布隆过滤器redis缓存
Bloom Filter布隆过滤器
算法背景
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希
表,Hash table)等等数据结构都是这种思路,存储位置要么是磁盘,要么是内存。很多时候要么是以时间换空间,要么是以空间换时
间。
在响应时间要求比较严格的情况下,如果我们存在内里,那么随着集合中元素的增加,我们需要的存储空间越来越大,以及检索的时间越
来越长,导致内存开销太大、时间效率变低。
此时需要考虑解决的问题就是,在数据量比较大的情况下,既满足时间要求,又满足空间的要求。即我们需要一个时间和空间消耗都比较
小的数据结构和算法。Bloom Filter就是一种解决方案。
Bloom Filter 概念
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以
用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元
素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter”不适合那些“零错误的应用场合。
而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。
Bloom Filter 原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我
们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检
元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概
率。

Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,
那么可以通过建立一个白名单来存储可能会误判的元素。
删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判
断。可以采用Counting Bloom Filter
Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个
数k,并选择hash函数
(1)Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式: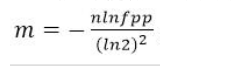
(2)哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k: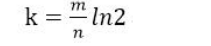
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较
麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数
布隆过滤器redis缓存的更多相关文章
- 使用BloomFilter布隆过滤器解决缓存击穿、垃圾邮件识别、集合判重
Bloom Filter是一个占用空间很小.效率很高的随机数据结构,它由一个bit数组和一组Hash算法构成.可用于判断一个元素是否在一个集合中,查询效率很高(1-N,最优能逼近于1). 在很多场景下 ...
- redis缓存穿透穿透解决方案-布隆过滤器
redis缓存穿透穿透解决方案-布隆过滤器 我们先来看一段代码 cache_key = "id:1" cache_value = GetValueFromRedis(cache_k ...
- 详细解析Redis中的布隆过滤器及其应用
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货. 什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告 ...
- Redis中的布隆过滤器及其应用
什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在.当布隆过滤器说,某种东西 ...
- Redis()- 布隆过滤器
一.布隆过滤器 布隆过滤器:一种数据结构.由二进制数组(很长的二进制向量)组成的.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识 ...
- 高可用Redis(十三):Redis缓存的使用和设计
1.缓存的受益和成本 1.1 受益 1.可以加速读写:Redis是基于内存的数据源,通过缓存加速数据读取速度 2.降低后端负载:后端服务器通过前端缓存降低负载,业务端使用Redis降低后端数据源的负载 ...
- 布隆过滤器(Bloom Filter)原理以及应用
应用场景 主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等. 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的 ...
- Redis缓存穿透和雪崩
缓存穿透 用户想要查询一个数据 在redis缓存数据库中没有获取到 就会向后端的数据库中查询. 当用户很多 都去访问后端数据库的话,这就会给数据库带来很大的压力. 常见场景:秒杀活动 等 解决方法: ...
- 布隆过滤器(Bloom Filter)简要介绍
一种节省空间的概率数据结构 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判.但是布隆过滤器也不是特别不精确,只要参数设置的 ...
随机推荐
- 2018.08.19 NOIP模拟 number(类数位dp)
Number 题目背景 SOURCE:NOIP2015-SHY-10 题目描述 如果一个数能够表示成两两不同的 3 的幂次的和,就说这个数是好的. 比如 13 是好的,因为 13 = 9 + 3 + ...
- 解决Docker时区与主机时区不一致的问题
在Dockerfile里面增加以下红色的部分 FROM hub.chinacloud.com/common/jdk:8MAINTAINER xxx@chinacloud.com.cn RUN mkdi ...
- bootstrap-treeview的 简单使用
理论:http://blog.csdn.net/babyxue/article/details/73835444 插依赖Bootstrap 和jQuery <link href="~/ ...
- qq强制聊天工具
当你想和别人聊天, 别人有不理你的时候可以用上哦!!!特别是情人吵架的时候, 呵呵 复制下面的代码: @echo off title DIY-QQ强制聊天工具color 0a echo. echo. ...
- 201709021工作日记--Volley源码解读(四)
接着volley源码(三)继续,本来是准备写在(三)后面的,但是博客园太垃圾了,写了半天居然没保存上,要不是公司这个博客还没被限制登陆,鬼才用这个...真是垃圾 继续解读RequestQueue的源码 ...
- STL中list中push_back(对象)保存对象的内部实现
STL中list中push_back(对象)保存对象的内部实现 1. 在容器中,存放的是对象拷贝 #include<iostream> #include<list> using ...
- SSH中设置字符编码防止乱码
1.在web.xml中加入一个过滤器和过滤范围的配置 <filter><filter-name>encoding</filter-name><filter-c ...
- ORACLE EBS xml publisher 报表输出字符字段前部"0"被EXCEL自动去掉问题
http://www.cnblogs.com/lzsu1989/archive/2012/10/17/2728528.html Oracle EBS 提供多种报表的开发和输出形式,由于MS Ex ...
- AME
http://wenku.baidu.com/view/a9dbebc789eb172ded63b7f4.htmlhttp://wenku.baidu.com/view/dde6eb040740be1 ...
- C99 中 main 函数的写法
今天在论坛看见有人讨论 C 语言中 main 函数的写法,看到结论才知道 main 函数的正确写法. 被老谭酸菜坑了这么多年,还是记录下吧,或许以后某天不搞 .net,回去折腾 C 语言了. 写法1: ...