搭建互联网架构学习--006--duboo准备之zk集群部署安装
dubbo集群部署安装依赖于zookeeper,所以先安装zookeeper集群。
1、准备三台机器做集群

2、配置
配置java环境 ,2,修改操作系统的/etc/hosts文件,添加IP与主机名映射:
具体看这里 http://www.cnblogs.com/lihaoyang/p/8341760.html
2.下载zookeeper-3.4.10.tar.gz 到/data/program/software/目录, 在网上下载或者
# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz (这个是3.4.9的)
3.4.10百度网盘下载链接:https://pan.baidu.com/s/1jJiERBo 密码:a4c6
解压zookeeper安装包,并对节点重命名
#tar -zxvf zookeeper-3.4.10.tar.gz
服务器1:
#mv zookeeper-3.4.10 zookeeper
服务器2:
#mv zookeeper-3.4.10 zookeeper
服务器3:
#mv zookeeper-3.4.10 zookeeper
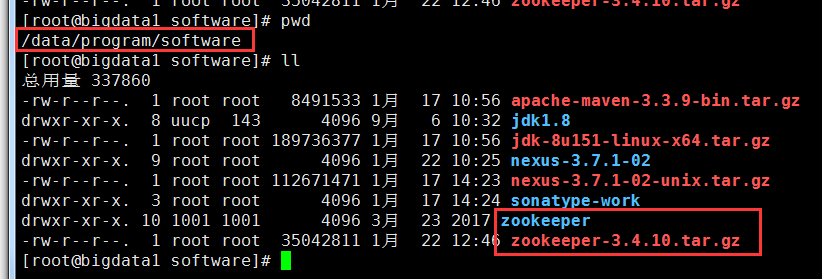
3, 在zookeeper的各个节点下 创建数据和日志目录
#cd zookeeper
#mkdir data
#mkdir logs
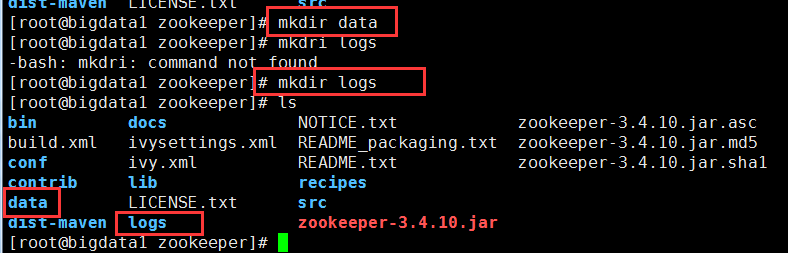
4,重命名配置文件
将zookeeper/conf目录下的zoo_sample.cfg文件拷贝一份,命名为zoo.cfg:
#cp zoo_sample.cfg zoo.cfg
vim 修改zoo.cfg 配置文件,修改如下几处,保存
clientPort=2181
dataDir=/data/program/software/zookeeper/data
dataLogDir=/data/program/software/zookeeper/logs
server.1=bigdata1:2881:3881
server.2=bigdata2:2881:3881
server.3=bigdata3:2881:3881
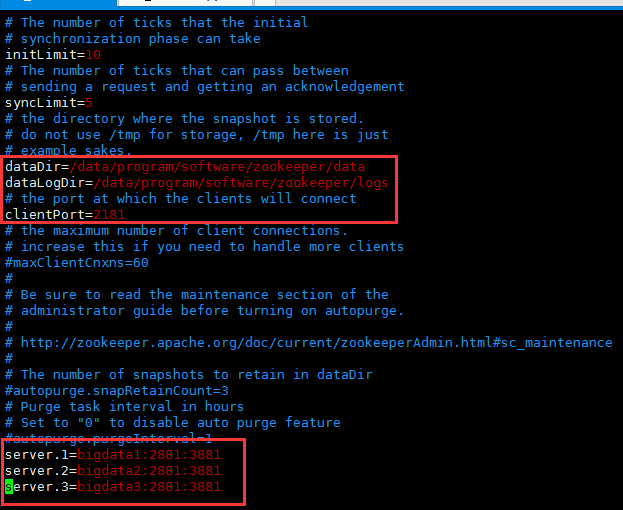
zoo.cfg说明:
[root@bigdata1 conf]# cat zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/program/software/zookeeper/data
dataLogDir=/data/program/software/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=bigdata1:2881:3881
server.2=bigdata2:2881:3881
server.3=bigdata3:2881:3881
参数说明:
tickTime=2000
tickTime这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个
tickTime时间就会发送一个心跳。
initLimit=10
initLimit这个配置项是用来配置Zookeeper接受客户端(这里所说的客户端不是用户连接Zookeeper服务
器的客户端,而是Zookeeper服务器集群中连接到Leader的Follower 服务器)初始化连接时最长能忍受多
少个心跳时间间隔数。当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper 服务器还没有
收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
syncLimit=5
syncLimit这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个
tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir=/data/program/software/zookeeper/data
dataDir顾名思义就是Zookeeper保存数据的目录,默认情况下Zookeeper将写数据的日志文件也保存在这
个目录里。
clientPort=2181
clientPort这个端口就是客户端(应用程序)连接Zookeeper服务器的端口,Zookeeper会监听这个端口接
受客户端的访问请求。
server.A=B:C:D
server.1=bigdata1:2881:3881
server.2=bigdata2:2881:3881
server.3=bigdata3:2881:3881
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址(或者是与IP地址做了映射的主机名);
C此端口表示,用来集群成员的信息交换,表示这个服务器与集群中的Leader服务器交换信息的端口;
D是在leader挂掉时专门用来进行选举leader所用的端口。
注意:如果是伪集群的配置方式,不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同
的端口号。
5,创建myid文件
在 dataDir=/data/program/software/zookeeper/data 下创建myid文件
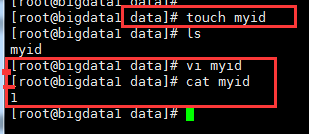
编辑myid文件,并在对应的IP的机器上输入对应的编号。如在1上,myid文件内容就是1, 2上就是2, 3上就是3:
bigdata1 #vi /myid## 值为1
bigdata2 #vi /myid## 值为2
bigdata3 #vi /myid## 值为3
bigdata1 192.168.75.3 的配置就配置完了,bigdata2 、bigdata3也照着配置。
6,启动测试zookeeper
(1)进入/bin目录下执行:
# ./zkServer.sh start
bigdata1:

bggdata2:

bigdata3:

(2)输入jps命令查看进程:
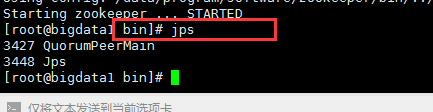
其中,QuorumPeerMain是zookeeper进程,说明启动正常
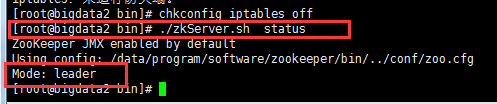
(3)查看状态:
# ./zkServer.sh status

发现报错,百度一下,原来是bigdata2和闭关data3防火墙开着呢, 使用service iptables stop 关闭防火墙,使用service iptables status确认,避免下次开机防火墙自启动。 使用chkconfig iptables off禁用防火墙
使用 ./zkServer.sh stop 以此关闭三个zk,./zkServer.sh start 以此启动 bigdata1、bigdata2、bigdata3
# ./zkServer.sh status 查看状态:
bigdata1: 是一个follower

bigdata2:
bigdata3:
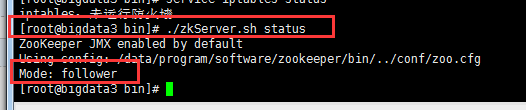
(4)查看zookeeper服务输出信息:
由于服务信息输出文件在/bin/zookeeper.out
$ tail -500 f zookeeper.out
(我们的日志都存在了zookeeper/logs目录,所以在logs里查看)
·
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
PS1:环境变量:
可以在 etc/profile下设置zk环境变量,就可以不进入zk安装目录就能执行zk命令了:
用 vim 打开 /etc/ 目录下的配置文件 profile:
vim /etc/profile
并在其尾部追加如下内容:
export ZOOKEEPER_HOME=/xxxx/zookeeper --你的zk安装路径
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export PATH
修改完 etc/profile 后刷新生效: source /etc/profile
PS2:软件安装位置
我看一般安装软件都安装在了/usr/local下 ,Linux软件安装目录区别,本文是按照教程安装的,感觉不太合理。
Linux 的软件安装目录是也是有讲究的,理解这一点,在对系统管理是有益的
/usr:系统级的目录,可以理解为C:/Windows/,/usr/lib理解为C:/Windows/System32。/usr/local:用户级的程序目录,可以理解为C:/Progrem Files/。用户自己编译的软件默认会安装到这个目录下。/opt:用户级的程序目录,可以理解为D:/Software,opt有可选的意思,这里可以用于放置第三方大型软件(或游戏),当你不需要时,直接rm -rf掉即可。在硬盘容量不够时,也可将/opt单独挂载到其他磁盘上使用。
搭建互联网架构学习--006--duboo准备之zk集群部署安装的更多相关文章
- zookeeper学习与实战(二)集群部署
上一篇介绍了单机版zookeeper安装,这种情况一般用于开发测试.如果是生产环境建议用分布式集群部署,防止单点故障,增加zookeeper服务的高可用. [环境介绍] 三台机器:192. ...
- 搭建互联网架构学习--005--框架初步拆分ssm单一框架
经过前边的准备步骤,服务器基本搭建完毕,接下来就开始一步步搭建框架了. 拆分单一结构:拆分的目的是为下一步引入dubbo做准备的. 把下边这个单一maven框架进行拆分 这个就是一个简单的maven项 ...
- 搭建互联网架构学习--004--centos安装Mysql
Mysql安装 1. yum安装mysql yum -y install mysql-server 2. 启动mysql服务 启动mysql:service mysqld start 查看mysql的 ...
- 搭建互联网架构学习--003--maven以及nexus私服搭建
跳过,等待完善中,,, 后台服务工具maven:使用Nexus配置Maven私有仓库 一.安装配置Nexus 1. 下载nexus https://www.sonatype.com/download- ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- 基于 kubeadm 搭建高可用的kubernetes 1.18.2 (k8s)集群 部署 dashboard 2.x
1. 部署dashboard 2.x版本 Dashboard 分为 1.x版本 和 2.x版本, k8s 使用的是1.18.2 故部署2.x版本的 # dashboard 2.x版本的部署 # 上传d ...
- 【Redis学习专题】- Redis主从+哨兵集群部署
集群版本: redis-4.0.14 集群节点: 节点角色 IP redis-master 10.100.8.21 redis-slave1 10.100.8.22 redis-slave2 10.1 ...
- RocketMQ学习笔记(16)----RocketMQ搭建双主双从(异步复制)集群
1. 修改RocketMQ默认启动端口 由于只有两台机器,部署双主双从需要四个节点,所以只能修改rocketmq的默认启动端口,从官网下载rocketmq的source文件,解压后使用idea打开,全 ...
- 一脸懵逼学习KafKa集群的安装搭建--(一种高吞吐量的分布式发布订阅消息系统)
kafka的前言知识: :Kafka是什么? 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算.kafka是一个生产-消费模型. Producer:生产者,只负责数 ...
随机推荐
- noexcept(c++11)
1.概念 1)c++中的异常处理是在运行时而不是编译时检测的,为了实现运行时检测,编译器可能会创建额外的异常处理代码,然而这会妨碍程序优化 2)noexcept说明符:若修饰函数(紧跟在参数列表后面) ...
- (并查集 贪心思想)Supermarket -- POJ --1456
链接: http://poj.org/problem?id=1456 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=82830#probl ...
- nodejs express hi-cms
今天看一下hi-cm是怎么写的,理解一下流程,看一些亮点 它使用express3.x写的 1.app.set, app.get app.set('port', 3000); app.get('port ...
- web问题
模拟form提交过程中form(hidden)时:The frame requesting access has a protocol of "http", the frame b ...
- linux几种查看日志的方法
linux tail命令用途是依照要求将指定的文件的最后部分输出到标准设备,通常是终端,通俗讲来,就是把某个档案文件的最后几行显示到终端上,假设该档案有更新,tail会自己主动刷新,确保你看到最新的档 ...
- kafka不停止服务的情况下修改日志保留时间
kafka配置文件如下: broker.id=1 port=9092 host.name=ssy-kafka1 num.network.threads=4 num.io.threads=8 socke ...
- mod_pagespeed
https://github.com/pagespeed/mod_pagespeed.git https://developers.google.com/speed/pagespeed/module/ ...
- LinqToHubble介绍及简单使用步骤——LinqToHubble是对HubbleDotnet的封装
或许你还你知道HubbleDotnet,下面简单对HubbleDotnet坐下介绍. HubbleDotNet是由盘古分词作者——eaglet 开发的一个基于.net framework 的开源免费的 ...
- Postgresql 創建觸發器,刪除觸發器和 禁用觸發器
CREATE OR REPLACE FUNCTION XF_VIP_AFUPD_WX() RETURNS trigger AS $$ DECLARE i_count integer; s_wx_ope ...
- Alwayson--与复制的影响
在主副本上建立复制后,复制的事务日志读取代理(log reader)不会读取尚未同步到辅助副本的日志,因为辅助副本可能在下一时刻转化成为主副本,变为新的复制发布服务器,为此需要保证复制处理的日志总慢于 ...