HBase编程 API入门系列之modify(管理端而言)(10)
这里,我带领大家,学习更高级的,因为,在开发中,尽量不能去服务器上修改表。
所以,在管理端来修改HBase表。采用线程池的方式(也是生产开发里首推的)
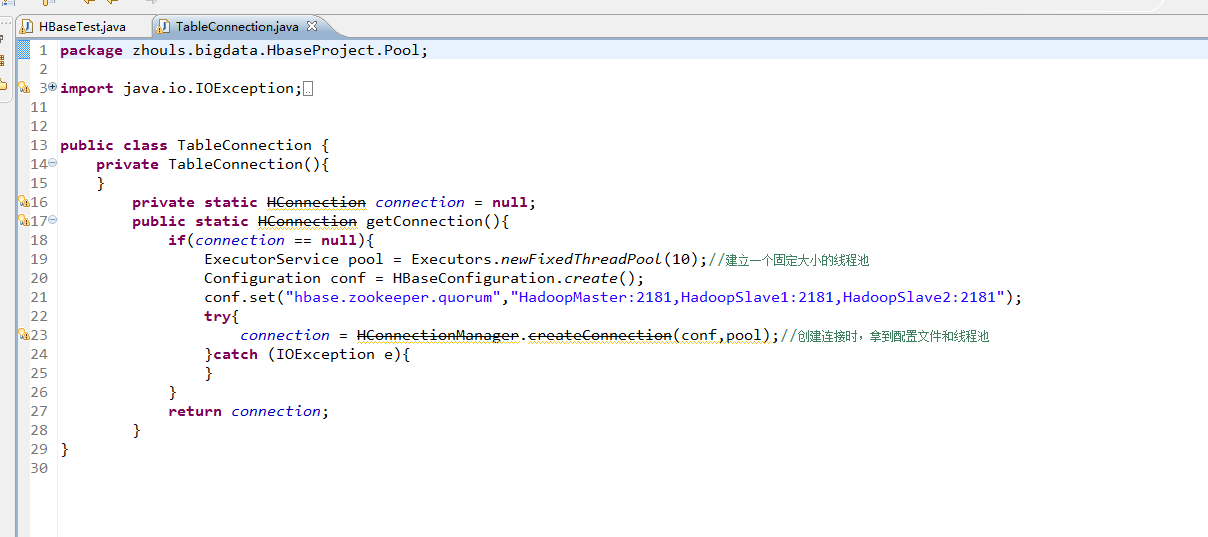
package zhouls.bigdata.HbaseProject.Pool;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
public class TableConnection {
private TableConnection(){
}
private static HConnection connection = null;
public static HConnection getConnection(){
if(connection == null){
ExecutorService pool = Executors.newFixedThreadPool(10);//建立一个固定大小的线程池
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
try{
connection = HConnectionManager.createConnection(conf,pool);//创建连接时,拿到配置文件和线程池
}catch (IOException e){
}
}
return connection;
}
}
1、修改HBase表
暂时,有错误
package zhouls.bigdata.HbaseProject.Pool;
import java.io.IOException;
import zhouls.bigdata.HbaseProject.Pool.TableConnection;
import javax.xml.transform.Result;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseTest {
public static void main(String[] args) throws Exception {
// HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
// Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
// put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
// table.put(put);
// table.close();
// Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close();
// Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
// Delete delete = new Delete(Bytes.toBytes("row_04"));
//// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。
// table.delete(delete);
// table.close();
// Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes("row_01"));//包含开始行键
// scan.setStopRow(Bytes.toBytes("row_03"));//不包含结束行键
// scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// ResultScanner rst = table.getScanner(scan);//整个循环
// System.out.println(rst.toString());
// for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() )
// {
// for(Cell cell:next.rawCells()){//某个row key下的循坏
// System.out.println(next.toString());
// System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell)));
// System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
// System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell)));
// }
// }
// table.close();
HBaseTest hbasetest =new HBaseTest();
// hbasetest.insertValue();
// hbasetest.getValue();
// hbasetest.delete();
// hbasetest.scanValue();
hbasetest.createTable("test_table3", "f");//先判断表是否存在,再来创建HBase表(生产开发首推)
// hbasetest.deleteTable("test_table4");//先判断表是否存在,再来删除HBase表(生产开发首推)
// hbasetest.modifyTable("test_table","row_02","f",'f:age');
}
//生产开发中,建议这样用线程池做
// public void insertValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Put put = new Put(Bytes.toBytes("row_01"));//行键是row_01
// put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0"));
// table.put(put);
// table.close();
// }
//生产开发中,建议这样用线程池做
// public void getValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Get get = new Get(Bytes.toBytes("row_03"));
// get.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close();
// }
//
//生产开发中,建议这样用线程池做
// public void delete() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Delete delete = new Delete(Bytes.toBytes("row_01"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。
//// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。
// table.delete(delete);
// table.close();
//
// }
//生产开发中,建议这样用线程池做
// public void scanValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes("row_02"));//包含开始行键
// scan.setStopRow(Bytes.toBytes("row_04"));//不包含结束行键
// scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// ResultScanner rst = table.getScanner(scan);//整个循环
// System.out.println(rst.toString());
// for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() )
// {
// for(Cell cell:next.rawCells()){//某个row key下的循坏
// System.out.println(next.toString());
// System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell)));
// System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
// System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell)));
// }
// }
// table.close();
// }
//
//生产开发中,建议这样用线程池做
public void createTable(String tableName,String family) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
Configuration conf = HBaseConfiguration.create(getConfig());
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hcd = new HColumnDescriptor(family);
hcd.setMaxVersions(3);
// hcd.set//很多的带创建操作,我这里只抛砖引玉的作用
tableDesc.addFamily(hcd);
if (!admin.tableExists(tableName)){
admin.createTable(tableDesc);
}else{
System.out.println(tableName + "exist");
}
admin.close();
}
public void modifyTable(String tableName,String rowkey,String family,HColumnDescriptor hColumnDescriptor) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
Configuration conf = HBaseConfiguration.create(getConfig());
HBaseAdmin admin = new HBaseAdmin(conf);
// HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hcd = new HColumnDescriptor(family);
// NamespaceDescriptor nsd = admin.getNamespaceDescriptor(tableName);
// nsd.setConfiguration("hbase.namespace.quota.maxregion", "10");
// nsd.setConfiguration("hbase.namespace.quota.maxtables", "10");
if (admin.tableExists(tableName)){
admin.modifyColumn(tableName, hcd);
// admin.modifyTable(tableName, tableDesc);
// admin.modifyNamespace(nsd);
}else{
System.out.println(tableName + "not exist");
}
admin.close();
}
//生产开发中,建议这样用线程池做
// public void deleteTable(String tableName)throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
// Configuration conf = HBaseConfiguration.create(getConfig());
// HBaseAdmin admin = new HBaseAdmin(conf);
// if (admin.tableExists(tableName)){
// admin.disableTable(tableName);
// admin.deleteTable(tableName);
// }else{
// System.out.println(tableName + "not exist");
// }
// admin.close();
// }
public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
HBase编程 API入门系列之modify(管理端而言)(10)的更多相关文章
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
- HBase编程 API入门系列之工具Bytes类(7)
这是从程度开发层面来说,为了方便和提高开发人员. 这个工具Bytes类,有很多很多方法,帮助我们HBase编程开发人员,提高开发. 这里,我只赘述,很常用的! package zhouls.bigda ...
- HBase编程 API入门系列之put(客户端而言)(1)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. [hadoop@HadoopSlave1 conf]$ cat regionservers HadoopMasterHadoopS ...
- HBase编程 API入门系列之scan(客户端而言)(5)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. package zhouls.bigdata.HbaseProject.Test1; import javax.xml.trans ...
- HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. delete.deleteColumn和delete.deleteColumns区别是: deleteColumn是删除某一个列簇 ...
随机推荐
- node.js的querystring模块
querystring主要是用于对字符串进行操作和解析.共有四个方法:querystring.parse,querystring.stringify,querystring.escape,querys ...
- java实现简单窗体小游戏----球球大作战
java实现简单窗体小游戏----球球大作战需求分析1.分析小球的属性: 坐标.大小.颜色.方向.速度 2.抽象类:Ball 设计类:BallMain—创建窗体 BallJPanel—画小 ...
- 【剑指Offer】17、树的子结构
题目描述: 输入两棵二叉树A,B,判断B是不是A的子结构.(ps:我们约定空树不是任意一个树的子结构) 解题思路: 要查找树A中是否存在和树B结构一样的子树,我们可以分为两步:第一步, ...
- Node.js+Protractor+vscode搭建测试环境(1)
1.protractor简介 官网地址:http://www.protractortest.org/ Protractor是一个end-to-end的测试框架,从网络上得到的答案是Protractor ...
- NOIP2016 DAY2 T2蚯蚓
传送门 Description 本题中,我们将用符号[c]表示对c向下取整,例如:[3.0」= [3.1」=[3.9」=3.蛐蛐国最近蚯蚓成灾了!隔壁跳 蚤国的跳蚤也拿蚯蚓们没办法,蛐蛐国王只好去请神 ...
- [luogu2319 HNOI2006] 超级英雄 (匈牙利算法)
传送门 Description 现在电视台有一种节目叫做超级英雄,大概的流程就是每位选手到台上回答主持人的几个问题,然后根据回答问题的多少获得不同数目的奖品或奖金.主持人问题准备了若干道题目,只有当选 ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- PHP多进程初探 --- 利用多进程开发点儿东西吧
[原文地址:https://blog.ti-node.com/blog...] 干巴巴地叨逼叨了这么久,时候表演真正的技术了! 做个高端点儿的玩意吧,加入我们要做一个任务系统,这个系统可以在后台帮我们 ...
- sqlalchemy根据表名动态创建model类
作用如题,直接上代码吧,另外还支持 copy一张表的表结构,新建表并获得model对象 # coding: utf-8 import traceback from sqlalchemy import ...
- 洛谷 P1131 BZOJ 1060 [ZJOI2007]时态同步
题目描述 小Q在电子工艺实习课上学习焊接电路板.一块电路板由若干个元件组成,我们不妨称之为节点,并将其用数字1,2,3….进行标号.电路板的各个节点由若干不相交的导线相连接,且对于电路板的任何两个节点 ...