【Coursera】经验风险最小化
一、经验风险最小化
1、有限假设类情形
- 对于Chernoff bound 不等式,最直观的解释就是利用高斯分布的图象。而且这个结论和中心极限定律没有关系,当m为任意值时Chernoff bound均成立,但是中心极限定律不一定成立。
- 随着模型复杂度(如多项式的次数、假设类的大小等)的增长,训练误差逐渐降低,而一般误差先降低到最低点再重新增长。训练误差降低,是因为模型越复杂,对于训练集合的拟合就越好。对于一般误差,最左边的端点表示欠拟合(高偏差),最右边的端点表示过拟合(高方差),最小化一般误差时,一般倾向于选取中间的模型复杂度,最小一般误差的区域。
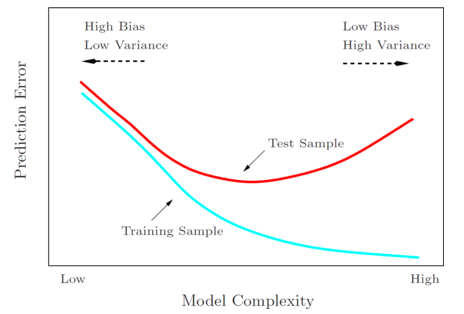
- 经验风险最小化中,
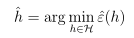 这个得到的函数具有最小的训练误差,但是如上图所示,并不具有最小的一般误差。
这个得到的函数具有最小的训练误差,但是如上图所示,并不具有最小的一般误差。
2、无限假设类情形
- VC维:只要存在大小为d的集合可以被某个假设空间分散,那么这个假设的VC维就是d。
在经验风险最小化中,最终的目的就是确定模型所需样本数的界限,这个界限是宽松的,这也是为什么在界限的表达时通常使用O这个符号来表示的原因。此外,这个界限对于符合任何分布的数据均成立,即使在最坏的情形下也是成立。但是在实际应用中,无法直接通过这个界限来确定我们所需的样本数量,因为在实际问题中,我们所研究的某个问题往往服从特定的分布,并不像最坏的情形那样糟糕,若直接将参数代入求解m的界,往往会得到非常大的m的值。
三、模型选择
1、保留交叉验证法
- 通常只利用了70%左右的数据,造成了浪费
2、K折交叉验证法
- 每个模型都需要训练K次,需要大量的计算
3、留一交叉验证法
- m = k,即每次只留下一个样本作为测试数据
- 能够更充分得利用数据,但是计算量更大
- 当数据非常少时才适用
四、特征选择
1、前向查找和反向查找
- 这两种算法是一种启发式搜索算法,并不保证一定能找到最优的特征集。
- 在文本分类问题中,特征向量往往非常大,一般是几万的量级,此时选用这两种算法不大合适,因为所需要的计算量太大了。
2、过滤特征选择
- 通过计算为每个特征向量\(x_{i}\)计算其对结果y的贡献值,然后选择贡献值最大的k个特征。
- 如何决定k取多少?一个方法是通过交叉验证,不停选择前一个特征、前两个特征、前三个特征等等,以此来决定要选择几个特征值。
五、贝叶斯统计和规则化
- 频率派:将参数\(\theta\)视为未知的常量,并采用最大似然估计法去求解。
- 贝叶斯学派:将参数\(\theta\)视为未知的随机变量。
- 贝叶斯统计和规则化,就是找出新的估计方法来代替原有的最大似然估计法,来减少过拟合的发生。
【Coursera】经验风险最小化的更多相关文章
- svm、经验风险最小化、vc维
原文:http://blog.csdn.net/keith0812/article/details/8901113 “支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上” 结构化 ...
- 机器学习 之 SVM VC维度、样本数目与经验风险最小化的关系
VC维在有限的训练样本情况下,当样本数 n 固定时.此时学习机器的 VC 维越高学习机器的复杂性越高. VC 维反映了函数集的学习能力,VC 维越大则学习机器越复杂(容量越大). 所谓的结构风险最小化 ...
- 【cs229-Lecture9】经验风险最小化
写在前面:机器学习的目标是从训练集中得到一个模型,使之能对测试集进行分类,这里,训练集和测试集都是分布D的样本.而我们会设定一个训练误差来表示测试集的拟合程度(训练误差),虽然训练误差具有一定的参考价 ...
- 机器学习理论基础学习3.3--- Linear classification 线性分类之logistic regression(基于经验风险最小化)
一.逻辑回归是什么? 1.逻辑回归 逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的. logistic回归也称为逻辑回归,与线性回归这样输出 ...
- 第九集 经验风险最小化(ERM)
实在写不动了,将word文档转换为PDF直接截图了... 版权声明:本文为博主原创文章,未经博主允许不得转载.
- 【转载】VC维,结构风险最小化
以下文章转载自http://blog.sina.com.cn/s/blog_7103b28a0102w9tr.html 如有侵权,请留言,立即删除. 1 VC维的描述和理解 给定一个集合S={x1,x ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- 使用经验风险最小化ERM方法来估计模型误差 开坑
虽然已经学习了许多机器学习的方法,可只有我们必须知道何时何处使用哪种方法,才能将他们正确运用起来. 那不妨使用经验最小化ERM方法来估计 . 首先: 其中, δ代表训练出错的概率 k代表假设类的个数 ...
随机推荐
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- VB6 Access 事务(Transaction)
VB6 Access 事务 On Error GoTo err_trans intTrans = conn.BeginTrans '开始事务 X = count For i = 0 To X sql= ...
- Entity Framework 多对多查询的写法
同学们,看下面的代码段就明白了: 一对多: public ICollection<ReportLookup> GetReportLookup(IEnumerable<Guid> ...
- 22-[jQuery]-选择器, js jQuery对象转换
1.基础选择器 <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
- P5231 [JSOI2012]玄武密码
P5231 [JSOI2012]玄武密码 链接 分析: 首先对所有询问串建立AC自动机,然后扫描一遍母串,在AC自动机上走,没走到一个点,标记这个点走过了,并且它的fail树上的祖先节点也可以访问到( ...
- 深度学习—caffe框架训练文档
转存:LMDB E:\机器学习2\caffe资料\caffe_root\caffe-master\Build\x64\Release>convert_imageset.exe E:/机器学习2/ ...
- ubuntu 图形化界面 gui 桌面版 root登录 sorry,that didn't work.please try again! 抱歉,认证失败。请重试
出现这种问题,用下面的方法就行了 https://jingyan.baidu.com/article/bad08e1e224b2709c85121f1.html 而且我发现,因为我用的是英文版的ubu ...
- Zabbix实战-简易教程--业务类
一.需求 项目要求对线上服务器进行监控,包括服务器本身状态.进程相关数据.业务相关数据. 服务器本身状态可以通过基础模板即可获取数据(CPU.内存.网络.磁盘): 进程相关数据,前面也有相关文章专门监 ...
- $(document)和$(window)各是什么意思?
jquery中的对象$(document) 是当前文档,就是你看到的整个网页$(window) 如果没有框架则就是你浏览的当前浏览器的窗口 将document, window转换为jquery对象 比 ...
- C++构造函数深度探究
1.引子: 以下代码中的输出语句输出0吗,为什么? struct Test { int _a; Test(int a) : _a(a) {} Test() { Test(0); } }; Test o ...