pytorch实现LeNet5分类CIFAR10
关于LeNet-5
LeNet5的Pytorch实现在网络上已经有很多了,这里记录一下自己的实现方法。
LeNet-5出自于Gradient-Based Learning Applied to Document Recognition中,被用于手写数字识别,也是首批在图像识别中运用了卷积的网络。LeNet-5的网络结果如下:
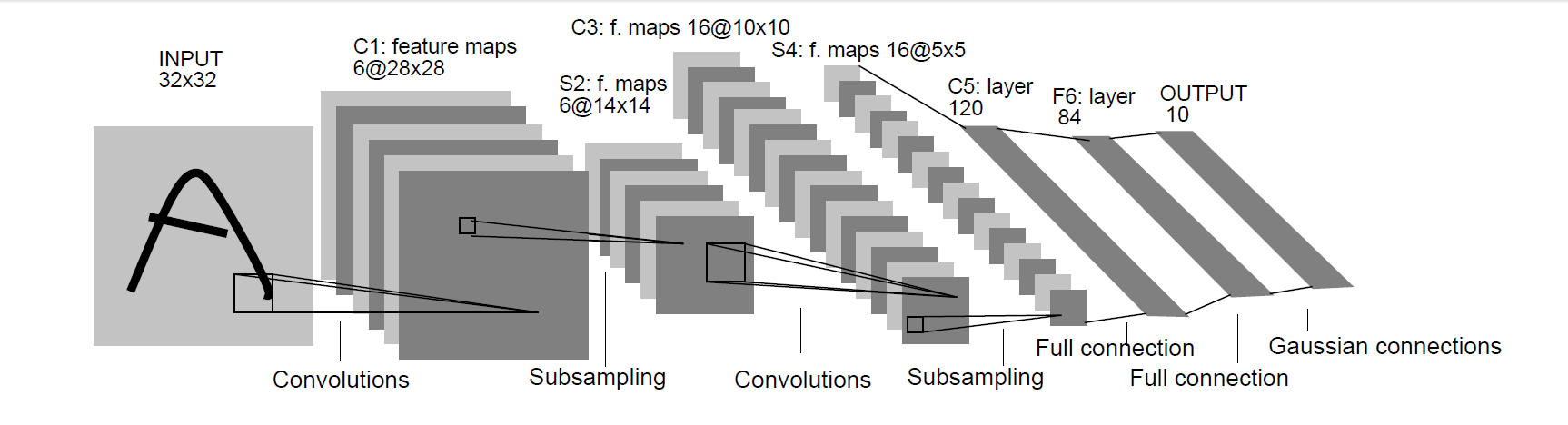
从这个网络结构图中可以看出,网络首先经过了卷积、池化、卷积、池化、全连接、全连接。接下来对这些层做一些解释。
网络结构
第一次卷积
LeNet-5的第一次卷积采用了5*5的卷积核,卷积的filters为6,步长为1,padding为0,经过这样的一次卷积,32*32*3的输入图片就变成了28*28*6的特征图(feature map),这里长、宽和通道的变化可以由卷积的各项参数得到,如28=(32-5+1)/1,通道3变成6是因为卷积的filters数为6
第一次池化
在经过第一次卷积之后,这里经过了一次池化的操作,特征图的长宽减半,通道数不变,这样特征图的尺寸就变成了14*14*6,池化的目的是为了减小特征图的大小,减少计算量
第二次卷积
第二次卷积同样采用了5*5的卷积核,卷积的filters数为16,步长为1,padding为0,经过该卷积层的特征图变为了10*10*16
第二次池化
这里需要经过一层的池化,同样图的长宽减半,变为了5*5*16
第一次全连接
全连接层是将一张图片的所有的像素都连接起来,我们从上面得知,上层卷积得到的特征图为5*5*16,就可以算出一共有5*5*16=400个像素,则输入为400个特征,根据论文的定义,该全连接层输出120个特征
第二次全连接
同上,该层输入了120个特征,输出了84个特征
第三次全连接
该层输入了84个特征,输出了10个特征,对应了CIFAR10数据集需要分10类
网络的pytorch代码如下:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 第一层卷积
self.conv_1 = nn.Conv2d(3, 6, (5, 5), stride=1, padding=0)
# 第二层池化
self.pool_1 = nn.AvgPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 第三层卷积
self.conv_2 = nn.Conv2d(6, 16, (5, 5), stride=1, padding=0)
# 第四层池化
self.pool_2 = nn.AvgPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 第七层全连接
self.linear_1 = nn.Linear(16 * 8 * 8, 120)
# 第八层全连接
self.linear_2 = nn.Linear(120, 84)
# 第九层全连接
self.linear_3 = nn.Linear(84, 10)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
def forward(self, x):
x_c1 = self.relu(self.conv_1(x))
x_p1 = self.pool_1(x_c1)
x_c2 = self.relu(self.conv_2(x_p1))
x_p2 = self.pool_2(x_c2)
x_c3 = x_p2.view(x_p2.size(0), -1)
x_l1 = self.relu(self.linear_1(x_c3))
x_l2 = self.relu(self.linear_2(x_l1))
x_l3 = self.linear_3(x_l2)
return x_l3
数据集
LeNet-5当初设计出来是为了分类手写数据集,所以理论上MINST手写数据集会更加的适合它,但是这里我还是选择了CIFAR10数据集来测试LeNet-5网络。
CIFAR10数据集可以在pytorch中很方便的调用,但是处于练习pytorch的目的,这里手动下载了CIFAR10数据集,然后手写了读取数据集的相关类。
CIFAR10数据集可以在其官网下载,链接如下:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
大家下载后,并不是一个个的图片,而是一个二进制的文件,图片的数据就包含在其中,需要利用相关的代码将这个二进制的文件转为图片文件。下面放出相关的代码:
# -*- coding: utf-8 -*-
import imageio
import numpy as np
import pickle
import os
if not os.path.exists("./cifar10/train"):
os.makedirs("./cifar10/train")
if not os.path.exists("./cifar10/test"):
os.makedirs("./cifar10/test")
def load_file(filename):
with open(filename, 'rb') as f:
data = pickle.load(f, encoding='latin1')
return data
# 生成训练集图片,如果需要png格式,只需要改图片后缀名即可。
for j in range(1, 6):
dataName = "data_batch_" + str(j) # 读取当前目录下的data_batch12345文件,dataName其实也是data_batch文件的路径,本文和脚本文件在同一目录下。
Xtr = load_file('./cifar10/'+dataName)
print(dataName + " is loading...")
for i in range(0, 10000):
img = np.reshape(Xtr['data'][i], (3, 32, 32)) # Xtr['data']为图片二进制数据
img = img.transpose(1, 2, 0) # 读取image
picName = './cifar10/train/' + str(Xtr['labels'][i]) + '_' + str(i + (j - 1)*10000) + '.jpg' # Xtr['labels']为图片的标签,值范围0-9,本文中,train文件夹需要存在,并与脚本文件在同一目录下。
imageio.imwrite(picName, img)
print(dataName + " loaded.")
print("test_batch is loading...")
# 生成测试集图片
testXtr = load_file('./cifar10/test_batch')
for i in range(0, 10000):
img = np.reshape(testXtr['data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
picName = './cifar10/test/' + str(testXtr['labels'][i]) + '_' + str(i) + '.jpg'
imageio.imwrite(picName, img)
print("test_batch loaded.")
运行上面的代码后,大家就可以得到train和test两个文件夹的图片,其类别是通过文件名来判断的。
根据该CIFAR10数据集,就可以写出读取数据集的相关类了,代码如下:
class Cifar10Dataset(Dataset):
def __init__(self, img_path, transform=None, target_transform=None):
self.imgs = []
img_list = os.listdir(img_path)
for i in img_list:
label = i.split('_')[0]
self.imgs.append({'label': label, "img": os.path.join(img_path, i)})
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
data = self.imgs[index]
# label = [0.0]*10
# label[int(data['label'])] = 1.0
label = float(data['label'])
img_path = data['img']
img = Image.open(img_path).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return label, img
def __len__(self):
return len(self.imgs)
其中__getitem__和__len__是继承自Dataset类,分别用于获取一个数据和获取数据集的长度。
定义了Dataset接下来就可以定义dataloader了,定义如下:
cifar_train = dataset.Cifar10Dataset('./cifar10/train', transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
cifar_test = dataset.Cifar10Dataset('./cifar10/test', transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
cifar_train_loader = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test_loader = DataLoader(cifar_test, batch_size=batch_size, shuffle=False)
其中的transform为将提取出的图片做何种处理,在本段代码中,进行了调整大小、转为Tensor变量和归一化的处理,这里要注意,归一化需要在tensor之后。
训练
接下来就编写train的代码,直接将代码放出
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.optim as optim
from tensorboardX import SummaryWriter
import dataset
from model import LeNet
from torch.optim.lr_scheduler import StepLR
write = SummaryWriter('result')
batch_size = 71680
epoch_num = 200
cifar_train = dataset.Cifar10Dataset('./cifar10/train', transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
cifar_test = dataset.Cifar10Dataset('./cifar10/test', transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
cifar_train_loader = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test_loader = DataLoader(cifar_test, batch_size=batch_size, shuffle=False)
# label, img = iter(cifar_train_loader).next()
criteon=nn.CrossEntropyLoss()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# print(device)
net=LeNet().to(device)
# write.add_graph(net)
optimizer=optim.Adam(net.parameters(), lr=1e-2)
scheduler = StepLR(optimizer, step_size=100, gamma=0.1)
# print(net)
for epoch in range(epoch_num):
for batchidx, (label, img) in enumerate(cifar_train_loader):
net.train()
logits = net(img.to(device))
loss = criteon(logits, label.long().to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
print("epoch:{} loss:{}".format(epoch, loss.item()))
write.add_scalar(tag='train_loss', global_step=epoch, scalar_value=loss.item())
net.eval()
with torch.no_grad():
total_num = 0
total_correct = 0
for label, img in cifar_test_loader:
logits = net(img.to(device))
pred = logits.argmax(dim=1)
total_correct += torch.eq(label.to(device), pred).float().sum()
total_num += img.size(0)
acc = total_correct / total_num
print("EVAL--epoch:{} acc:{} Lr:{}".format(epoch, acc, optimizer.state_dict()['param_groups'][0]['lr']))
write.add_scalar(tag="eval_acc", global_step=epoch, scalar_value=acc)
write.add_scalar(tag="Learning Rate", global_step=epoch, scalar_value=optimizer.state_dict()['param_groups'][0]['lr'])
在train的时候,你需要更改你自己电脑的显卡水平来调整batch_size的大小,运行即可开始训练。
详细的代码可以在我的github仓库看到
文章若有错误,欢迎联系我或在评论中指出
pytorch实现LeNet5分类CIFAR10的更多相关文章
- 用KNN算法分类CIFAR-10图片数据
KNN分类CIFAR-10,并且做Cross Validation,CIDAR-10数据库数据如下: knn.py : 主要的试验流程 from cs231n.data_utils import lo ...
- pytorch解决鸢尾花分类
半年前用numpy写了个鸢尾花分类200行..每一步计算都是手写的 python构建bp神经网络_鸢尾花分类 现在用pytorch简单写一遍,pytorch语法解释请看上一篇pytorch搭建简单网 ...
- 用Pytorch训练MNIST分类模型
本次分类问题使用的数据集是MNIST,每个图像的大小为\(28*28\). 编写代码的步骤如下 载入数据集,分别为训练集和测试集 让数据集可以迭代 定义模型,定义损失函数,训练模型 代码 import ...
- pytorch -- CNN 文本分类 -- 《 Convolutional Neural Networks for Sentence Classification》
论文 < Convolutional Neural Networks for Sentence Classification>通过CNN实现了文本分类. 论文地址: 666666 模型图 ...
- pytorch 文本情感分类和命名实体识别NER中LSTM输出的区别
文本情感分类: 文本情感分类采用LSTM的最后一层输出 比如双层的LSTM,使用正向的最后一层和反向的最后一层进行拼接 def forward(self,input): ''' :param inpu ...
- pytorch 5 classification 分类
import torch from torch.autograd import Variable import torch.nn.functional as F import matplotlib.p ...
- pytorch LSTM情感分类全部代码
先运行main.py进行文本序列化,再train.py模型训练 dataset.py from torch.utils.data import DataLoader,Dataset import to ...
- PyTorch实战:经典模型LeNet5实现手写体识别
在上一篇博客CNN核心概念理解中,我们以LeNet为例介绍了CNN的重要概念.在这篇博客中,我们将利用著名深度学习框架PyTorch实现LeNet5,并且利用它实现手写体字母的识别.训练数据采用经典的 ...
- TF Boys (TensorFlow Boys ) 养成记(四):TensorFlow 简易 CIFAR10 分类网络
前面基本上把 TensorFlow 的在图像处理上的基础知识介绍完了,下面我们就用 TensorFlow 来搭建一个分类 cifar10 的神经网络. 首先准备数据: cifar10 的数据集共有 6 ...
随机推荐
- Centos7安装nexus(maven私服)以及maven的相关配置
一.nexus安装: 1.获取nexus下载地址: 查询nexus最新版本地址:https://help.sonatype.com/repomanager3/download 当前最新版本为nexus ...
- 人多力量大vs.两个披萨原则,聊聊持续交付中的流水线模式
人多力量大vs.两个披萨原则,聊聊持续交付中的流水线模式 在前面5期文章中,我们分别详细介绍了持续交付体系基础层面的建设,主要是多环境和配置管理,这些是持续交付自动化体系的基础,是跟我们实际的业务场景 ...
- 【Papers】Robust Lane Detection via Expanded Self Attention 论文解读
论文题目:Robust Lane Detection via Expanded Self Attention 链接地址:https://arxiv.org/abs/2102.07037 文章核心想要解 ...
- day-06-集合-缓存机制-深浅copy
(1) is id ==用法 is 判断的是内存地址是否相同 id 查看内存地址:id相同,值一定相同,值相同,id不一定相同 == 比较判断是否相等 l1 = [1, 2, 3] l2 = [1, ...
- Windows上Docker Toolbox修改镜像源
https://blog.csdn.net/weixin_36242811/article/details/90515835
- 如何获取canvas当前的缩放值
项目中一直有一个问题困扰着我,我们的画布可以缩放平移旋转,支持拖拽生成图形,生成手写笔迹,如果用户选择的线条粗细为5像素,那么即使画布缩放过绘制出的线条粗细也应该是视觉上的5px,所以再绘制时赋值给c ...
- Java 时间日期系列
Java Calendar,Date,DateFormat,TimeZone,Locale等时间相关内容的认知和使用(1) Calendar Java Calendar,Date,DateFormat ...
- NLP入门学习中关于分词库HanLP导入使用教程
大家好,时隔多年再次打开我的博客园写下自己的经验和学习总结,开园三年多,文章数少得可怜,一方面自己技术水平局限,另一方面是自己确实想放弃写博客.由于毕业工作的原因,经常性的加班以及仅剩下少的可怜的休息 ...
- 浅谈 Fresco 框架结构
在前面的文章 Fresco 源码分析 -- 图片加载流程 里面详细说明了图片加载的整个流程,但是除了理解源码之外,对于源码的框架层面的设计也是需要去了解的,不能只是简单的读源码,好的源码的框架设计也是 ...
- Ambassador-05-自动重试
自动重试定义: retry_policy: retry_on: <string> num_retries: <integer> per_try_timeout: <str ...