java代码从出生到执行的过程浅析
阅读《深入理解java虚拟机 第二版 JVM高级特性与最佳实践》 - jdk版本为1.6
1.什么是编译型语言、解释型语言
-
解释型语言:源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。比如Python/JavaScript / Perl /Shell等都是解释型语言。
编译型语言:程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。像C/C++等都是编译型语言。
java是比较特殊的存在,java从源程序到真正执行需要经历从.java文件到.class文件的编译(前端编译,对应的编译器有javac,eclipse的ECJ),.class文件到二进制机器码的解释执行(后端编译,对应的编译器有JIT);还有一种能够直接把java文件编译成本地机器代码的静态提前编译器(AOT编译器)。
大致的执行路线如下图:
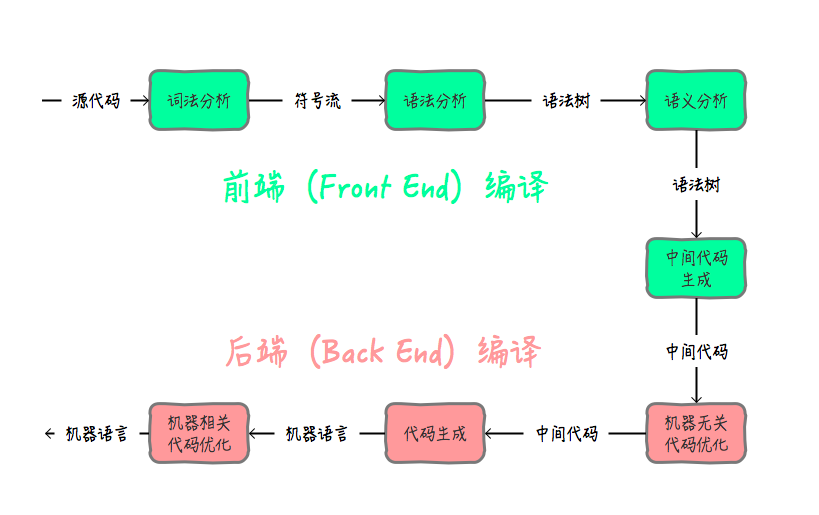
java语言的"编译期"分为前端编译和后端编译两个阶段。前端编译是指把*.java文件转变成*.class文件的过程; 后端编译(JIT, Just In Time Compiler)是指把字节码转变成机器码的过程。
2.Java中的前端编译
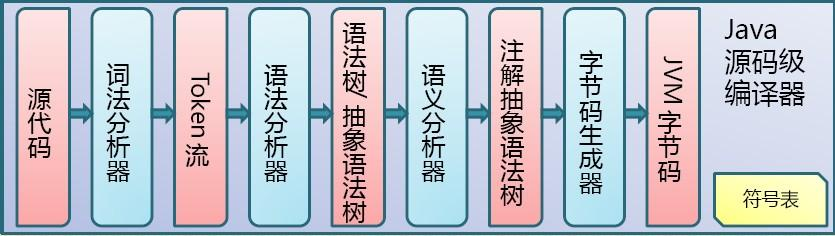
2.1词法分析
先弄懂一个概念:token:计算机科学中将字符序列转换为单词(Token)序列的过程
我们把执行词法分析的函数称为词法分析器。它的主要功能是将源代码的字符流转变为Token集合, Token则是编译过程的最小单位。
规范化的Token包含:
- java关键词:package、import、public、class、int等
- 自定义单词(标识符):包名、类名、变量名、方法名
- 符号:=、;、+、-、*、/、%、{、}等
有一个例子,我们直接拿过来:
package compile;
public class Cifa {
int a;
int c = a + 1;
}
以上代码转化为的Token流:
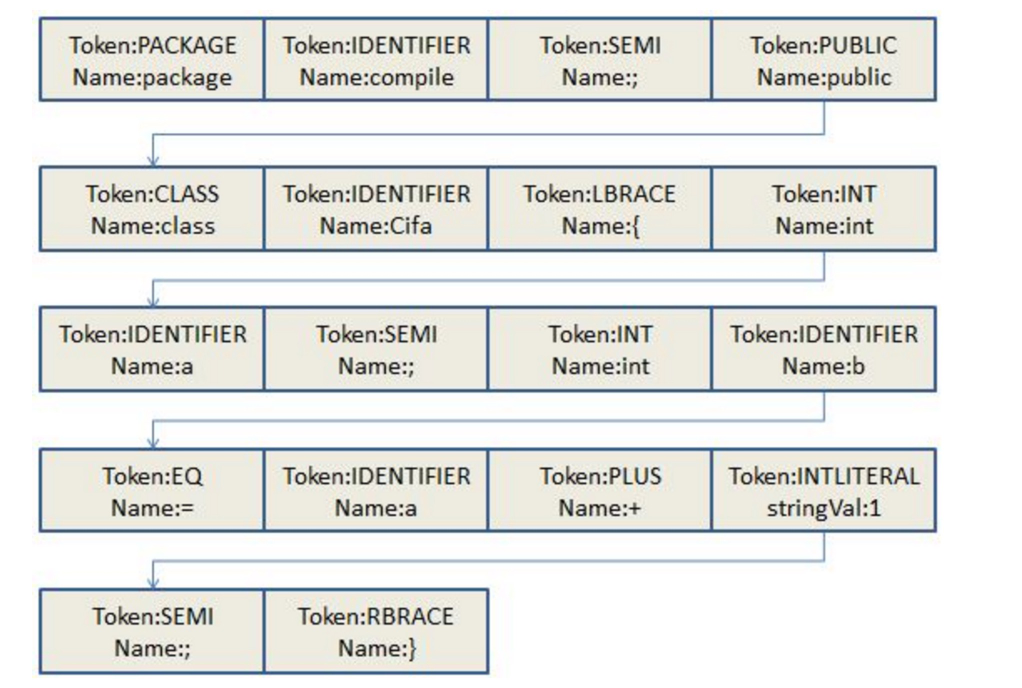
我们可以看到每个token中的数据结构:token的类型及token的具体的值
- Javac是如何分辨出一个个的Token
Javac进行词法分析时会根据java语言规范来控制什么顺序,在什么地方应该出现什么Token(例如对package的读取:在创建javacParsepackage对象的构造函数时,Scanner会读取第一个Token(Token.PACKAGE),而词法分析器的整个过程是在javacParser的parsrCompilationUnit方法中完成的,先判断当前的Token是不是Token.PACKAGE(是的话读取package的定义),接着读取下一个Token(IDENTIFIER),再读取类名时如果遇到Token.Dot也就是‘.’将继续往下读,直到读得完成类名即遇到Token.SEMI(“;”)为止)。由此可以看出,读取哪个Token是由javacParser规定的而Token流的顺序要符合java语言规范。
- Javac如何确认一个Token的
如何确定字符组合是一个Token的规则是在Scanner的nextToken方法中定义的,每调用该方法一次就会构造一个Token,而这些Token必然是com.sun.tools.javac.parser.Token中的任何元素之一。
在读取每个Token时都需要一个转换过程(如在package中的"compile"包名要转化成Token.IDENTIFIER类型),在Java源码中的所有字符集合都要找到在com.sun.tools.javac.parser.Token中定义的对应关系,这个任务是在com.sun.tools.javac.parser.Keywords类中完成的,Keywords负责将所有字符集合对应到Token流中
2.2语法分析
我们得到了token的集合之后,在语法分析器中,将进行词法分析后形成的Token流中的一个个Token组成一句句话,检查这一句句话是不是符合Java语言规范。
1.每个语法节点都会实现一个xxxTree接口,该接口继承自com.sun.source.tree.Tree接口。如IfTree语法节点表示一个if类型表达式
2.每个语法节点都是com.sun.tools.javac.tree.JCTree的子类并且会实现1中提及的接口类,这个类的类名类似于JCxxx类,如实现IfTree接口的实现类为JCIf
3.所有的JCxxx类都作为一个静态内部类定义在JCTree类中
JCTree类中有如下三个重要的属性
1.Tree tag:每个节点都会用一个整形常数表示,并且每个节点的类型的数值是前一个节点的类型数值加1
2.pos:也是一个整数,表示语法节点在源文件中的起始位置,文件的起始位置为0,-1的话表示不存在
3.type:表示这个语法节点是什么类型,如int、float还是String
2.3语法树解析
package解析:JCIdent=>JCFieldAccess
根据Name对象构建了一个JCIdent语法节点,如果是多级目录,将构建JCFieldAccess语法节点,JCFieldAccess语法节点可以是嵌套关系
import解析:JCIdent=>JCFieldAccess=>JCFieldAccess=>JCIdent
当成功解析出package语法节点之后,parseCompilationUnit()这个节点会调用importDeclaration()方法来解析得到import语法树。
importDeclaration()首先检查Token是不是Token.IMPORT,如果是则构造一个语法树,再匹配是不是有static关键字看看是不是静态引入。接着importDeclaration()就会调用语法解析器的Ident()方法解析出一个JCIdent语法节点,如果import语句中包含多级目录的时候,语法解析器就会调用Select()方法解析为嵌套的JCFieldAccess语法节点。
当语法解析器成功解析出JCIdent和JCFieldAccess节点之后,importDeclaration()方法会调用Import()方法,将之前解析的语法节点,整合成为一棵JCImport节点。
实际开发中,通常会有多个import关键字声明,那么importDeclaration()方法内部会通过迭代循环方法解析出多个JCImport语法树,然后将其存储在一个集合中。
class解析:
Import节点解析完之后就是累的解析(interface、class、enum),以class为例
package compile;
public class Yufa {
int a;
private int c=a+1;
public int getC(){
return c;
}
public void setC(int c){
this.c=c;
}
}
第一个Token是Token.CLASS这个类的关键词,接下来是用户定义Token.IDENTIFIER,也是类名。然后是参数,下一个是Token.EXTENDS或者Token.IMPLEMENTS,接着是对classbody的解析,这个classbody解析的结果保存在list集合中,最后将这些子节点添加到JCClassDecl这颗class树中。
这个类解析完成之后,会把这些子树加到顶层语法节点JCCompilationUnit(以package作为pid并且持有JCClassDecl语法节点的集合)之下,完整的语法树如下:

2.3语义分析
作用:将语法树转化为注解语法树
- 添加默认的无参构造器(在没有指定任何有参构造器的情况下)
- 处理注解
- 标注:检查语义合法性、进行逻辑判断
- 检查语法树中的变量类型是否匹配(eg.String s = 1 + 2;//这样"="两端的类型就不匹配)
- 检查变量、方法或者类的访问是否合法(eg.一个类无法访问另一个类的private方法)
- 变量在使用前是否已经声明、是否初始化
- 常量折叠(eg.代码中:String s = "hello" + "world",语义分析后String s = "helloworld")
- 推导泛型方法的参数类型
- 数据流分析
- 变量的确定性赋值(eg.有返回值的方法必须确定有返回值)
- final变量只能赋一次值,在编译的时候再赋值的话会报错
- 所有的检查型异常是否抛出或捕获
- 所有的语句都要被执行到(return后边的语句就不会被执行到,除了finally块儿)
- 进一步语义分析
- 去掉永假代码(eg.if(false))
- 变量自动转换(eg.int和Integer)
- 去掉语法糖(eg.foreach转化为for循环,assert转化为if,内部类解析成一个与外部类相关联的外部类)
- 最后,将经过上述处理的语法树转化为最后的注解语法树
2.4代码生成
作用:将注解语法树转化成字节码,并将字节码写入*.class文件。
- 将java的代码块转化为符合JVM语法的命令形式,这就是字节码
- 按照JVM的文件组织格式将字节码输出到*.class文件中
在生成的*.class文件中不只包含字节码信息,具体包含:
- 结构信息
- class文件格式版本号
- 各部分的数量与大小
- 元数据
- 类、父类、实现接口的声明信息
- 属性声明信息
- 方法声明信息
- 常量池
- 方法信息
- 字节码
- 异常处理器表
- 局部变量区的大小
- 操作数栈的大小
- 操作数栈的类型记录
- 调试用符号信息
java代码从出生到执行的过程浅析的更多相关文章
- java代码的编译、执行过程
Java代码编译是由Java源码编译器来完成,流程图如下所示: Java字节码的执行是由JVM执行引擎来完成,流程图如下所示: Java代码编译和执行的整个过程包含了以下三个重要的机制: Java源码 ...
- Java代码的编译和执行
Java代码编译和执行的整个过程包含了以下三个重要的机制: (1)Java源码编译机制 (2)类加载机制 (3)类执行机制 1.Java代码编译是由Java源码编译器来完成,流程图: Java 源码编 ...
- 用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql
1:创建shell脚本 touch sqoop_options.sh chmod 777 sqoop_options.sh 编辑文件 特地将执行map的个数设置为变量 测试 可以java代码传参数 ...
- 第3节 sqoop:7、通过java代码远程连接linux执行shell命令
数据库的数据同步软件sqoop 数据同步 关系型数据库到大数据平台 任务:sqoop 是批量导入数据太慢,如何做到实时的数据同步 实时的数据同步工具: canal 阿里开源的一个数据库数据实时同步的软 ...
- java代码从键盘输入执行次数,数,然后排序
总结:实现从键盘控制执行次数,困惑我很久,直到昨日在提问时,网友说通过循环是肯定可以的所以顿悟了 package com.c2; import java.util.Arrays; import jav ...
- 编写高质量java代码151个建议
http://blog.csdn.net/aishangyutian12/article/details/52699938 第一章 Java开发中通用的方法和准则 建议1:不要在常量和变量中出现易混 ...
- Notepad++运行JAVA代码
第一种方法: 工具栏->运行 点击后选择运行 1.在运行窗口中输入: cmd /k javac "$(FULL_CURRENT_PATH)" & echo 编译成功 ...
- Java代码执行过程概述
Java代码经历三个阶段:源代码阶段(Source) -> 类加载阶段(ClassLoader) -> 运行时阶段(Runtime) 首先我们来理清一下Java代码整个执行过程, 让我们对 ...
- java代码的初始化过程研究
刚刚在ITeye上看到一篇关于java代码初始化的文章,看到代码我试着推理了下结果,虽然是大学时代学的知识了,没想到还能做对.(看来自己大学时掌握的基础还算不错,(*^__^*) 嘻嘻……)但 ...
随机推荐
- idea离线安装lombok插件
1.查看自己idea版本,2019.1.2,必须安装相同版本的插件 2.从http://plugins.jetbrains.com/plugin/6317-lombok-plugin中下载对应版本的l ...
- codeql初探
CodeQL初探 环境搭建 基于Windows 基于Mac 下载codeql https://github.com/github/codeql-cli-binaries/releases/latest ...
- asp.net中挺高性能的24种方法
那性能问题到底该如何解决?以下是应用系统发布前,作为 .NET 开发人员需要检查的点. 1.debug=「false」 当创建 ASP.NET Web应用程序,默认设置为「true」.开发过程中,设置 ...
- Ubuntu更换python版本
Ubuntu更换python版本 ubuntu服务器自带的python版本是python3.6,在运行jwt包时会有版本问题,所以安装和本地相同的python版本=>python3.7 安装py ...
- [hdu6991]Increasing Subsequence
令$f_{i}$表示以$i$为结尾的极长上升子序列个数,则有$f_{i}=\sum_{j<i,a_{j}<a_{i},\forall j<k<i,a_{k}\not\i ...
- [SVN] Branch and Tag
在 SVN 中,如何建立分支以及如何标记Tag. 右键要处理的文件夹,选择 "TortoiseSVN" - "Branch/tag...",进入下面界面: To ...
- namp相关命令大全
常用功能: -探测主机存活- 扫描端口- 探测主机操作系统信息- 检测漏洞 nmap 常用的几个参数 nmap -v ip 显示详细的扫描过程 nmap -p ip 扫描指定端口 nmap -A ...
- Redis 很屌,不懂使用规范就糟蹋了
这可能是最中肯的 Redis 使用规范了 码哥,昨天我被公司 Leader 批评了. 我在单身红娘婚恋类型互联网公司工作,在双十一推出下单就送女朋友的活动. 谁曾想,凌晨 12 点之后,用户量暴增,出 ...
- Codeforces 1373F - Network Coverage(模拟网络流)
Codeforces 题面传送门 & 洛谷题面传送门 提供一个模拟网络流的题解. 首先我们觉得这题一脸可以流的样子,稍微想想可以想到如下建图模型: 建立源点 \(S,T\) 和上下两排点,不妨 ...
- SSRF的原理和防范
背景 最近做的安全测评主要是SSRF,发现自己在这一块有挺大知识盲点,抓紧补一下. 1.介绍 SSRF(Server-Side Request Forgery:服务器端请求伪造),是一种攻击者利用服务 ...