Java 容器 LinkedHashMap源码分析2
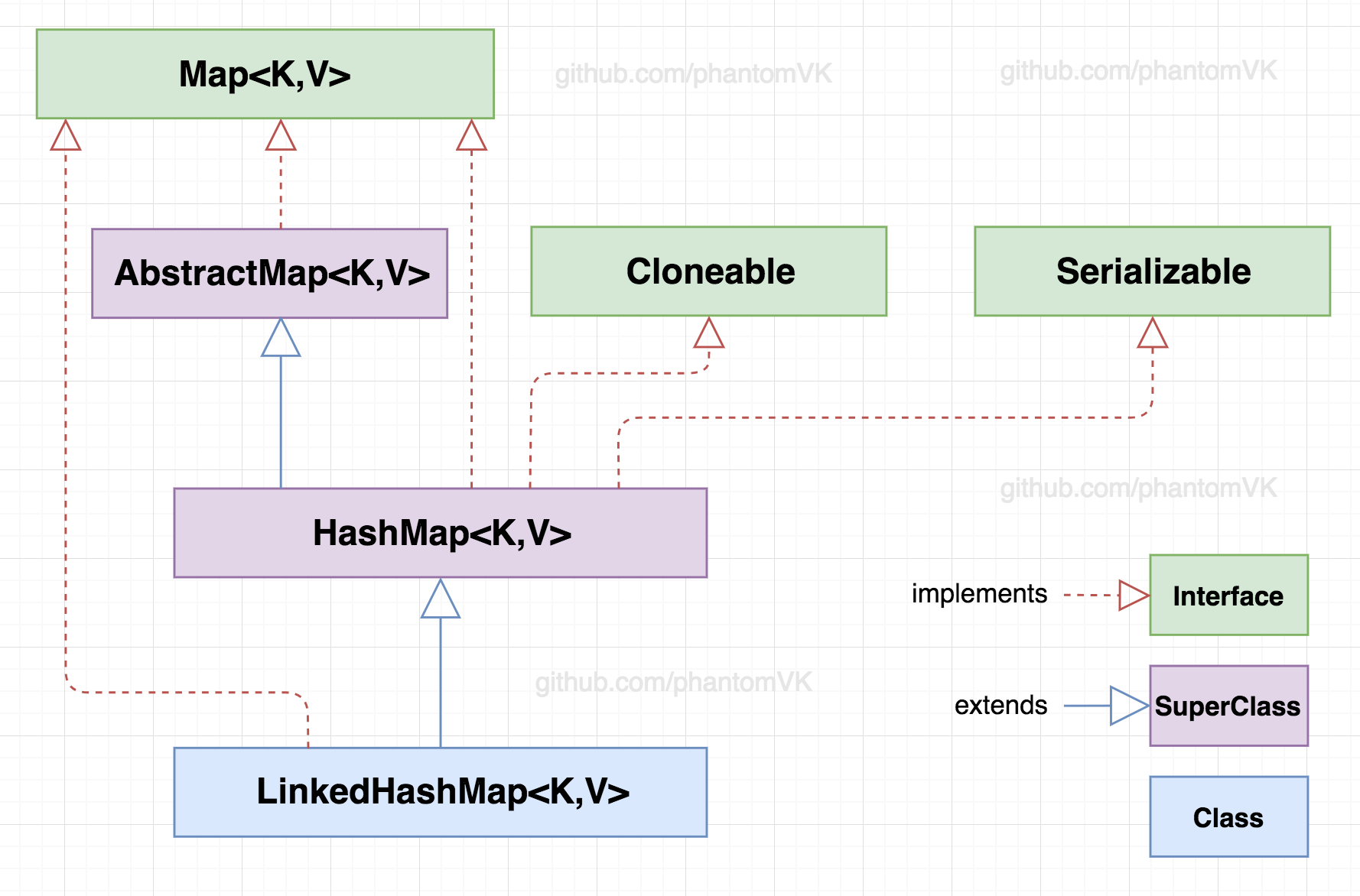
一、类签名
LinkedHashMap<K,V>继承自HashMap<K,V>,可知存入的节点key永远是唯一的。可以通过Android的LruCache了解LinkedHashMap用法。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
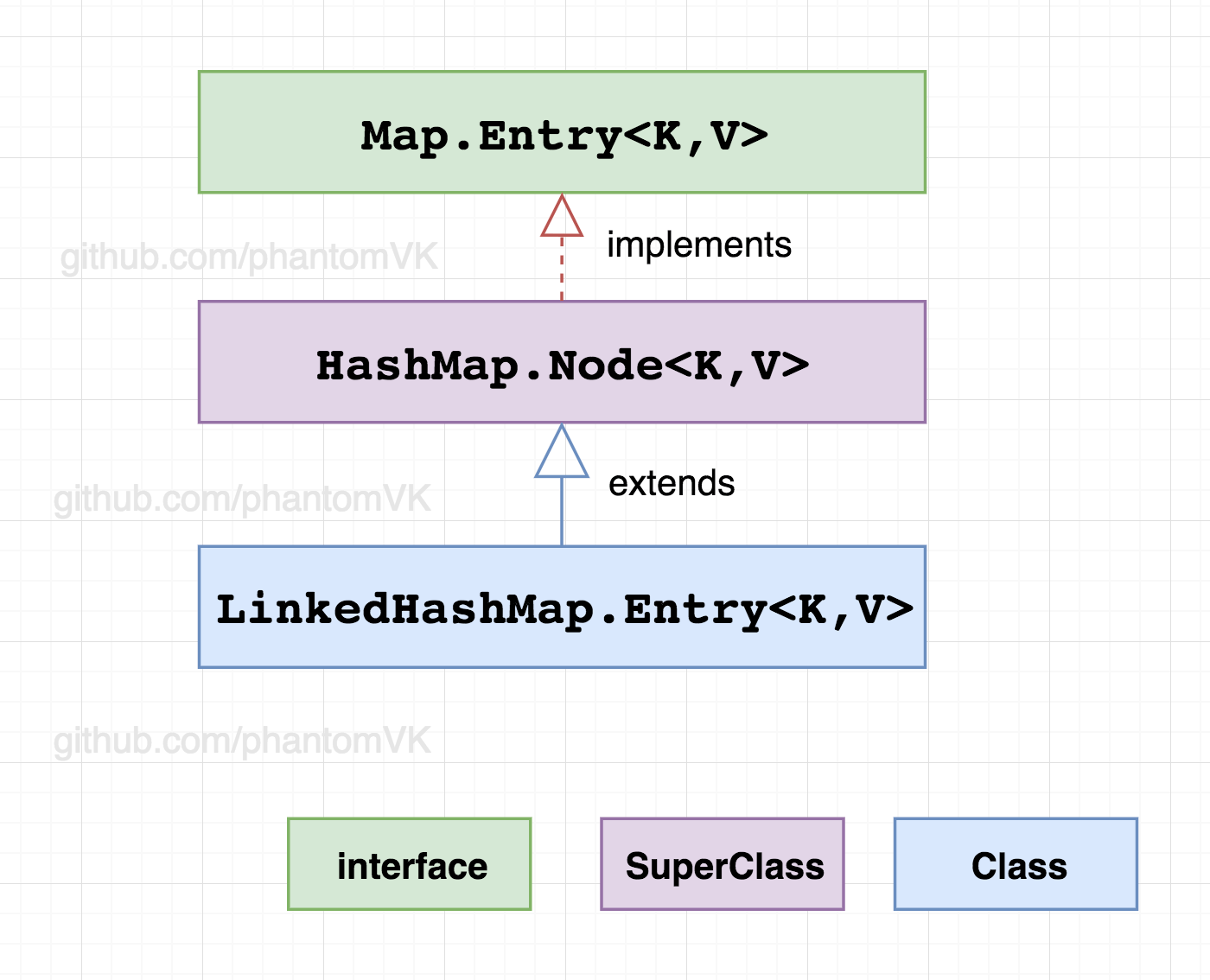
二、节点
Entry<K,V>是HashMap.Node<K,V>的子类,增加before、after引用实现双向链表
static class Entry<K,V> extends HashMap.Node<K,V> {
// 前节点、后节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
// 调用HashMap构造方法
super(hash, key, value, next);
}
}
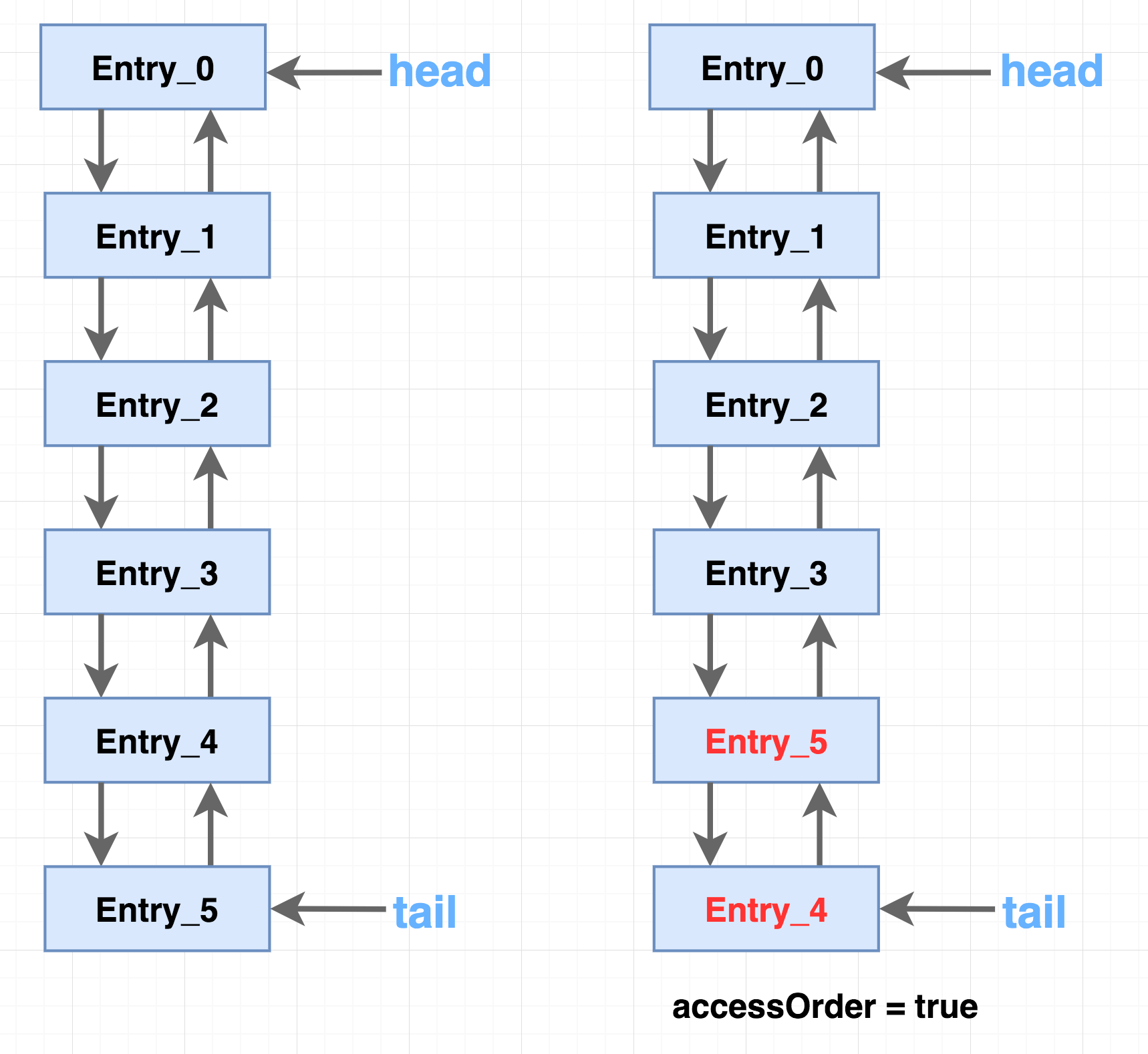
三、数据成员
双向链表头,指向最早(最老)访问节点元素
transient LinkedHashMap.Entry<K,V> head;
双向链表尾,指向最近(最晚)访问节点元素
transient LinkedHashMap.Entry<K,V> tail;
是否保持访问顺序,为true则每次被访问的节点都会放到链表尾部
final boolean accessOrder;
依次插入Entry_0到Entry_5,当accessOrder为true并访问Entry_4时,Entry_4会被移到链尾
四、构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 维持存取顺序仅能通过此构造方法
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
五、成员方法
// 把节点插入到链表尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// 如果尾节点为空表明链表没有元素,则p就是头结点
if (last == null)
head = p;
else {
// 处理双向链表节点
p.before = last;
last.after = p;
}
} // apply src's links to dst
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
} // 重写HashMap钩子方法
void reinitialize() {
super.reinitialize();
head = tail = null;
} // 创建新链表节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
} // 替换链表节点
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
} // 创建新红黑树节点
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<>(hash, key, value, next);
linkNodeLast(p);
return p;
} // 替换红黑树节点
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
六、顺序操作
// 把节点从链表解除链接
void afterNodeRemoval(Node<K,V> e) {
// p:即是节点e
// b:e的前一个节点
// a:e的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 置空节点p的前后引用
p.before = p.after = null; if (b == null) {
// 可知节点e是链表头结点,则e的下一个节点a作为链表的头结点
head = a;
} else {
// 可知节点e本是中间结点,把e下一个节点a作为e上一个节点的后续节点
b.after = a;
} if (a == null) {
// 可知节点e本是链表尾节点,则e的上一个节点b作为链表的尾节点
tail = b;
} else {
// 可知节点e本身是中间节点,把e上一个节点b作为e下一个节点的前置节点
a.before = b;
}
} // 父类HashMap调用putVal()中会调用此方法,移除最少使用的节点
void afterNodeInsertion(boolean evict) {
// first是最少使用的节点
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
// 获取first的key
K key = first.key;
// 通过key找到对应Node并移除
removeNode(hash(key), key, null, false, true);
}
} // 把节点移动到链表尾
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
// 仅当accessOrder为true且被访问元素不是尾节点
if (accessOrder && (last = tail) != e) {
// p:即是节点e
// b:e的前一个节点
// a:e的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 置空节点p的后引用
p.after = null; if (b == null) {
// 可知节点e本是头结点,则e的下一个节点a作为链表的头结点
head = a;
} else {
// 可知节点e本是中间结点,把e下一个节点a作为e上一个节点的后续节点
b.after = a;
} if (a != null) {
// 可知节点e本身是中间节点,把e上一个节点b作为e下一个节点的前置节点
a.before = b;
} else {
// 可知节点e本是尾节点,则e的上一个节点b作为链表的尾节点
last = b;
} // p之前没有节点,表明p就是头结点
if (last == null) {
head = p;
} else {
// p作为新的尾节点,链接到上一个尾节点之后
p.before = last;
last.after = p;
} tail = p; // tail引用指向p
++modCount; // 修改次数递增
}
}
七、获取
// 检查LinkedHashMap是否包含指定value
public boolean containsValue(Object value) {
// 从链表头结点开始遍历,逐个查找Entry.value是否等于value
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true; // 包含对应value,返回true
}
return false; // 不包含对应value,返回false
} // 通过Key获取对应Entry的value
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null) {
// 通过key获取Node为空,返回null作为结果
return null;
} if (accessOrder) {
// 通过key获取Node不为空,执行afterNodeAccess(e)调整顺序
afterNodeAccess(e);
} return e.value; // 最后把获取的Entry.value返回
} // 通过Key获取对应Entry的value
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null) {
// 通过key获取Node为空,返回defaultValue作为结果
return defaultValue;
} if (accessOrder) {
// 通过key获取Node不为空,执行afterNodeAccess(e)调整顺序
afterNodeAccess(e);
} return e.value; // 最后把获取的Entry.value返回
}
八、移除
// 清除所有引用
public void clear() {
super.clear(); // 把HashMap所有Entry都清空
head = tail = null; // 置空head和tail引用
} // 方法主要用于被子类重写,决定最少使用的节点能否被移除
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
Java 容器 LinkedHashMap源码分析2的更多相关文章
- Java 容器 LinkedHashMap源码分析1
同 HashMap 一样,LinkedHashMap 也是对 Map 接口的一种基于链表和哈希表的实现.实际上, LinkedHashMap 是 HashMap 的子类,其扩展了 HashMap 增加 ...
- Java容器 | 基于源码分析List集合体系
一.容器之List集合 List集合体系应该是日常开发中最常用的API,而且通常是作为面试压轴问题(JVM.集合.并发),集合这块代码的整体设计也是融合很多编程思想,对于程序员来说具有很高的参考和借鉴 ...
- Java容器 | 基于源码分析Map集合体系
一.容器之Map集合 集合体系的源码中,Map中的HashMap的设计堪称最经典,涉及数据结构.编程思想.哈希计算等等,在日常开发中对于一些源码的思想进行参考借鉴还是很有必要的. 基础:元素增查删.容 ...
- Java split方法源码分析
Java split方法源码分析 public String[] split(CharSequence input [, int limit]) { int index = 0; // 指针 bool ...
- 【JAVA】ThreadLocal源码分析
ThreadLocal内部是用一张哈希表来存储: static class ThreadLocalMap { static class Entry extends WeakReference<T ...
- 【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:put()get()**resize()** 首先介绍resize()这个方法,在我看来这是HashMap中一个非常 ...
- 【Java】HashMap源码分析——基本概念
在JDK1.8后,对HashMap源码进行了更改,引入了红黑树.在这之前,HashMap实际上就是就是数组+链表的结构,由于HashMap是一张哈希表,其会产生哈希冲突,为了解决哈希冲突,HashMa ...
- 细说并发5:Java 阻塞队列源码分析(下)
上一篇 细说并发4:Java 阻塞队列源码分析(上) 我们了解了 ArrayBlockingQueue, LinkedBlockingQueue 和 PriorityBlockingQueue,这篇文 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
随机推荐
- URLconf
URLconf 浏览者通过在浏览器的地址栏中输入网址请求网站,对于Django开发的网站,由哪一个视图进行处理请求,是由url匹配找到的 配置 在test3/settings.py中通过ROOT_UR ...
- jenkins systemctl启动失败
centos yum或者rpm安装jenkins后起不来 vi /etc/init.d/jenkins candidates="/usr/local/jdk1.8.0_171/bin/jav ...
- Python 遍历文件夹 listdir walk 的区别
一.一级目录import os path = 'd:\file'; for filename in os.listdir(path): print(os.path.join(path,filename ...
- IDEA 码云 安装
安装方式: 从IDEA插件仓库搜索Gitee下载并安装即可. 登陆并拉取项目代码 1. 启动 idea,选择Check out from Version Control-码云 2. 输入用户名和密码, ...
- hdoj1003 DP
Max Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- Unity 5.1+ Assertion Library (断言库)
Unity 5.1+ ,加入了“断言库”,在 Asset 类中可以方便的找到需要使用断言的函数. UnityEngine.Assertions.Assert.IsNotNull( ) 为何使用断言 使 ...
- ADF 入门帮助
本文是由英文帮助翻译所得: 1>task flows “任务流 task flows”可以包括非可视化的组件,比如方法调用.“页片段 page fragment”可以运行在一个页面的某个局部区域 ...
- 使用jdbc编程实现对数据库的操作以及jdbc问题总结
1.创建数据库名为mybatis. 2. 在数据库中建立两张表,user与orders表: (1)user表: (2)orders表: 3.创建工程 * 开发环境: * eclipse mars * ...
- 禁用xampp的ssl功能
按照Disable SSL on XAMPP for Windows文章里讲解的步骤如下: 1 以管理员身份启动XAMPP控制面板,点击Config按钮打开httpd.conf 分别注释171,539 ...
- Judy Array API介绍
本文介绍https://code.google.com/p/judyarray/这个JudyArray实现的API. judy_open:新建一个JudyArray,并返回指向这个JudyArray的 ...