保留重复项(Power Query 之 M 语言)
数据源:
“姓名”“基数”“个人比例”“个人缴纳”“公司比例”“公司缴纳”“总计”,共7列7行数据,其中姓名列,第1、2行与第6、7行内容重复
目标:
留下第1、2、6、7姓名列中内容重复的行
操作过程:
选取指定列》【主页】》【保留行】》【保留重复项】
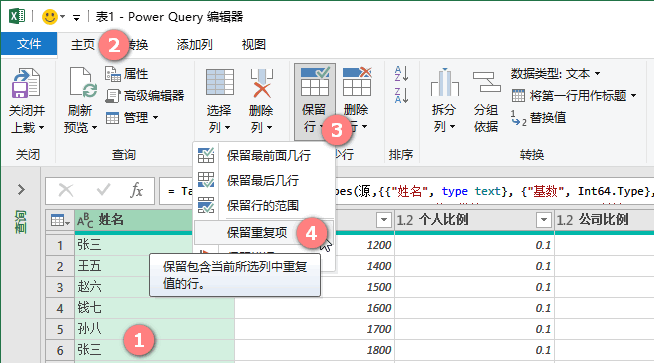
M公式:
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
说明:
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 给指定的列名一个说法,叫作“columnNames”
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【分组依据】计算指定列里各个值出现次数,并将这结果命名为addCount
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【保留行】保留“Count”列中值大于1的行
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【删除列】将“Count”列删除
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 将原表和只保留重复值的表进行【合并查询】,连接种类使用“内部”
将所有步骤拆分如图所示。
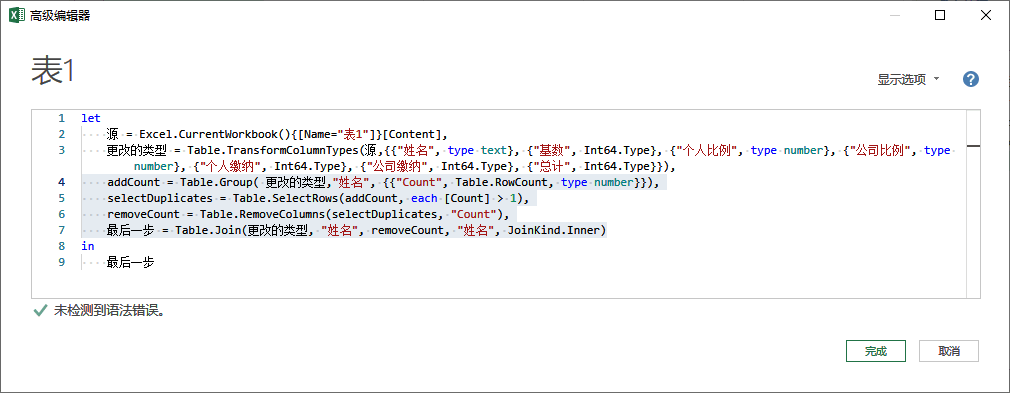
其中核心部分:
addCount = Table.Group( 更改的类型,"姓名", {{"Count", Table.RowCount, type number}}),
selectDuplicates = Table.SelectRows(addCount, each [Count] > 1),
removeCount = Table.RemoveColumns(selectDuplicates, "Count"),
最后一步 = Table.Join(更改的类型, "姓名", removeCount, "姓名", JoinKind.Inner)
最终效果:
数据只剩下姓名列中重复的四行数据
多说一句:
好吧,我承认,我被这个公式惊到了!这其实已经不是一个简单的公式,而是一段M代码,这不是有let开头,in结尾么……
保留重复项(Power Query 之 M 语言)的更多相关文章
- M函数目录(Power Query 之 M 语言)
2021-12-11更新 主页(选项卡) 管理列(组) 选择列 选择列Table.SelectColumns 删除列 删除列Table.RemoveColumns 删除其他列Table.SelectC ...
- Table.Range保留中间指定的….Range/Middle(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.FirstN保留前面N….First…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.LastN保留后面N….Last…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.Distinct取唯/众数….Distinct/Mode/判断…IsDistinct(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- M语言的写、改、删(Power Query 之 M 语言)
M语言基本上和其他语言一样,用敲键盘的方式写入.修改.删除,这个是废话. M语言可以在[编辑栏]或[高级编辑器]里直接写入.修改.删除,这个也是废话. M语言还有个地方可以写入.修改.删除,就是[自定 ...
- M语言的藏身之地(Power Query 之 M 语言)
M函数和M公式是Power Query专用的函数与公式,M代码是Power Query专用的用于实现查询功能的代码.M函数公式和M代码统称M语言. 查看M公式:[编辑栏] 查看方法:在Power Qu ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- Table.AlternateRows删除间隔….Alternate…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
随机推荐
- MySQL数据库从入门到放弃(目录)
目录 MySQL数据库从入门到放弃 推荐阅读 MySQL数据库从入门到放弃 193 数据库基础 194 初识MySQL 195 Windows安装MySQL 196 Linux安装MySQL 197 ...
- 【程序员翻身计划】Java高性能编程第一章-Java多线程概述
目标 重点: 线程安全的概念 线程通信的方式与应用 reactor线程模型 线程数量的优化 jdk常用命令 Netty框架的作用 难点 java运行的原理 同步关键字的原理 AQS的抽象 JUC的源码 ...
- linux命令-压缩数据
linux文件压缩工具:bzip2 文件扩展名 .bz2 compress 文件扩展名 .Z linux上很少看到了 uncompress解压 gzip 文件扩展名,.gz,gzip压缩文件,gzca ...
- myeclipse激活、破解教程
myeclipse安装注意事项 首先要下载jdk 配置jdk的环境变量 如果1和2 都打不开说明没有下载jdk文件,点击下载就可以了,点击1的时候会出现要求下载的界面,直接下载就可以了...下载完成之 ...
- C/C++ Qt Tree与Tab组件实现分页菜单
虽然TreeWidget组件可以实现多节点的增删改查,但多节点操作显然很麻烦,在一般的应用场景中基本上只使用一层结构即可解决大部分开发问题,TreeWidget组件通常可配合TabWidget组件,实 ...
- wget 命令用法
wget 命令用法 1. 用法/命令格式 wget [OPTION]... [URL]... wget [参数列表] [目标软件.网页的网址] 长选项所必须的参数在使用短选项时也是必须的 2. 常用参 ...
- 【GS文献】测序时代植物复杂性状育种之基因组选择
综述:Genomic Selection in the Era of Next Generation Sequencing for Complex Traits in Plant Breeding 要 ...
- R语言与医学统计图形-【24】ggplot位置调整函数
ggplot2绘图系统--位置调整函数 可以参数position来调整,也有专门的函数position_*系列来设置. 位置函数汇总: 1.排列 并排排列 mean <- runif(12,1, ...
- python20判断变量是否存在
python中检测某个变量是否有定义 第一种方法使用内置函数locals(): locals():获取已定义对象字典 'testvar' in locals().keys() 第二种方法使用内置函数d ...
- linux安全性增加
账户安全问题 Linux 默认会安装很多不必要的用户和用户组,如果不需要某些用户或者组,就要立即删除它,因为账户越多,系统就越不安全,很可能被黑客利用,进而威胁到服务器的安全. Linux系统中可以 ...