MySQL实例crash的案例分析
【作者】
王栋:携程技术保障中心数据库专家,对数据库疑难问题的排查和数据库自动化智能化运维工具的开发有强烈的兴趣。
【问题描述】
我们生产环境有一组集群的多台MySQL服务器(MySQL 5.6.21),不定期的会crash,但error log中只记录了重启信息,未记录crash时的堆栈:
mysqld_safe Number of processes running now: 0
mysqld_safe mysqld restarted
接下来首先排查系统日志/var/log/message文件,crash时没有其他异常信息,也不是OOM导致的。
【排查思路】
由于日志中未记录有价值的信息。为定位crash的原因,首先开启mysql core dump的功能。
下面是开启core dump的步骤:
1、 在my.cnf文件中增加2个配置项
[mysqld]
core_file
[mysqld_safe]
core-file-size=unlimited2、修改系统参数,配置suid_dumpable
echo 1 >/proc/sys/fs/suid_dumpable3、重启mysql服务,配置生效
【问题分析】
开启core dump后,服务器再次crash时生成了core file。
用gdb分析生成的core file,可以看到crash时的堆栈信息如下:
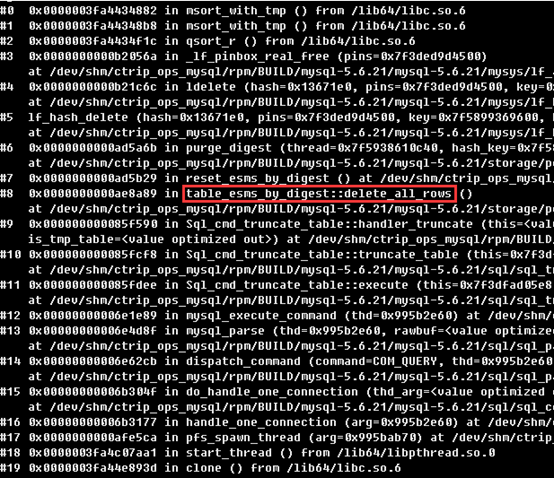
从函数table_esms_by_digest::delete_all_rows可以看出触发crash的是truncate table events_statements_summary_by_digest操作。
我们内部有个DML的分析工具,用来统计数据库每分钟增删改查的访问量。该工具的数据源是events_statements_summary_by_digest表,采集程序会每一分钟采集一次这张表的数据,采集完成后执行truncate操作。
暂停这组集群上DML采集程序后MySQL没有再发生crash。
进一步分析多个core file,发现最终函数的调用都发生在_lf_pinbox_real_free函数上。
结合现场环境,有两处地方值得分析:
1、 内存的不正常值。当打印该变量时,此处变量的地址偏低,不太正常:
(gdb) p pins->pinbox
$2 = (LF_PINBOX *) 0x13672082、红字部分为pfs逐条释放digest记录的操作,正在释放某行数据时出现错误:
void reset_esms_by_digest()
{
uint index;
if (statements_digest_stat_array == NULL)
return;
PFS_thread *thread= PFS_thread::get_current_thread();
if (unlikely(thread == NULL))
return;
for (index= 0; index statements_digest_stat_array[index].reset_index(thread);
statements_digest_stat_array[index].reset_data();
}
digest_index= 1;
}
猜测有两种可能导致错误:
1、高并发下,对内存访问出现冲突;
2、某个特殊SQL导致,在处理hash时。
在网上搜索类似的问题,有了进一步的进展,基本确定了这个问题是bug导致
如下Mysql的bug report中讲述了类似问题
https://bugs.mysql.com/bug.php?id=73979
更详细的环境描述如下连接中
https://bugs.launchpad.net/percona-server/+bug/1351148
查到5.6.35上的bug fix的修复内容,和我们碰到的情况非常类似。
对比_lf_pinbox_real_free的修改,该部分确实进行很大的调整。
下面是MySQL 5.6.35函数_lf_pinbox_real_free的代码片段:
static void _lf_pinbox_real_free(LF_PINS *pins)
{
LF_PINBOX *pinbox= pins->pinbox;
struct st_match_and_save_arg arg = {pins, pinbox, pins->purgatory};
pins->purgatory= NULL;
pins->purgatory_count= 0;
lf_dynarray_iterate(&pinbox->pinarray,
(lf_dynarray_func)match_and_save, &arg);
if (arg.old_purgatory)
{
void *last= arg.old_purgatory;
while (pnext_node(pinbox, last))
last= pnext_node(pinbox, last);
pinbox->free_func(arg.old_purgatory, last, pinbox->free_func_arg);
}
}下面是MySQL 5.6.21函数的_lf_pinbox_real_free的代码片段
static void _lf_pinbox_real_free(LF_PINS *pins)
{
int npins;
void *list;
void **addr= NULL;
void *first= NULL, *last= NULL;
LF_PINBOX *pinbox= pins->pinbox;
npins= pinbox->pins_in_array+1;
if (pins->stack_ends_here != NULL)
{
int alloca_size= sizeof(void *)*LF_PINBOX_PINS*npins;
if (available_stack_size(&pinbox, *pins->stack_ends_here) > alloca_size)
{
struct st_harvester hv;
addr= (void **) alloca(alloca_size);
hv.granary= addr;
hv.npins= npins;
_lf_dynarray_iterate(&pinbox->pinarray,
(lf_dynarray_func)harvest_pins, &hv);
npins= hv.granary-addr;
if (npins)
qsort(addr, npins, sizeof(void *), (qsort_cmp)ptr_cmp);
}
}
同时观察到出问题的集群有指标异常,QPS不到6000,Threads_connected将近8000。(对比其他高并发的集群,QPS在20000以上,Threads_connected也只有300左右)。
排查应用端的连接方式,了解到其中一个应用有近百台应用服务器,可能同时发起请求,却没有合理的复用连接,维持大量的连接线程增大了bug触发的概率。
Bugs Fixed的描述如下:
Miscalculation of memory requirements for qsort operations could result in stack overflow errors in situations with a large number of concurrent server connections. (Bug #73979, Bug #19678930, Bug #23224078)【解决思路】
我们通过分析crash时的core file文件,找到crash时的触发条件,暂停DML采集程序(truncate table events_statements_summary_by_digest操作)后恢复。
后面了解到这是MySQL的一个bug,在MySQL 5.6.35版本后已修复。这个bug在应用端与数据库建立大量的连接时,更容易触发。
MySQL实例crash的案例分析的更多相关文章
- 170301、使用Spring AOP实现MySQL数据库读写分离案例分析
使用Spring AOP实现MySQL数据库读写分离案例分析 原创 2016-12-29 徐刘根 Java后端技术 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案 ...
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- mysql转ElasticSearch的案例分析
前言 最近工作中在进行一些技术优化,为了减少对数据库的压力,对于只读操作,在程序与db之间加了一层-ElasticSearch.具体实现是db与es通过bin-log进行同步,保证数据一致性,代码调用 ...
- 使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- MySQL排序原理与案例分析
前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct ...
- [转]MySQL批量更新死锁案例分析
文章出处:http://blog.csdn.net/aesop_wubo/article/details/8286215 问题描述 在做项目的过程中,由于写SQL太过随意,一不小心就抛了一个死锁异常, ...
- [转]MySQL排序原理与案例分析
这篇文章非常好,就把他转过来 前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Grou ...
- MySQL批量更新死锁案例分析--转载
问题描述 在做项目的过程中,由于写SQL太过随意,一不小心就抛了一个死锁异常,如下: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackE ...
- MySQL数据库crash的问题分析
[问题] 生产环境有多台slave服务器,不定期的会crash,下面是error log中的堆栈信息 Thread pointer: 0x7f1e54b26410 Attempting backtra ...
随机推荐
- [ Laravel 5.5 文档 ] 底层原理 —— 一次 Laravel 请求的生命周期
Posted on 2018年3月5日 by 学院君 简介 当我们使用现实世界中的任何工具时,如果理解了该工具的工作原理,那么用起来就会得心应手,应用开发也是如此.当你理解了开发工具如何工作,用起 ...
- Mina 系列(四)之KeepAliveFilter -- 心跳检测
Mina 系列(四)之KeepAliveFilter -- 心跳检测 摘要: 心跳协议,对基于CS模式的系统开发来说是一种比较常见与有效的连接检测方式,最近在用MINA框架,原本自己写了一个心跳协议实 ...
- [转]docker 基本原理及快速入门
版权声明:原创作品, 来自海牛部落-青牛,http://hainiubl.com/topics/13 什么是docker Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud ...
- 将C语言宏定义数值转换成字符串!
将C语言宏定义转换成字符串! 摘自:https://blog.csdn.net/happen23/article/details/50602667 2016年01月28日 19:15:47 六个九十度 ...
- ocilib初体验
#ocilib下载 http://sourceforge.net/projects/orclib/files/ #安装 tar -zxvf ocilib-3.9.3-gnu.tar.gz ./conf ...
- 使用JDBC连接MySql时出现:The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration
在连接字符串后面加上?serverTimezone=UTC 其中UTC是统一标准世界时间. 完整的连接字符串示例:jdbc:mysql://localhost:3306/test?serverTime ...
- 《Linux多线程服务端编程——使用muduo C++网络库》读书笔记
第一章 线程安全的对象生命期管理 第二章 线程同步精要 第三章 多线程服务器的适用场合与常用编程模型 第四章 C++多线程系统编程精要 1.(P84)11个常用的最基本Pthreads函数: 2个:线 ...
- C语言学生管理系统源码分享
大家好 我就是如假包换的...陈玲 自从运营了C语言程序设计微信公众号 很多粉丝都给我备注 ...奇葩 实在是不敢当 也被人开始叫玲玲姐 我知道 很多人都想看我出境 我本人也有 年多的舞台演讲训练 实 ...
- C++中的矩阵运算
C++中的矩阵运算 1. 2阶矩阵的逆矩阵公式
- 软件工程 wc.exe 代码统计作业
软件工程 wc.exe 代码统计作业分享 1. Github 项目地址 https://github.com/EdwardLiu-Aurora/WordCount 更好地阅读本文,可点击这里 基本要求 ...