stateful openflow------整理openstate原理以及具体应用
论文中以端口锁定为例,提出了米粒型状态机在交换机内部的应用从而可以大大减少交换机和控制器之间的交互,减缓了控制器的性能瓶颈。
传统SDN架构,对一些安全应用如端口锁定,只有一定顺序的端口请求才会开放目标端口,如请求22端口进行数据传输,但设置的端口请求列表是[10,12,13,14,22],就是说只有在之前目标主机依次收到这些端口请求后才会开放22号端口。这个策略如果需要由控制器来完成,将会十分繁琐,每次来一个数据包请求控制器,控制器根据历史端口生成处理策略。
论文中指出,SDN的最大优势就是全局能力,而这样的操作完全是本交换机自己的事情,交给控制器处理并没有获得控制器的优势,反而增加了控制器的处理负担。因此提出了交换机内部可以维持一个状态机。
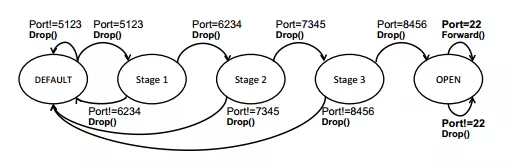
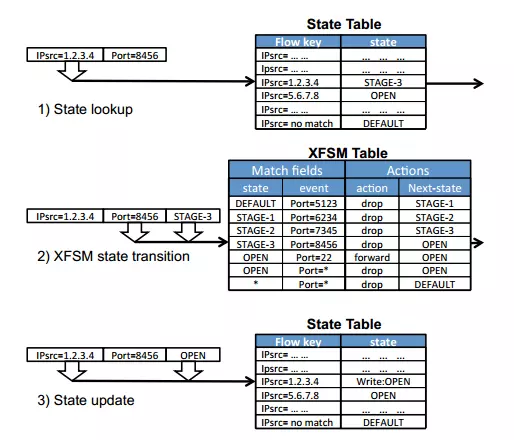
要在交换机中实现上述状态转移功能,交换机需要维持两张表,状态表和流表,流表在原来的基础上进行了扩充,增加了state的查询。具体如下:

知识补充:lookup 和 update
lookup和update是交换机实现的功能,由lookup extractor和update extractor两个功能模块完成,在交换机中实现。两个功能模块作用就是在数据包中取出唯一标识符,可以由控制器自定义。当数据包进入交换机时,调用lookup extractor,比如以源IP为标识符,则为这条数据流生成了以IP地址为标识的唯一标识符。交换机根据这条标识去state table中查找对应的状态,并以该状态和其他匹配字段去查询流表,最终完成了整个功能实现。
端口锁定的实现程序:
LOG = logging.getLogger('app.openstate.portknock')
""" Last port is the one to be opened after knocking all the others """
port_list = [, , , , ]
final_port = port_list[-]
second_last_port = port_list[-]
LOG.info("Port knock sequence is %s" % port_list[:-])
LOG.info("Final port to open is %s" % port_list[-])
class OpenStatePortKnocking(app_manager.RyuApp):
def __init__(self, *args, **kwargs):
super(OpenStatePortKnocking, self).__init__(*args, **kwargs)
@set_ev_cls(ofp_event.EventOFPSwitchFeatures, CONFIG_DISPATCHER)
def switch_features_handler(self, ev):
msg = ev.msg
datapath = msg.datapath
LOG.info("Configuring switch %d..." % datapath.id)
""" Set table 0 as stateful """
req = osparser.OFPExpMsgConfigureStatefulTable(datapath=datapath,
table_id=,
stateful=)
datapath.send_msg(req)
""" Set lookup extractor = {ip_src} """
req = osparser.OFPExpMsgKeyExtract(datapath=datapath,
command=osproto.OFPSC_EXP_SET_L_EXTRACTOR,
fields=[ofproto.OXM_OF_IPV4_SRC],
table_id=)
datapath.send_msg(req)
""" Set update extractor = {ip_src} (same as lookup) """
req = osparser.OFPExpMsgKeyExtract(datapath=datapath,
command=osproto.OFPSC_EXP_SET_U_EXTRACTOR,
fields=[ofproto.OXM_OF_IPV4_SRC],
table_id=)
datapath.send_msg(req)
""" ARP packets flooding """
match = ofparser.OFPMatch(eth_type=0x0806)
actions = [ofparser.OFPActionOutput(ofproto.OFPP_FLOOD)]
self.add_flow(datapath=datapath, table_id=, priority=,
match=match, actions=actions)
# 提前下发状态表
""" Flow entries for port knocking """
for i in range(len(port_list)):
match = ofparser.OFPMatch(eth_type=0x0800, ip_proto=,
state=i, udp_dst=port_list[i])
if port_list[i] != final_port and port_list[i] != second_last_port:
# If state not OPEN, set state and drop (implicit)
actions = [osparser.OFPExpActionSetState(state=i+, table_id=, idle_timeout=)]
elif port_list[i] == second_last_port:
# In the transaction to the OPEN state, the timeout is set to sec
actions = [osparser.OFPExpActionSetState(state=i+, table_id=, idle_timeout=)]
else:
actions = [ofparser.OFPActionOutput()]
self.add_flow(datapath=datapath, table_id=, priority=,
match=match, actions=actions)
""" Get back to DEFAULT if wrong knock (UDP match, lowest priority) """
match = ofparser.OFPMatch(eth_type=0x0800, ip_proto=)
actions = [osparser.OFPExpActionSetState(state=, table_id=)]
self.add_flow(datapath=datapath, table_id=, priority=,
match=match, actions=actions)
""" Test port 1300, always forward on port 2 """
match = ofparser.OFPMatch(eth_type=0x0800, ip_proto=, udp_dst=)
actions = [ofparser.OFPActionOutput()]
self.add_flow(datapath=datapath, table_id=, priority=,
match=match, actions=actions)
def add_flow(self, datapath, table_id, priority, match, actions):
inst = [ofparser.OFPInstructionActions(
ofproto.OFPIT_APPLY_ACTIONS, actions)]
mod = ofparser.OFPFlowMod(datapath=datapath, table_id=table_id,
priority=priority, match=match, instructions=inst)
datapath.send_msg(mod)
数据流状态的转移是根据已经存在的状态表来进行查询和更新的,对一条数据流,先进行状态查询,
如果符合match = ofparser.OFPMatch(eth_type=0x0800, ip_proto=17, state=i, udp_dst=port_list[i])则会执行相应的动作,actions = [osparser.OFPExpActionSetState(state=i+1, table_id=0, idle_timeout=5)]
(已经提前下发),所以整个的重点就是状态表的建立(对每条数据流建立一个状态表)和更新以及带状态的流表的查询。
class OpenStateMacLearning(app_manager.RyuApp):
def __init__(self, *args, **kwargs):
super(OpenStateMacLearning, self).__init__(*args, **kwargs) def add_flow(self, datapath, table_id, priority, match, actions):
if len(actions) > :
inst = [ofparser.OFPInstructionActions(
ofproto.OFPIT_APPLY_ACTIONS, actions)]
else:
inst = []
mod = ofparser.OFPFlowMod(datapath=datapath, table_id=table_id,
priority=priority, match=match, instructions=inst)
datapath.send_msg(mod) @set_ev_cls(ofp_event.EventOFPSwitchFeatures, CONFIG_DISPATCHER)
def switch_features_handler(self, event): """ Switche sent his features, check if OpenState supported """
msg = event.msg
datapath = msg.datapath LOG.info("Configuring switch %d..." % datapath.id) """ Set table 0 as stateful """
req = osparser.OFPExpMsgConfigureStatefulTable(
datapath=datapath,
table_id=,
stateful=)
datapath.send_msg(req) """ Set lookup extractor = {eth_dst} """
req = osparser.OFPExpMsgKeyExtract(datapath=datapath,
command=osproto.OFPSC_EXP_SET_L_EXTRACTOR,
fields=[ofproto.OXM_OF_ETH_DST],
table_id=)
datapath.send_msg(req) """ Set update extractor = {eth_src} """
req = osparser.OFPExpMsgKeyExtract(datapath=datapath,
command=osproto.OFPSC_EXP_SET_U_EXTRACTOR,
fields=[ofproto.OXM_OF_ETH_SRC],
table_id=)
datapath.send_msg(req) # for each input port, for each state
for i in range(, N+):
for s in range(N+):
match = ofparser.OFPMatch(in_port=i, state=s)
if s == :
out_port = ofproto.OFPP_FLOOD
else:
out_port = s
actions = [osparser.OFPExpActionSetState(state=i, table_id=, hard_timeout=),
ofparser.OFPActionOutput(out_port)]
self.add_flow(datapath=datapath, table_id=, priority=,
match=match, actions=actions)
上面是用来进行端口学习的,乍看还是有点难懂。他最大的好处就是不用和控制器进行交互,提前预下发流表,然后在交换机内部根据状态信息进行学习。
重要的还是对状态表的查询和更新的理解。对每一条流有一个状态,流进入交换机会进行查询操作,查询字段为目的地址;查询到相应状态并进行匹配流表和实施action后,会进行更新操作,更新字段是源地址,也就是说对到来的数据会记录其IP与端口号(用状态表示)。
主要思想如下:
第一步:给所有的(假设n个)端口下发n+1个带状态的流表。如4口交换机则端口1就有生成5个匹配流表,匹配项为入端口号和state值,action为outport,出端口值就是非0的state值,state为0表示泛洪。
但交换机又是如何学习的呢,一条数据流进入,首先通过lookup查询当前流的状态,当没有学习到目的地址时,state值还是为0,泛洪。同时,因为update以源MAC地址更新,匹配到流表后会取出源MAC地址,更新state为进端口号,osparser.OFPExpActionSetState(state=i, table_id=0, hard_timeout=10)
所以下次当有该目的MAC地址来世,查询到的state也就是出端口号。设计的有点反常识,但还是证明stateful 数据平面确实是挺强大的,可以在交换机内部完成一些简单的操作。
stateful openflow 最大的问题就是需要下发的流表太多,在实际应用场景中会有很大的限制。
上述为转载内容:https://www.jianshu.com/p/4fb7f94895d5
总结:
stateful openflow------整理openstate原理以及具体应用的更多相关文章
- OpenState: Programming Platform-independent Stateful OpenFlow Applications Inside the Switch
文章名称:OpenState: Programming Platform-independent Stateful OpenFlow Applications Inside the Switch Op ...
- hadoop作业调优参数整理及原理
hadoop作业调优参数整理及原理 10/22. 2013 1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并 ...
- hadoop作业调优参数整理及原理(转)
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
- hadoop作业调优参数整理及原理【转】
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
- OpenFlow和SDN的历史和原理介绍
OpenFlow相关的历史.新闻:http://blog.csdn.net/jincm13/article/details/7825754起源与发展[https://36kr.com/p/503598 ...
- crawler_URL编码原理详解
经常写爬虫的童鞋,难免要处理含有中文的url,大部分时间,都知道url_encode,各个语言也都有支持,今天简单整理下原理,供大家科普 1.特征: 如果URL中含有非ASCII字符的话, 浏览器会对 ...
- Linux系统下搭建DNS服务器——DNS原理总结
2017-01-07 整理 DNS原理 域名到IP地址的解析过程 IP地址到域名的反向域名解析过程 抓包分析DNS报文和具体解析过程 DNS服务器搭建和配置 这个东东也是今年博主参见校招的时候被很多公 ...
- [转]SDN与OpenFlow技术简介
http://blog.163.com/s_zhchluo/blog/static/15014708201411144727961/ 本文是2012年文章,对Openflow的发展.规范.应用和SDN ...
- VxLAN原理
VxLAN 背景介绍: 从上个世纪虚拟化技术就被提出,但由于硬件技术达不到,而没能被重视,自本世纪初硬件制造技术越来越来强,导致很多单台物理机只跑一个应用或几个应用根本无法完全使用硬件的全部性能,导致 ...
随机推荐
- Windows安装TensorFlow遇到错误
1.先检查系统是64还是32位的,检查python版本是否相符合 2.windows系统上使用tensorflow需要python3.5版本
- vue-cli打包后,图片路径不对
在config文件夹下的 index.js 里面,查找build,在builid方法里面,添加一行:assetsPublicPath: './' 例: 在build文件夹下的utils.js里面,查找 ...
- 03、 forms组件
1.校验字段功能 1.reg页面准备 models from django.db import models class UserInfo(models.Model): useranme = mode ...
- 应用.NET控制台应用程序开发批量导入程序。
一.最近一直在调整去年以及维护去年开发的项目,好久没有在进行个人的博客了.每天抽了一定的时间在研究一些开源的框架,Drapper 以及NHibernate以及当前比较流行的SqlSuper框架 并进行 ...
- 【Python学习笔记之三】lambda表达式用法小结
除了def语句之外,Python还提供了一种生成函数对象的表达式形式.由于它与LISP语言中的一个工具很相似,所以称为lambda.就像def一样,这个表达式创建了一个之后能够调用的函数,但是它返回了 ...
- 并发系列(三)-----volatile
一 简介 volatile关键字是轻量级的synchronized,volatile在并发编程中保证共享变量的可见性,当一个线程修改被volatile修饰的共享变量时,另外一个线程就能读到这个修改的值 ...
- 使用Fiddler进行Web接口测试
一.Fiddler简介1.为什么是Fiddler?抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark.为什么使用fiddler?原因如下: A)Fir ...
- Java类型转换工具类(十六进制—bytes互转、十进制—十六进制互转,String—Double互转)
/** * 数据类型转换工具类 * @author cyf * */ public class NumConvertUtil{ /** * bytes 转16进制字符串 * @param bArray ...
- Unity3D — — UGUI之RectTransform
Mask.GetComponent<RectTransform>().anchoredPosition(子物体) = hotKey_image.rectTransform.anchored ...
- 一个很NB的404页面
一个带彩蛋的 404 页面 不得不说这个程序猿很有才 前往404页面 触发方法 按住鼠标左键 在页面中心不停的画圈 就可以进入神奇的地方了