数据挖掘实战 - 天池新人赛o2o优惠券使用预测
数据挖掘实战 - o2o优惠券使用预测
一、前言
大家好,家人们。今天是2021/12/14号。上次更新是2021/08/29。上篇文章中说到要开两个专题,果不其然我鸽了,这一鸽就是三个多月。今天,我不鸽(还要鸽)。那两个专题关于ResNet和GoogLeNet的文章还等缓缓一缓(一月份一定发),今天这篇文章是关于数据挖掘实战入门的例子,题目及数据集来源于 天池新人实战赛o2o优惠券使用预测,题目地址:https://tianchi.aliyun.com/competition/entrance/231593/introduction?spm=5176.12281973.1005.2.3dd52448rilGd8
二、赛题简介
赛题的主要任务就是,根据提供的数据来分析建模,精准预测用户在2016年7月领取优惠券15以内的使用情况,是否会在规定时间内使用相应优惠券。官网给的数据集主要有:
- ccf_offline_stage1_test_revised.csv : 用户线下优惠券使用预测样本
- cff_offline_stage1_train.zip:用户线下消费和优惠券领取行为
- cff_online_stage1_train.zip:用户线上点击/消费和优惠券领取行为
- sample_submission.csv:提交格式
具体属性特征详情请自行在网站中浏览:https://tianchi.aliyun.com/competition/entrance/231593/information,还有评价指标等这些信息大家自己在天池比赛官网里看一下吧,就不多说了。
三、代码实例
- 导入第三方库以及读入数据
import os, sys, pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import date
from sklearn.linear_model import SGDClassifier, LogisticRegression
import seaborn as sns
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
dfoff = pd.read_csv('./ccf_offline_stage1_train.csv')
dftest = pd.read_csv('./ccf_offline_stage1_test_revised.csv')
dfon = pd.read_csv('./ccf_online_stage1_train.csv')
print('data read end.')
2. 简单观察数据特征
# 简单的观察数据特征
print("dfoff的shape是",dfoff.shape)
print("dftest的shape是",dftest.shape)
print("dfon的shape是",dfon.shape)
print(dfoff.describe())
print(dftest.describe())
print(dfon.describe())
dfoff.head()
3. 用户线下消费和优惠券领取行为以及简单
User_id 用户ID
Merchant_id 商户ID
Coupon_id : null表示无优惠券消费,此时Discount_rate和Date_received字段无意义。"fixed"表示该交易时限时低价活动
Discount_rate 优惠率: \(x\in [0,1]\)代表折扣率; x:y表示满x减y;fixed表示低价限时优惠
Distance :user经常活动的地点离该merchant的最近门店距离时x*500米(如果是连锁店,则取最近的一家门店), \(x\in[0,10]\); null表示无此信息,0表示低于500米,10表示大于5公里
Date_received 领取优惠券时间 消费日期:如果Date=null & Coupon_id != null,该记录表示领取优惠券但没有使用;
Date:消费日期:如果Date=null & Coupon_id != null,该记录表示领取优惠券但没有使用;如果Date!=null & Coupon_id = null,则表示普通消费日期;如果Date!=null & Coupon_id != null,则表示用优惠券消
4. 简单的特征工程及数据处理
将满xx减yy类型(
xx:yy)的券变成优惠率 :\(1 - \frac{yy}{xx}\),同时提取出优惠券相关的三个新的特征discount_rate, discount_man, discount_jian, discount_type将距离
str转为intconvert Discount_rate and Distance补充Null值
def convertRate(row):
# 将满xx减yy变成折扣率
"""Convert discount to rate"""
if pd.isnull(row):
return 1.0
elif ':' in str(row):
rows = row.split(':')
return 1.0 - float(rows[1])/float(rows[0])
else:
return float(row)
# 从discount_rate中提取三个新的特征,把满xx减yy的xx和yy各自作为两个特征,是否有优惠券作为一个特征。
def getDiscountMan(row):
if ':' in str(row):
rows = row.split(':')
return int(rows[0])
else:
return 0
def getDiscountJian(row):
if ':' in str(row):
rows = row.split(':')
return int(rows[1])
else:
return 0
def getDiscountType(row):
# 对优惠率特征进行处理,返回的是空、1(有优惠)、0(没有优惠)
if pd.isnull(row):
return np.nan
elif ':' in row: # 则代表存在折扣
return 1
else:
return 0
def processData(df):
# convert discunt_rate
df['discount_rate'] = df['Discount_rate'].apply(convertRate)
df['discount_man'] = df['Discount_rate'].apply(getDiscountMan)
df['discount_jian'] = df['Discount_rate'].apply(getDiscountJian)
df['discount_type'] = df['Discount_rate'].apply(getDiscountType)
print("处理完后discount_rate的唯一值为:",df['discount_rate'].unique())
# convert distance
# 用-1填充,并转换成int类型
df['distance'] = df['Distance'].fillna(-1).astype(int)
return df
dfoff = processData(dfoff)
dftest = processData(dftest)
print("tool is ok.")
当处理到这里的时候你可以自己尝试去可视化优惠率区间的一个频率直方图。
5. 继续观察Data_received、Data的特征并进行以下处理
# 观察Date_received、Date特征并进行以下处理:
提取出date_received和date的唯一值并进行排序
提出两个新的特征:couponbydate和buybydate
当用户有优惠券时,通过领取优惠券时间分组时每个日期的数量
当用户消费并且领取了优惠券的时候,通过领取优惠券时间分组时每个日期的数量
将其转换为年月日的时间序列
通过转换后的时间序列,提取周一到周日新特征weekday_type
对weekday-type进行one-hot编码
提取标签y,-1表示没有领取优惠券,1表示15天内进行过消费(没有很好的考虑到那些没有优惠券且进行消费的人)
# 对领域优惠券时间的特征进行处理
date_received = dfoff['Date_received'].unique()
date_received = sorted(date_received[pd.notnull(date_received)]) # 提取出非空值的时间,并排序
# 对消费日期的特征进行处理
date_buy = dfoff['Date'].unique()
date_buy = sorted(date_buy[pd.notnull(date_buy)])
date_buy = sorted(dfoff[dfoff['Date'].notnull()]['Date'])
# 当用户有优惠券时,通过领取优惠券时间分组,并计算数量。提取为新的特征。
couponbydate = dfoff[dfoff['Date_received'].notnull()][['Date_received', 'Date']].groupby(['Date_received'], as_index=False).count()
couponbydate.columns = ['Date_received','count']
# 当用户消费并且领取了优惠券的时候,通过领取优惠券时间分组,并计算数量。提取为新的特征。
buybydate = dfoff[(dfoff['Date'].notnull()) & (dfoff['Date_received'].notnull())][['Date_received', 'Date']].groupby(['Date_received'], as_index=False).count()
buybydate.columns = ['Date_received','count']
def getWeekday(row):
# 转换为年月日的时间序列
if row == 'nan':
return np.nan
else:
return date(int(row[0:4]), int(row[4:6]), int(row[6:8])).weekday() + 1
dfoff['weekday'] = dfoff['Date_received'].astype(str).apply(getWeekday)
dftest['weekday'] = dftest['Date_received'].astype(str).apply(getWeekday)
# weekday_type : 周六和周日为1,其他为0
dfoff['weekday_type'] = dfoff['weekday'].apply(lambda x : 1 if x in [6,7] else 0 )
dftest['weekday_type'] = dftest['weekday'].apply(lambda x : 1 if x in [6,7] else 0 )
# 对weekday_type进行one-hot编码
weekdaycols = ['weekday_' + str(i) for i in range(1,8)]
tmpdf = pd.get_dummies(dfoff['weekday'].replace('nan', np.nan)) # one-hot编码
tmpdf.columns = weekdaycols
dfoff[weekdaycols] = tmpdf
tmpdf = pd.get_dummies(dftest['weekday'].replace('nan', np.nan))
tmpdf.columns = weekdaycols
dftest[weekdaycols] = tmpdf
def label(row):
if pd.isnull(row['Date_received']):
return -1
if pd.notnull(row['Date']):
td = pd.to_datetime(row['Date'], format='%Y%m%d') - pd.to_datetime(row['Date_received'], format='%Y%m%d')
if td <= pd.Timedelta(15, 'D'):
return 1
return 0
dfoff['label'] = dfoff.apply(label, axis = 1)
print("end")
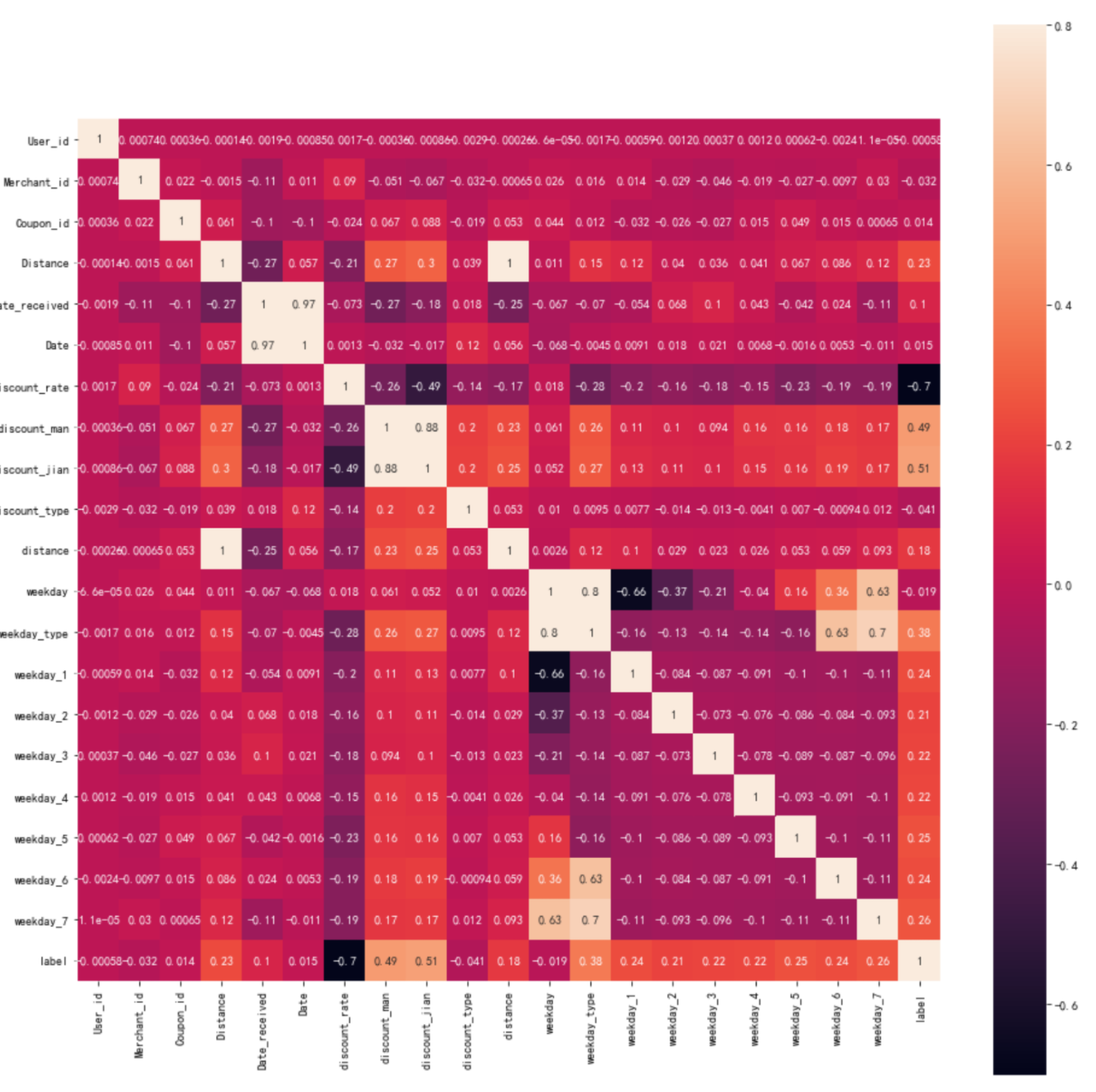
6. 可视化处理后的线下数据的相关系数图
corr = dfoff.corr()
print(corr)
plt.subplots(figsize=(16, 16))
sns.heatmap(corr, vmax=.8, square=True, annot=True)
7. 划分训练集和验证集
# 根据用户领取优惠券的日期划分为 训练集、验证集
print("-----data split------")
df = dfoff[dfoff['label'] != -1].copy()
train = df[(df['Date_received'] < 20160516)].copy()
valid = df[(df['Date_received'] >= 20160516) & (df['Date_received'] <= 20160615)].copy()
print("end")
8. 使用SGD随机梯度下降算法
# feature 使用线性模型SGD方法
model = SGDClassifier(#lambda:
loss='log',
penalty='elasticnet',
fit_intercept=True,
max_iter=100,
shuffle=True,
alpha = 0.01,
l1_ratio = 0.01,
n_jobs=-1,
class_weight=None
)
model.fit(train[original_feature], train['label'])
# #### 预测以及结果评价
print(model.score(valid[original_feature], valid['label']))
print("---save model---")
with open('1_model.pkl', 'wb') as f:
pickle.dump(model, f)
with open('1_model.pkl', 'rb') as f:
model = pickle.load(f)
# 保存要提交的csv文件
y_test_pred = model.predict_proba(dftest[original_feature])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['label'] = y_test_pred[:,1]
dftest1.to_csv('submit1.csv', index=False, header=False)
dftest1.head()
9. 使用500个决策树模型集成,每次从数据集中随机采样100个训练实例
# 使用500个决策树模型集成,每次从数据集中随机采样100个训练实例
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
original_feature = ['discount_rate','discount_type','discount_man', 'discount_jian','distance', 'weekday', 'weekday_type'] + weekdaycols
print("----train-----")
model = BaggingClassifier(
DecisionTreeClassifier(),n_estimators=500,max_samples=100,bootstrap=True,n_jobs=-1
)
model.fit(train[original_feature], train['label'])
# #### 预测以及结果评价
print(model.score(valid[original_feature], valid['label']))
print("---save model---")
with open('1_model.pkl', 'wb') as f:
pickle.dump(model, f)
with open('1_model.pkl', 'rb') as f:
model = pickle.load(f)
# test prediction for submission
y_test_pred = model.predict_proba(dftest[original_feature])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['label'] = y_test_pred[:,1]
dftest1.to_csv('submit2.csv', index=False, header=False)
dftest1.head()
这种算法相比于上个SGD算法,在天池提交上上升了千分之二个点。
10. 以Boosting + 网格搜索为例
# 以Boosting方法
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(
max_depth=2,
n_estimators=100, # 太小容易欠拟合,太大容易过拟合
learning_rate=0.1)
model.fit(train[original_feature], train['label'])
# 使用网格搜索的方法调参,虽然线上的成绩没有太大的上升,但是过拟合的情况得到了很大的改善。
from sklearn.model_selection import GridSearchCV
param_test1 = {'n_estimators':range(20,81,10)}
gsearch1 = GridSearchCV(
estimator = GradientBoostingClassifier(
learning_rate=0.1, min_samples_split=300,
min_samples_leaf=20,
max_depth=8,
max_features='sqrt',
subsample=0.8,
random_state=10),
param_grid = param_test1, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch1.fit(train[original_feature], train['label'])
# gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
print(gsearch1.score(valid[original_feature], valid['label']))
print("---save model---")
with open('1_model.pkl', 'wb') as f:
pickle.dump(gsearch1, f)
with open('1_model.pkl', 'rb') as f:
model = pickle.load(f)
# test prediction for submission
y_test_pred = gsearch1.predict_proba(dftest[original_feature])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['label'] = y_test_pred[:,1]
dftest1.to_csv('submit6.csv', index=False, header=False)
dftest1.head()
4. 总结
本文以天池新人赛o2o优惠券使用预测赛题为题,在对数据探索和分析后,本文主要对Discount_rate、Distance、Data_received、Date特征进行处理,将其转换成模型训练能够使用的数值型数据,并在此基础上提取出了新的特征discount_rate、discount_man、discount_jian、couponbydate、buybydate和weekday-type这些特征,同时我们将weekday-type特征进行one-hot编码,最后我们以是否领取优惠券、是否在15天内进行消费提取标签y的特征为-1和1。
根据实验结果来看,我们在进行特征提取后,从一开始的SGD模型、Bagging模型所出现的过拟合情况,到Boosting模型+网格搜索极大的缓解了模型的过拟合情况,说明较为适合的还是Boosting模型,它能够很好的利用分类器的残差来作为新的训练集,进而实现更优的模型。(当然我觉得SGD一定也是可以的,不过得调整一些参数,本次实验中对于SGD的使用太简陋了)
同时,由于处理时间较为仓促,我们的模型还有很多能够提高的地方。首先是特征处理方面,我们还可以使用聚类或者主成分分析的方法判断各个特征的相关性,将相关性较大的特征进行降维,同时我们还可以深层次的去探索特征关系,进行特征工程的建立。比如我们可以结合用户线上、线下的相关特征以及用户-商家的交互特征等。除此之外,我们在训练集上label的选择也是有待完善的,我们只是单独考虑了没有优惠券的为-1,15天购买的为1,并没有考虑到没有又回去但是15天内购买的情况以及其它复杂情况。
进一步的,在选择特征的时候,根据天池某位大佬的思路,我们可以考虑使用过拟合训练的方法,使用100%数据集训练,使用100%数据集测试,观察auc,当auc距离1越远的时候,说明特征不够多,继续探索更多的特征,直到这里的auc接近1,在过拟合训练完成后输出特征重要性,删除特征重要性低的特征,不断过拟合训练,保持auc基本不变,最后得到是尽可能少的特征数量但是又能够表示这批数据的特性。
对于数据集的划分,此次实验中也做的很简洁,只是单纯的根据时间顺序划分为两个数据集,而这样划分数据集的劣势很大(但是由于时间仓促,这样最简单)。如果这段时间内外界环境有较大波动则很可能对数据集样本的正负性产生极大的影响。后期会尝试在一开始的数据集划分时就采用交叉验证,而不仅仅是在模型训练时采用交叉验证,这样可能充分利用数据集的所有讯息,提高模型的泛化能力。
在模型建立方面后期也应该更多的去尝试Xgboost集成模型。集成模型的“三个臭皮匠顶个诸葛亮”的理念是十分成功的,很多上分成功的大佬也是用到了Xgboost模型的方法。同时我将进一步使用网格搜索的方法,每次网格搜索都将根据上一次搜索出的结果来缩小范围,最后确定最优的参数。
Anyway,整篇文章的定位是小白入门级,大致了解一下数据处理与清洗、特征工程啊、模型训练以及非常NB的集成学习。如果你想在这个比赛里刷更高的分数,建议去天池论坛里找一下其它大佬分享的文章~
数据集、代码我把它放到了网盘里,大家有需要可以自提:链接:https://pan.baidu.com/s/1CZB8fErDygtdFc5TWvIk9w 提取码:er1b
数据挖掘实战 - 天池新人赛o2o优惠券使用预测的更多相关文章
- 天池新人赛-天池新人实战赛o2o优惠券使用预测(一)
第一次参加天池新人赛,主要目的还是想考察下自己对机器学习上的成果,以及系统化的实现一下所学的东西.看看自己的掌握度如何,能否顺利的完成一个分析工作.为之后的学习奠定基础. 这次成绩并不好,只是把整个机 ...
- 2016天池-O2O优惠券使用预测竞赛总结
第一次参加数据预测竞赛,发现还是挺有意思的.本文中的部分内容参考第一名“诗人都藏在水底”的解决方案. 从数据划分.特征提取.模型设计.模型融合/优化,整个业务流程得到了训练.作为新手在数据划分和模型训 ...
- o2o优惠券使用预测
前沿: 这是天池的一个新人实战塞题目,原址 https://tianchi.aliyun.com/getStart/information.htm?spm=5176.100067.5678.2.e13 ...
- 《阿里云天池大赛赛题解析》——O2O优惠卷预测
赛事链接:https://tianchi.aliyun.com/competition/entrance/231593/introduction?spm=5176.12281925.0.0.7e157 ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
- 数据挖掘实战<1>:数据质量检查
数据行业有一句很经典的话--"垃圾进,垃圾出"(Garbage in, Garbage out, GIGO),意思就是,如果使用的基础数据有问题,那基于这些数据得到的任何产出都是没 ...
- SAS数据挖掘实战篇【五】
SAS数据挖掘实战篇[五] SAS--预测模型 6.1 测模型介绍 预测型(Prediction)是指由历史的和当前的数据产生的并能推测未来数据趋势的知识.这类知识可以被认为是以时 间为关键属性的关联 ...
- SAS数据挖掘实战篇【四】
SAS数据挖掘实战篇[四] 今天主要是介绍一下SAS的聚类案例,希望大家都动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得. 1 聚类分析介绍 1.1 基本概念 聚类就是一种寻找数据之 ...
- SAS数据挖掘实战篇【三】
SAS数据挖掘实战篇[三] 从数据挖掘概念到SAS EM模块和大概的流程介绍完之后,下面的规划是[SAS关联规则案例][SAS聚类][SAS预测]三个案例的具体操作步骤,[SAS的可视化技术]和[SA ...
随机推荐
- Python 循环控制
for循环 Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串 for 变量 in 列表.字典.字符串.函数: 执行语句 ...
- 基于Netty4手把手实现一个带注册中心和注解的Dubbo框架
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. 1. 详细剖析分布式微服务架构下网络通信的底层实现原理(图解) 2. (年薪60W的技巧)工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- 交叉编译环境的linaro-gdb可以用了,结果打开core文件,显示堆栈都是??
交叉编译环境的linaro-gdb可以用了,结果打开core文件,显示堆栈都是?? aarch64-linux-gun-gdb ./test core warning: /lib/libpthread ...
- vagrant创建centos7后虚拟机磁盘爆满
1.问题现象 使用df -h命令,磁盘占用直接99%,明明啥也没干... 2.解决方案 找到C:\Users\你的用户名\.vagrant.d\boxes\centos7\0\virtualbox目 ...
- 【JavaSE】Java基础·疑难点汇集
Java基础·疑难点 2019-08-03 19:51:39 by冲冲 1. 部分Java关键字 instanceof:用来测试一个对象是否是指定类型的实例. native:用来声明一个方法是由与 ...
- python中else的三种用法
与if搭配 要么--不然-- num = input("输入一个数字") if(num % 2 == 0): print("偶数") else: print(& ...
- c++基础知识02
1.前置与后置区别 #include<iostream> using namespace std; int main() { //前置和后置区别 //前置递增或递减 先让变量加减1 然后进 ...
- R语言与医学统计图形【2】散点图、盒形图
R语言基础绘图系统 基础图形--散点图.盒形图 plot是一个泛型函数(generic method),对于不同的数据绘制不同的图形. par函数的大部分参数在plot中通用. 1.散点图 plot绘 ...
- C语言 fastq文件转换为fasta文件
目前只能处理短序列,若要处理长序列,可按照https://www.cnblogs.com/mmtinfo/p/13036039.html的读取方法. 1 #include <stdio.h> ...
- Django创建多对多表关系的三种方式
方式一:全自动(不推荐) 优点:django orm会自动创建第三张表 缺点:只会创建两个表的关系字段,不会再额外添加字段,可扩展性差 class Book(models.Model): # ... ...