的任务,在之前预先计划好预正确的分片数量才是最佳方法。
默认情况下,Elasticsearch中的每个索引都分配了5个主分片和1个副本,这意味着如果群集中至少有两个节点,则索引将包含5个主分片和另外5个副本分片(1个完整副本),总计为每个索引10个分片。但是如果是单节点的话,默认是只有5主分片没有副本的。
每个Elasticsearch分片都是基于Lucene索引。单个Lucene索引中可以包含最大数量的文档。截止LUCENE-5843,限制是2,147,483,519(= Integer.MAX_VALUE - 128)文档。您可以使用_cat/shardsAPI 监控分片大小。
elasticsearch(一) 之 elasticsearch初识的更多相关文章
- 【ElasticSearch篇】--ElasticSearch从初识到安装和应用
一.前述 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,在企业中全文搜索时,特别常用. 二.常用概念 clu ...
- 【分布式搜索引擎】Elasticsearch之开启Elasticsearch的用户名密码验证
一.首先在elasticsearch配置文件中开启x-pack验证, 修改config目录下面的elasticsearch.yml文件,在里面添加如下内容,并重启 xpack.security.ena ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- ElasticSearch(十七)初识倒排索引
现在有两条document: doc1:I really liked my small dogs, and I think my mom also liked them. doc2:He never ...
- python使用elasticsearch模块操作elasticsearch
1.创建索引 命令如下 from elasticsearch import Elasticsearch es = Elasticsearch([{"host":"10.8 ...
- Elasticsearch 系列3 --- Elasticsearch配置
一. 位置 ES的配置文件位于安装目录\config下面,主要有 (1) elasticsearch.yml ES系统的配置: (2) jvm.options Java虚拟机配置: (3) log4j ...
- 【ElasticSearch】:elasticsearch.yml配置
ElasticSearch5的elasticsearch.yml配置 注意 elasticsearch.yml中的配置,冒号和后面配置值之间有空格 cluster.name: my-applicati ...
- 【elasticsearch】关于elasticSearch的基础概念了解【转载】
转载原文:https://www.cnblogs.com/chenmc/p/9516100.html 该作者本系列文章,写的很详尽 ================================== ...
- Elasticsearch学习之ElasticSearch 5.0.0 安装部署常见错误或问题
ElasticSearch 5.0.0 安装部署常见错误或问题 问题一: [--06T16::,][WARN ][o.e.b.JNANatives ] unable to install syscal ...
- Elasticsearch笔记(一)—Elasticsearch安装配置
原文链接:https://my.oschina.net/jhao104/blog/644909 摘要: ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文 ...
随机推荐
- HDU6026 Deleting Edges 2017-05-07 19:30 38人阅读 评论(0) 收藏
Deleting Edges Time ...
- hdu1257 最少拦截系统(贪心) 2016-05-19 20:28 90人阅读 评论(0) 收藏
最少拦截系统 Problem Description 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能 ...
- Ansible免密码登陆
配置Linux主机无密码访问 生成秘钥 ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to ...
- 结对编程--四则运算(Java)梅进鹏 欧思良
结对编程--四则运算(Java)梅进鹏 欧思良 Github项目地址:https://github.com/MeiJinpen/Arithmetic 功能要求 题目:实现一个自动生成小学四则运算题目的 ...
- Tomcat的error-page掩盖action实例化的exception
在使用Struts2+Spring+Tomcat开发的时候,为了避免骚扰用户,线上系统我们一般会定义错误处理页面.但是如果开发环境中也这么做(在web.xml定义了错误转发页面),而碰巧某个actio ...
- OpenDiscussion_DataDrivenDesign
本文源于公司内部技术交流,如有不当之处,还请指正. Content: 1. What is Data-driven design? 2. WPF revolution. 3. More about O ...
- 解决微服务网关Ocelot使用AddStoreOcelotConfigurationInConsul后请求404问题
一个小插曲,最近研究 netcore 微服务网关,在使用AddStoreOcelotConfigurationInConsul将配置存到consul后,任何经过网关的请求都出现404,并且没有任何有用 ...
- BitAdminCore框架更新日志20180523
20180523更新内容 本次更新两个内容,一是增加视频处理功能,二是增加定时服务功能. 视频处理 定时服务 BitAdminCore框架,用最少的代码,实现最多的功能 本次新暂未发布,后续有空发布 ...
- 【mysql】使用Navicat连接数据库
1 连接数据库 点击左下角测试一下 提示 输入 select host,user,plugin,authentication_string from mysql.user; 查看用户信息 注意这里我们 ...
- 毕业回馈-89C51之数码管的使用
7段码的数码管由7个LED等共同组成,根据公共端的不同有共阴和共阳之分.现在很多数码管在7段码的基础上加了一个.即dp,其内部结构如下图所示: 公共端为LED灯的阴极,所以为共阴极接法: 公共端为阳极 ...