Tensorflow数据读取机制
展示如何将数据输入到计算图中
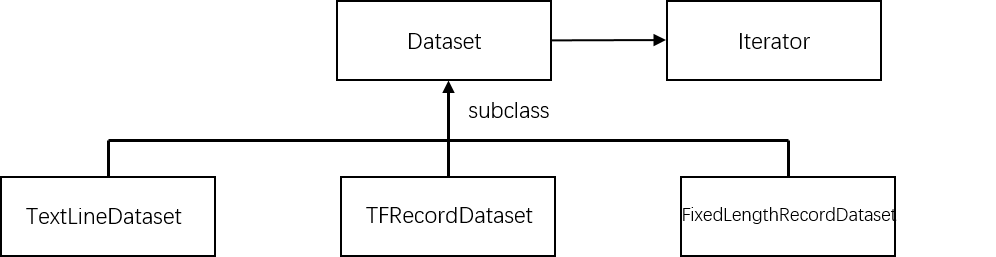
Dataset可以看作是相同类型“元素”的有序列表,在实际使用时,单个元素可以是向量、字符串、图片甚至是tuple或dict。
数据集对象实例化:
dataset=tf.data.Dataset.from_tensor_slice(<data>)
迭代器对象实例化:
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
读取结束异常:如果一个dataset中的元素被读取完毕,再尝试sess.run(one_element)的话,会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据是一致的。
高维数据集的使用
tf.data.Dataset.from_tensor_slices真正作用是切分传入Tensor的第一个维度,生成相应的dataset,即第一维表明数据集中数据的数量,之后切分batch等操作均以第一维为基础。
dataset=tf.data.Dataset.from_tensor_slices(np.random.uniform((5,2)))
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError as e:
print('end~')
输出:
[0.1,0.2]
[0.3,0.2]
[0.1,0.6]
[0.4,0.3]
[0.5,0.2]
tuple组合数据
dataset=tf.data.Dataset.from_tensor_slices((np.array([1.,2.,3.,4.,5.]),
np.random.uniform(size=(5,2))))
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print('end~')
输出:
(1.,array(0.1,0.3))
(2.,array(0.2,0.4))
...
数据集处理方法
Dataset支持一类特殊操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。常用的Transformation:
mapbatchshufflerepeat
其中,
map和python中的map一致,接受一个函数,Dataset中的每个元素都会作为这个函数的输入,并将函数返回值作为新的Datasetdataset=dataset.map(lambda x:x+1)
注意:
map函数可以使用num_parallel_calls参数并行化batch就是将多个元素组成batch。dataset=tf.data.Dataset.from_tensor_slices(
{
'a':np.array([1.,2.,3.,4.,5.]),
'b':np.random.uniform(size=(5,2))
})
###
dataset=dataset.batch(2) # batch_size=2
###
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(one_element)
except tf.errors.OutOfRangeError:
print('end~')
输出:
{'a':array([1.,2.]),'b':array([[1.,2.],[3.,4.]])}
{'a':array([3.,4.]),'b':array([[5.,6.],[7.,8.]])}
shuffle的功能是打乱dataset中的元素,它有个参数buffer_size,表示打乱时使用的buffer的大小,不应设置过小,推荐值1000.dataset=tf.data.Dataset.from_tensor_slices(
{
'a':np.array([1.,2.,3.,4.,5.]),
'b':np.random.uniform(size=(5,2))
})
###
dataset=dataset.shuffle(buffer_size=5)
###
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(one_element)
except tf.errors.OutOfRangeError:
print('end~')
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch。假设原先的数据是一个epoch,使用repeat(2)可以使之变成2个epoch.dataset=tf.data.Dataset.from_tensor_slices({
'a':np.array([1.,2.,3.,4.,5.]),
'b':np.random.uniform(size=(5,2))
})
###
dataset=dataset.repeat(2) # 2epoch
###
# iterator, one_element...
注意:如果直接调用
repeat()函数的话,生成的序列会无限重复下去,没有结果,因此不会抛出tf.errors.OutOfRangeError异常。
模拟读入磁盘图片及其Label示例
def _parse_function(filename,label): # 接受单个元素,转换为目标
img_string=tf.read_file(filename)
img_decoded=tf.image.decode_images(img_string)
img_resized=tf.image.resize_images(image_decoded,[28,28])
return image_resized,label
filenames=tf.constant(['data/img1.jpg','data/img2.jpg',...])
labels=tf.constant([1,3,...])
dataset=tf.data.Dataset.from_tensor_slices((filenames,labels))
dataset=dataset.map(_parse_function) # num_parallel_calls 并行
dataset=dataset.shuffle(buffer_size=1000).batch_size(32).repeat(10)
更多Dataset创建方法
tf.data.TextLineDataset():函数输入一个文件列表,输出一个Dataset。dataset中的每一个元素对应文件中的一行,可以使用该方法读入csv文件。tf.data.FixedLengthRecordDataset():函数输入一个文件列表和record_bytes参数,dataset中每一个元素是文件中固定字节数record_bytes的内容,可用来读取二进制保存的文件,如CIFAR10。tf.data.TFRecordDataset():读取TFRecord文件,dataset中每一个元素是一个TFExample。
更多Iterator创建方法
最简单的创建Iterator方法是通过dataset.make_one_shot_iterator()创建一个iterator。
除了这种iterator之外,还有更复杂的Iterator:
- initializable iterator
- reinitializable iterator
- feedable iterator
其中,initializable iterator方法要在使用前通过sess.run()进行初始化,initializable iterator还可用于读入较大数组。在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中,当array很大时,会导致计算图变得很大,给传输保存带来不便,这时可以使用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样即可避免将大数组保存在图里。
features_placeholder=tf.placeholder(<features.dtype>,<features.shape>)
labels_placeholder=tf.placeholder(<labels.dtype>,<labels.shape>)
dataset=tf.data.Dataset.from_tensor_slices((features_placeholder,labels_placeholder))
iterator=dataset.make_initializable_iterator()
next_element=iterator.get_next()
sess.run(iterator.initializer,feed_dict={features_placeholder:features,labels_placeholder:labels})
Tensorflow内部读取机制
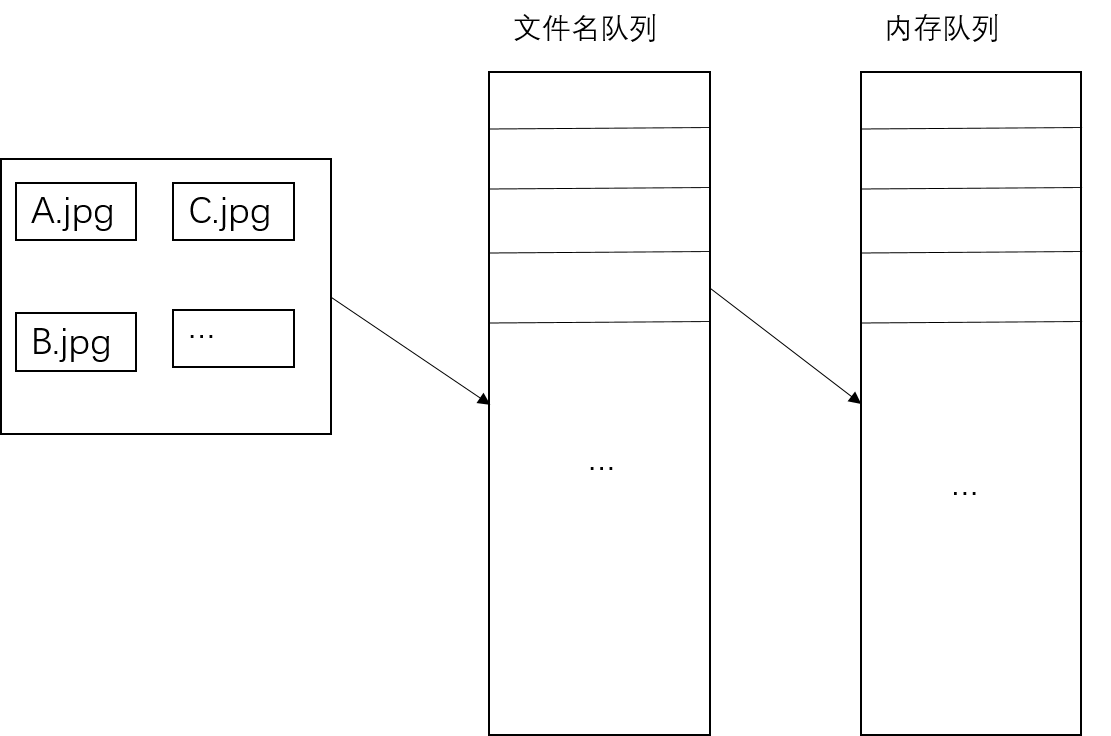
对于文件名队列,使用tf.train.string_input_producer()函数,tf.train.string_input_producer()还有两个重要参数,num_epoches和shuffle
内存队列不需要我们建立,只需要使用reader对象从文件名队列中读取数据即可,使用tf.train.start_queue_runners()函数启动队列,填充两个队列的数据。
with tf.Session() as sess:
filenames=['A.jpg','B.jpg','C.jpg']
filename_queue=tf.train.string_input_producer(filenames,shuffle=True,num_epoch=5)
reader=tf.WholeFileReader()
key,value=reader.read(filename_queue)
# tf.train.string_input_producer()定义了一个epoch变量,需要对其进行初始化
tf.local_variables_initializer().run()
threads=tf.train.start_queue_runners(sess=sess)
i=0
while True:
i+=1
image_data=sess.run(value)
with open('reader/test_%d.jpg'%i,'wb') as f:
f.write(image_data)
Tensorflow数据读取机制的更多相关文章
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630 在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找 ...
- 十图详解tensorflow数据读取机制
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 十图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 【转载】 十图详解tensorflow数据读取机制(附代码)
原文地址: https://zhuanlan.zhihu.com/p/27238630 何之源 深度学习(Deep Learning) 话题的优秀回答者 --------------- ...
- tensorflow数据读取机制tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程 ...
- TensorFlow数据读取
TensorFlow高效读取数据的方法 TF Boys (TensorFlow Boys ) 养成记(二): TensorFlow 数据读取 Tensorflow从文件读取数据 极客学院-数据读取 十 ...
- TensorFlow数据读取方式:Dataset API
英文详细版参考:https://www.cnblogs.com/jins-note/p/10243716.html Dataset API是TensorFlow 1.3版本中引入的一个新的模块,主要服 ...
- 详解Tensorflow数据读取有三种方式(next_batch)
转自:https://blog.csdn.net/lujiandong1/article/details/53376802 Tensorflow数据读取有三种方式: Preloaded data: 预 ...
随机推荐
- UUID不失精度,长度改进
在使用到uuid的时候,往往头疼于它的长度(如1bfe50d8-544e-4e8a-95b8-199ceff15268),于是乎就有了改写uuid的各种方法 1.去除"-"的uui ...
- 【先进的算法】Lasvegas算法3SAT问题(C++实现代码)
转载请注明出处:http://blog.csdn.net/zhoubin1992/article/details/46469557 1.SAT问题描写叙述 命题逻辑中合取范式 (CNF) 的可满足性问 ...
- SystemServer概述
SystemServer由Zygote fork生成的,进程名为system_server,该进程承载着framework的核心服务. 调用流程如下: 上图前4步骤(即颜色为紫色的流程)运行在是Zyg ...
- ice框架应用记录-框架说明
ice框架是一个解决分布式问题的框架,包括应用与管理工具两部分, 应用部分主要包括: 1,注册服务,用来管理所有节点:为了可靠性,一般会开启两个注册服务,一个主注册服务一个从注册服务 2,节点,就是开 ...
- react持续记录零散笔记
根据 React 的设计,所有的 DOM 变动,都先在虚拟 DOM 上发生,然后再将实际发生变动的部分,反映在真实 DOM上,这种算法叫做 DOM diff 这些生命周期在深入项目开发阶段是非常重要的 ...
- mongdb aggregate 聚合数据
最近用到的一些mongodb的数据查询方法 及api用法 Aggregate() 数据聚合处理的方法 可以将聚合的一些方法放在其后面的括号中,也可继续以agg.的样式链式加入 aggregate.al ...
- C#将string转换为十六进制
/// <summary> /// 将string格公式为十六进制数据 /// </summary> /// <param ...
- 第一次react-native项目实践要点总结 good
今天完成了我的第一个react-native项目的封包,当然其间各种环境各种坑,同时,成就感也是满满的.这里总结一下使用react-native的一些入门级重要点(不涉及环境).注意:阅读需要语法基础 ...
- mybatis如何实现分页功能?
1)原始方法,使用limit,需要自己处理分页逻辑: 对于mysql数据库可以使用limit,如: select * from table limit 5,10; --返回6-15行 对于oracle ...
- Python实现多线程下载
#!/usr/bin/python # -*- coding: utf-8 -*- # filename: paxel.py '''It is a multi-thread downloading t ...